Многоленточный недетерминированный тренажер машины Тьюринга
В этой статье рассматриваются как теоретические, так и практические вопросы компьютерных наук (CS). В нем рассматриваются машины Тьюринга (TM), фундаментальный класс автоматов, и представлен симулятор для широкого варианта TM: недетерминированных с несколькими лентами. Недетермимизм моделируется поиском в ширину (BFS) дерева вычислений.
Симулятор написан на Python 3 и использует всю мощь и выразительность этого языка программирования, сочетая методы объектно-ориентированного и функционального программирования.
Организация заключается в следующем. Во-первых, TM вводятся в неформальной манере, подчеркивая их многочисленные приложения в теоретической CS. Затем даются формальные определения базовой модели и многолентного варианта. Наконец, представлен дизайн и реализация симулятора с примерами его использования и выполнения.
Вступление
TM - это абстрактные автоматы, разработанные Аланом Тьюрингом в 1936 году для исследования пределов вычислений. TM могут вычислять функции, следуя простым правилам.
TM - это примитивная вычислительная модель с 3 компонентами:
- Память: лента ввода-вывода, разделенная на дискретные ячейки, в которых хранятся символы. На ленте есть крайняя левая ячейка, но она неограничена справа, поэтому нет ограничений на длину строк, которые она может хранить.
- Блок управления с конечным набором состояний и головкой ленты, которая указывает на текущую ячейку и может перемещаться влево или вправо во время вычисления.
- Программа, хранящаяся в конечном элементе управления, который управляет вычислением машины.
Работа ТМ состоит из трех этапов:
- Инициализация. Входная строка длины N загружается в первые N ячеек ленты. Остальная часть бесконечно многих ячеек содержит специальный символ, называемый пробелом. Машина переходит в стартовое состояние.
- Расчет. Каждый этап вычислений включает в себя:
- Считывание символа в текущей ячейке (той, которую сканирует магнитофон).
- Следуя правилам, определенным программой для комбинации текущего состояния и считываемого символа. Правила называются переходами или перемещениями и состоят из: (а) записи нового символа в текущую ячейку, (б) переключения в новое состояние и (в) необязательного перемещения головы на одну ячейку влево или вправо.
- Доработка. Вычисление останавливается, когда нет правила для текущего состояния и символа. Если машина находится в конечном состоянии, TM принимает входную строку. Если текущее состояние не является окончательным, TM отклоняет входную строку. Обратите внимание, что не все TM достигают этой стадии, потому что возможно, что TM никогда не останавливается на данном входе, входя в бесконечный цикл.
TM имеют множество приложений в теоретической информатике и тесно связаны с теорией формального языка. TM - это распознаватели языка, которые принимают высший класс иерархии языков Хомского: языки типа 0, генерируемые неограниченными грамматиками. Они также являются преобразователями языка: учитывая входную строку одного языка, TM может вычислить выходную строку того же или другого языка. Эта возможность позволяет TM вычислять функции, входы и выходы которых закодированы как строки формального языка, например двоичные числа, рассматриваемые как набор строк в алфавите {0, 1}.
Чёрч-Тьюринг утверждает, что TM могут вычислить любую функцию, которая может быть выражена алгоритмом. Из этого следует, что TM на самом деле являются универсальными компьютерами, которые, будучи абстрактными математическими устройствами, не страдают от ограничений времени и пространства физических. Если этот тезис верен, как считают многие компьютерные ученые, то факт, открытый Тьюрингом, что существуют функции, которые не могут быть вычислены с помощью TM, подразумевает, что существуют функции, которые не могут быть вычислены алгоритмически никаким компьютером в прошлом, настоящем или будущем.
TM также сыграли очень важную роль в изучении вычислительной сложности и одной из центральных открытых проблем в CS и математике: проблема P vs NP. TM представляют собой удобную аппаратно-независимую модель для анализа вычислительной сложности алгоритмов с точки зрения количества выполненных шагов (временная сложность) или количества просканированных ячеек (пространственная сложность) во время вычисления.
