НЛП | Обучение Unigram Tagger
Одиночный токен называется Юниграммой , например - привет; кино; кодирование. Эта статья посвящена устройству тегов unigram .
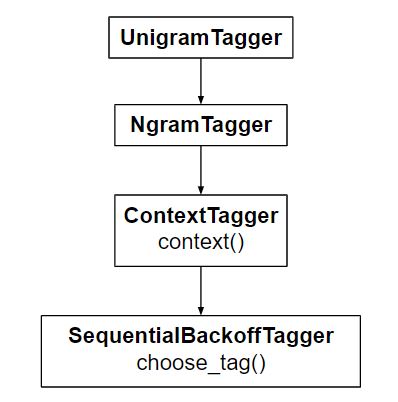
Unigram Tagger: для определения тега Part of Speech используется только одно слово. UnigramTagger наследуется от NgramTagger, который является подклассом ContextTagger , который наследуется от SequentialBackoffTagger . Итак, UnigramTagger - это контекстный теггер из одного слова.
Код №1: Обучение UnigramTagger.
# Loading Librariesfrom nltk.tag import UnigramTaggerfrom nltk.corpus import treebank |
Код № 2: Обучение с использованием первых 1000 помеченных предложений корпуса банка деревьев в качестве данных.
# Using datatrain_sents = treebank.tagged_sents()[:1000] # Initializingtagger = UnigramTagger(train_sents) # Lets see the first sentence # (of the treebank corpus) as list treebank.sents()[0] |
Выход :
['Пьер', 'Винкен', ',', '61', 'годы', 'Старый', ',', 'будут', 'присоединиться', 'the', 'доска', 'в виде', 'а', 'неисполнительный', 'директор', "Ноябрь", '29', '.']
Код № 3: поиск результатов с тегами после тренировки.
tagger.tag(treebank.sents()[ 0 ]) |
Выход :
[('Пьер', 'НПН'),
('Винкен', 'ННП'),
(',', ','),
('61', 'CD'),
('годы', 'NNS'),
('старый', 'JJ'),
(',', ','),
('будет', 'MD'),
('присоединиться', 'VB'),
('the', 'DT'),
('доска', 'NN'),
('как в'),
('а', 'DT'),
('неисполнительный', 'JJ'),
('директор', 'NN'),
(«Ноябрь», «ННП»),
('29', 'CD'),
('.', '.')]
Как работает код?
UnigramTagger строит контекстную модель из списка помеченных предложений. Поскольку UnigramTagger наследуется от ContextTagger , вместо предоставления choose_tag() он должен реализовать context() , который принимает те же три аргумента, что и choose_tag() . Токен контекста используется для создания модели, а также для поиска лучшего тега после создания модели. Это также поясняется графически на приведенной выше диаграмме.
Переопределение контекстной модели -
Все теггеры, унаследованные от ContextTagger вместо обучения своей собственной модели могут использовать предварительно созданную модель. Эта модель представляет собой просто словарь Python, сопоставляющий контекстный ключ с тегом. Ключи контекста (отдельные слова в случае UnigramTagger) будут зависеть от того, что ContextTagger subclass возвращает из своего метода context()
Код # 4: переопределение контекстной модели
tagger = UnigramTagger(model = { 'Pierre' : 'NN' }) tagger.tag(treebank.sents()[ 0 ]) |
Выход :
[('Пьер', 'NN'),
('Винкен', Нет),
(', ', Никто),
('61', Нет),
('лет', Нет),
('старый', Нет),
(', ', Никто),
('будет', Нет),
('присоединиться', Нет),
('the', Нет),
('доска', Нет),
('as', Нет),
('a', Нет),
('неисполнительный', Нет),
('директор', Нет),
('Ноябрь', Нет),
('29', Нет),
('.', Никто)]
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.