НЛП | Разделение и объединение кусков
Класс SplitRule: для этой цели он разбивает фрагмент на основе указанного шаблона разделения. Он указывается как <NN. *>} {<. *> Т.е. две противоположные фигурные скобки, окруженные узором с обеих сторон.
Класс MergeRule: он объединяет два фрагмента вместе на основе окончания первого фрагмента и начала второго фрагмента. Он указывается как <NN. *> {} <. *> Т.е. фигурные скобки обращены друг к другу.
Пример выполнения шагов
- Начиная с дерева предложений .

- Полное предложение .
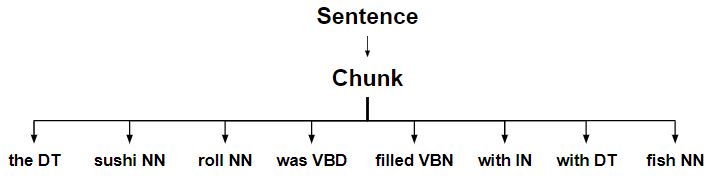
- Чанки делятся на несколько кусков .
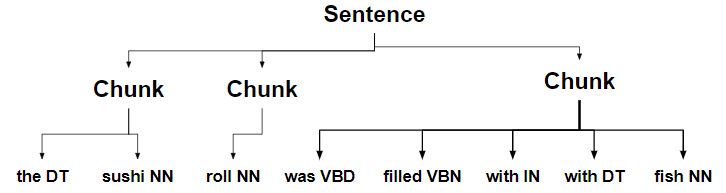
- Чанк с определителем разбивается на отдельные блоки.
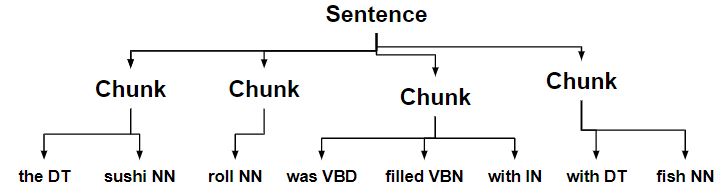
- Фрагменты, оканчивающиеся на существительное, объединяются со следующим чанком.
Код №1 - Построение дерева
from nltk.chunk import RegexpParserchunker = RegexpParser(r '''NP:{<DT><.*>*<NN.*>}<NN.*>}{<.*><.*>}{<DT><NN.*>{}<NN.*>''' )sent = [( 'the' , 'DT' ), ( 'sushi' , 'NN' ), ( 'roll' , 'NN' ), ( 'was' , 'VBD' ), ( 'filled' , 'VBN' ), ( 'with' , 'IN' ), ( 'the' , 'DT' ), ( 'fish' , 'NN' )]chunker.parse(sent) |
Выход:
Дерево ('S', [Tree ('NP', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Дерево ('NP', [('было', 'VBD'), ('заполнено', 'VBN'), ('с', 'IN')]),
Дерево ('NP', [('the', 'DT'), ('fish', 'NN')])])
Код # 2 - Разделение и слияние
# Loading Librariesfrom nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRulefrom nltk.tree import Treefrom nltk.chunk.regexp import MergeRule, SplitRule # Chunk Stringchunk_string = ChunkString(Tree( 'S' , sent))print ( "Chunk String : " , chunk_string) # Applying Chunk Ruleur = ChunkRule( '<DT><.*>*<NN.*>' , 'chunk determiner to noun' )ur. apply (chunk_string)print ( "
Applied ChunkRule : " , chunk_string) # Splittingsr1 = SplitRule( '<NN.*>' , '<.*>' , 'split after noun' )sr1. apply (chunk_string)print ( "
Splitting Chunk String : " , chunk_string) sr2 = SplitRule( '<.*>' , '<DT>' , 'split before determiner' )sr2. apply (chunk_string)print ( "
Further Splitting Chunk String : " , chunk_string) # Mergingmr = MergeRule( '<NN.*>' , '<NN.*>' , 'merge nouns' )mr. apply (chunk_string)print ( "
Merging Chunk String : " , chunk_string) # Back to Treechunk_string.to_chunkstruct() |
Выход:
Строка фрагмента: <DT> <NN> <NN> <VBD> <VBN> <IN> <DT> <NN>
Применяемое ChunkRule: {<DT> <NN> <NN> <VBD> <VBN> <IN> <DT> <NN>}
Разделение строки фрагмента: {<DT> <NN>} {<NN>} {<VBD> <VBN> <IN> <DT> <NN>}
Дальнейшее разделение строки фрагмента: {<DT> <NN>} {<NN>} {<VBD> <VBN> <IN>} {<DT> <NN>}
Объединение строки фрагмента: {<DT> <NN> <NN>} {<VBD> <VBN> <IN>} {<DT> <NN>}
Дерево ('S', [Tree ('CHUNK', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Дерево ('CHUNK', [('было', 'VBD'), ('заполнено', 'VBN'), ('with', 'IN')]),
Дерево ('CHUNK', [('the', 'DT'), ('fish', 'NN')])])
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.