Формальное определение: базовая модель
Машина Тьюринга (TM) - это кортеж из семи 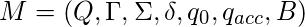 куда:
куда:
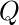 - конечное непустое множество состояний.
- конечное непустое множество состояний. 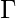 конечный непустой набор символов, называемый ленточным алфавитом.
конечный непустой набор символов, называемый ленточным алфавитом. 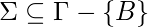 это входной алфавит.
это входной алфавит. 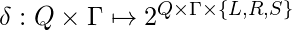 - это функция перехода или следующего хода, которая отображает пары символов состояния на подмножества троек: состояние, символ, направление движения головы (влево, вправо или остановка).
- это функция перехода или следующего хода, которая отображает пары символов состояния на подмножества троек: состояние, символ, направление движения головы (влево, вправо или остановка). 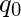 это начальное состояние.
это начальное состояние. 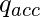 это последнее принимающее состояние.
это последнее принимающее состояние. 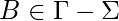 - пустой символ.
- пустой символ.
На каждом этапе вычислений TM можно описать мгновенным описанием (ID). ID - это тройка 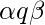 куда
куда 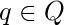 это фактическое состояние,
это фактическое состояние, 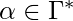 строка, содержащаяся в ячейках слева от ячейки, сканируемой машиной, и
строка, содержащаяся в ячейках слева от ячейки, сканируемой машиной, и 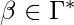 - это строка, содержащаяся в текущей ячейке и других ячейках справа от головки ленты до ячейки, с которой начинается бесконечная последовательность пробелов.
- это строка, содержащаяся в текущей ячейке и других ячейках справа от головки ленты до ячейки, с которой начинается бесконечная последовательность пробелов.
Бинарное отношение 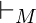 связывает два идентификатора и определяется следующим образом для всех
связывает два идентификатора и определяется следующим образом для всех 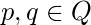 а также
а также 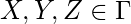 а также
а также 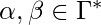 :
:
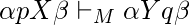 если только
если только 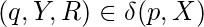
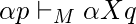 если только
если только 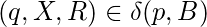
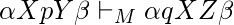 если только
если только 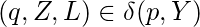
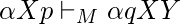 если только
если только 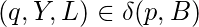
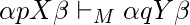 если только
если только 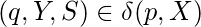
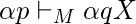 если только
если только 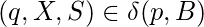
Позволять 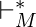 быть транзитивным и рефлексивным замыканием , т. е. применение нуля или более переходов между идентификаторами. Затем язык, распознаваемый
быть транзитивным и рефлексивным замыканием , т. е. применение нуля или более переходов между идентификаторами. Затем язык, распознаваемый 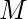 определяется как:
определяется как: 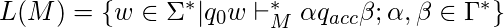 .
.
Если для всех государств и символы ленты 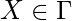 ,
, 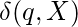 имеет не более одного элемента, ТМ называется детерминированной. Если существуют переходы с более чем одним выбором, TM недетерминирована.
имеет не более одного элемента, ТМ называется детерминированной. Если существуют переходы с более чем одним выбором, TM недетерминирована.
Последовательность идентификаторов детерминированных ТМ линейна. Для недетерминированных TM он формирует дерево вычислений . Можно представить себе недетерминизм, как будто машина создает параллельные копии самой себя. Эта полезная аналогия будет использована в нашем симуляторе.
На первый взгляд, мы можем подумать, что недетерминированные TM более мощные, чем детерминированные TM, потому что способность «угадывать» правильный путь. Но это неправда: DTM - это лишь частный случай NDTM, и любой NDTM может быть преобразован в DTM. Итак, у них одинаковая вычислительная мощность.
Фактически, было предложено несколько вариантов TM: с двусторонней бесконечной лентой, с несколькими дорожками, без опции остановки и т. Д. Интересно, что все эти варианты демонстрируют ту же вычислительную мощность, что и базовая модель. Они признают один и тот же класс языков.
В следующем разделе мы представим очень полезный вариант: многоленточные недетерминированные TM.
Формальное определение: многолента TM
Многоленточные TM имеют несколько лент ввода-вывода с независимыми головками. Этот вариант не увеличивает вычислительную мощность оригинала, но, как мы увидим, он может упростить создание TM с использованием вспомогательных лент.
