НЛП | Правила разделения
Опубликовано: 25 Июля, 2021
Ниже приведены шаги, необходимые для разбиения на части -
- Преобразование предложения в плоское дерево.
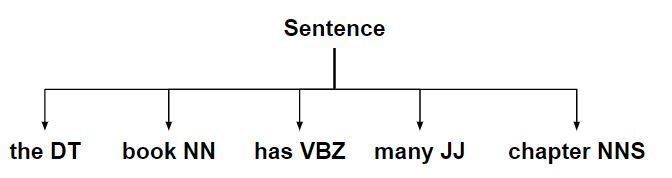
- Создание строки Chunk с использованием этого дерева.
- Создание RegexpChunkParser путем разбора граммера с помощью RegexpParser.
- Применение правила созданного фрагмента к ChunkString, которое соответствует предложению в фрагменте.
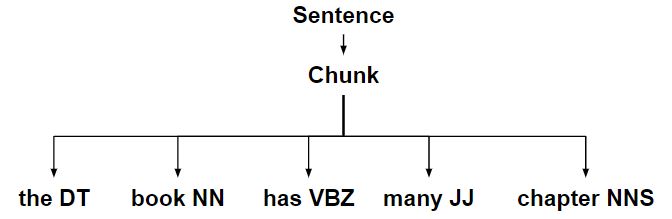
- Разделение большего фрагмента на меньший фрагмент с использованием определенных правил фрагментов.
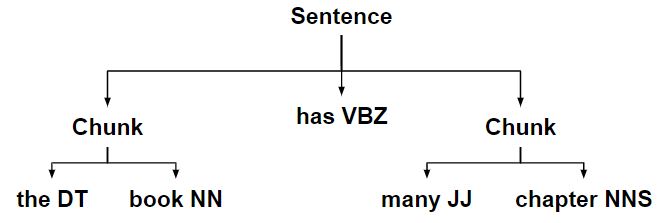
- Затем ChunkString преобразуется обратно в дерево с двумя поддеревьями фрагментов.
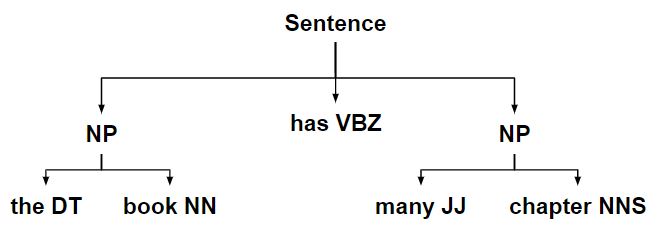
Код №1: ChunkString изменяется с применением каждого правила.
# Loading Librariesfrom nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRulefrom nltk.tree import Tree # ChunkString() starts with the flat treetree = Tree( 'S' , [( 'the' , 'DT' ), ( 'book' , 'NN' ), ( 'has' , 'VBZ' ), ( 'many' , 'JJ' ), ( 'chapters' , 'NNS' )]) # Initializing ChunkString()chunk_string = ChunkString(tree)print ( "Chunk String : " , chunk_string) # Initializing ChunkRulechunk_rule = ChunkRule( '<DT><NN.*><.*>*<NN.*>' , 'chunk determiners and nouns' )chunk_rule. apply (chunk_string)print ( "
Applied ChunkRule : " , chunk_string) # Another ChinkRuleir = ChinkRule( '<VB.*>' , 'chink verbs' )ir. apply (chunk_string)print ( "
Applied ChinkRule : " , chunk_string, "
" ) # Back to chunk sub-treechunk_string.to_chunkstruct() |
Выход:
Строка фрагмента: <<DT> <NN> <VBZ> <JJ> <NNS>
Применяемое ChunkRule: {<DT> <NN> <VBZ> <JJ> <NNS>}
Применяемое ChinkRule: {<DT> <NN>} <VBZ> {<JJ> <NNS>}
Дерево ('S', [Tree ('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree ('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])])
Примечание. Этот код работает точно так же, как описано в шагах ChunkRule выше.
Код №2: Как выполнить эту задачу напрямую с помощью RegexpChunkParser.
# Loading Librariesfrom nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRulefrom nltk.tree import Treefrom nltk.chunk import RegexpChunkParser # ChunkString() starts with the flat treetree = Tree( 'S' , [( 'the' , 'DT' ), ( 'book' , 'NN' ), ( 'has' , 'VBZ' ), ( 'many' , 'JJ' ), ( 'chapters' , 'NNS' )]) # Initializing ChunkRulechunk_rule = ChunkRule( '<DT><NN.*><.*>*<NN.*>' , 'chunk determiners and nouns' ) # Another ChinkRulechink_rule = ChinkRule( '<VB.*>' , 'chink verbs' ) # Applying RegexpChunkParserchunker = RegexpChunkParser([chunk_rule, chink_rule])chunker.parse(tree) |
Выход:
Дерево ('S', [Tree ('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree ('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])])
Код № 3: Разбор с другим ChunkType.
# Loading Librariesfrom nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRulefrom nltk.tree import Treefrom nltk.chunk import RegexpChunkParser # ChunkString() starts with the flat treetree = Tree( 'S' , [( 'the' , 'DT' ), ( 'book' , 'NN' ), ( 'has' , 'VBZ' ), ( 'many' , 'JJ' ), ( 'chapters' , 'NNS' )]) # Initializing ChunkRulechunk_rule = ChunkRule( '<DT><NN.*><.*>*<NN.*>' , 'chunk determiners and nouns' ) # Another ChinkRulechink_rule = ChinkRule( '<VB.*>' , 'chink verbs' ) # Applying RegexpChunkParserchunker = RegexpChunkParser([chunk_rule, chink_rule], chunk_label = 'CP' )chunker.parse(tree) |
Выход:
Tree ('S', [Tree ('CP', [('the', 'DT'), ('book', 'NN')]), ('has', 'VBZ'),
Дерево ('CP', [('многие', 'JJ'), ('главы', 'NNS')])])
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.