K-лента TM - это кортеж из 7 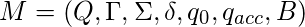 где все элементы такие же, как в базовой TM, за исключением функции перехода, которая является отображением
где все элементы такие же, как в базовой TM, за исключением функции перехода, которая является отображением 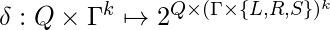 . Он отображает пары символов чтения состояния на подмножества пар новых символов состояния-записи + направления.
. Он отображает пары символов чтения состояния на подмножества пар новых символов состояния-записи + направления.
Например, следующая 2-ленточная TM вычисляет сумму чисел, хранящихся в унарной записи на первой ленте. Первая лента содержит множители: последовательности единиц, разделенных нулями, которые представляют собой натуральные числа. Машина записывает все единицы на ленту 2, вычисляя сумму всех факторов.
Формально пусть 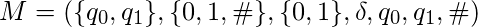 куда
куда 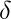 определяется следующим образом:
определяется следующим образом:
- Пропустить все 0:
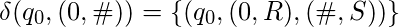
- Скопируйте единицы на ленту 2:
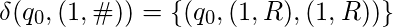
- Остановка при достижении пустого места:
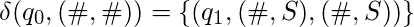
Проблема остановки
Возможно, что TM не останавливается для некоторых входов. Например, рассмотрим TM 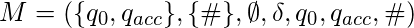 с участием
с участием 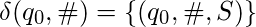 .
.
Проблема остановки заключается в том, что невозможно проверить, остановится ли произвольная TM на заданной входной строке. Эта проблема имеет глубокие последствия, поскольку показывает, что существуют проблемы, которые нельзя вычислить с помощью ТМ, и, если тезис Черча-Тьюринга верен, это означает, что ни один алгоритм не может решить эти проблемы.
Для симулятора TM это очень плохая новость, потому что это означает, что симулятор может войти в бесконечный цикл.
Мы не можем полностью избежать этой проблемы, но мы можем решить ее в ограниченной форме. Рассмотрим случай недетерминированной TM, когда есть ветви дерева вычислений, которые входят в бесконечный цикл и постоянно растут там, где другие достигают конечного состояния. В этом случае симулятор должен прекратить прием входной строки. Но если мы пройдемся по дереву в режиме поиска в глубину (DFS), симулятор застрянет, когда войдет в одну из бесконечных ветвей. Чтобы избежать этого, симулятор будет проходить дерево вычислений с помощью поиска в ширину (BFS). BFS - это стратегия обхода графа, которая исследует всех дочерних элементов ветки до перехода к их преемникам.
Симулятор многоленточных NDTM на Python
В этом разделе мы представим симулятор недетерминированных TM с несколькими лентами, написанными на Python.
Симулятор состоит из двух классов: класса ленты и класса NDTM.
Экземпляры ленты содержат список текущих отсканированных ячеек и указатель на головку ленты и обеспечивают следующие операции:
- readSymbol (): возвращает символ, просканированный головой, или пустое поле, если голова находится в последней просканированной ячейке
- writeSymbol (): заменяет символ, просканированный головой, другим. Если голова находится в последних отсканированных ячейках, добавляет символ в конец списка символов.
- moveHead (): перемещает голову на одну позицию влево (-1), вправо (1) или без позиции (0).
- clone (): создает реплику или копию ленты. Это будет очень полезно для моделирования недетерминизма.
Экземпляры NDTM имеют следующие атрибуты:
- начальное и конечное состояния.
- текущее состояние.
- список лент (Ленточные объекты).
- словарь переходов.
Функция перехода реализована со словарем, ключами которого являются кортежи (состояние, read_symbols), а значениями - списки кортежей (new_state, move). Например, ПП, добавляющая числа в унарной системе счисления, представленная ранее, будет представлена как:
{('q0', ('1', '#')): [('q0', (('1', 'R'), ('1', 'R')))],
('q0', ('0', '#')): [('q0', (('0', 'R'), ('#', 'S')))],
('q0', ('#', '#')): [('q1', (('#', 'S'), ('#', 'S')))]}
Обратите внимание, как представление Python очень похоже на математическое определение функции перехода благодаря универсальным структурам данных Python, таким как словари, кортежи и списки. Подкласс dict, defaultdict из стандартного модуля коллекций, используется для облегчения бремени инициализации.
Объекты NDTM содержат методы для чтения текущего кортежа символов на лентах, для добавления, получения и выполнения переходов, а также для создания реплик текущей TM.
Основной метод NDTM - accept (). Его аргумент является входной строкой, и он возвращает объект NDTM, если какая-либо ветвь дерева вычислений достигает состояния приема, или None, если ни одна из ветвей не достигает. Он просматривает дерево вычислений с помощью поиска в ширину (BFS), чтобы позволить остановке вычислений, если какая-либо ветвь достигает состояния приема. BFS использует очередь для отслеживания ожидающих ветвей. Двусторонняя очередь Python из модуля коллекций используется для получения производительности O (1) в операциях с очередями. Алгоритм следующий:
Добавить экземпляр TM в очередь
Пока очередь не пуста:
Получить первую TM из очереди
Если нет перехода для текущего состояния и прочтите символы:
Если TM находится в конечном состоянии: вернуть TM
Еще:
Если переход недетерминированный:
Создайте реплики TM и добавьте их в очередь
Выполнить переход в текущей TM и добавить его в очередь
Наконец, у класса NDTM есть методы для печати представления TM в виде набора мгновенных описаний и для анализа спецификации TM из файла. Как обычно, эти средства ввода / вывода являются самой громоздкой частью симулятора.
Файлы спецификации имеют следующий синтаксис
% HEADER: обязательный start_state final_state пустое число_кладок % ПЕРЕХОДОВ состояние read_symbols new_state write_symbol, перемещение write_symbol, перемещение ...
Строки, начинающиеся с "%", считаются комментариями. Например, TM, который добавляет числа в унарной записи, имеет следующий файл спецификации:
% ЗАГОЛОВОК q0 q1 # 2 % ПЕРЕХОДОВ q0 1, # q0 1, R 1, R q0 0, # q0 0, R #, S q0 #, # q1 #, S #, S
Состояния и символы могут быть любой строкой, не содержащей пробелов и запятых.
Симулятор можно запустить из сеанса Python для изучения выходной конфигурации. Например, если предыдущий файл сохранен с именем «2sum.tm»:
from NDTM import NDTMtm = NDTM.parse( '2sum.tm' )print (tm.accepts( '11011101' )) |
Выходные данные показывают, что симулятор произвел сумму единиц на ленте №1:
Выход : q1: ['1', '1', '0', '1', '1', '1', '0', '1'] ['#'] q1: ['1', '1', '1', '1', '1', '1'] ['#']
Вывод показывает содержимое двух лент, позиции головок (второй список каждой ленты) и конечное состояние TM.
Исходный код симулятора
Без учета кода ввода / вывода и комментариев симулятор занимает менее 100 строк кода. Это свидетельство силы и экономичности Python. Он объектно-ориентированный, но также использует функциональные конструкции, такие как понимание списков.
##### NDTM.py: a nondeterministic Turing Machine Simulator# Author: David Gil del Rosal (dgilros@yahoo.com)#### from collections import defaultdict, deque Tape: class # Constructor. Sets the blank symbol, the # string to load and the position of the tape head def __init__( self , blank, string = '', head = 0 ): self .blank = blank self .loadString(string, head) # Loads a new string and sets the tape head def loadString( self , string, head): self .symbols = list (string) self .head = head # Returns the symbol on the current cell, or the blank # if the head is on the start of the infinite blanks def readSymbol( self ): if self .head < len ( self .symbols): return self .symbols[ self .head] else : return self .blank # Writes a symbol in the current cell, extending # the list if necessary def writeSymbol( self , symbol): if self .head < len ( self .symbols): self .symbols[ self .head] = symbol else : self .symbols.append(symbol) # Moves the head left (-1), stay (0) or right (1) def moveHead( self , direction): if direction = = 'L' : inc = - 1 elif direction = = 'R' : inc = 1 else : inc = 0 self .head + = inc # Creates a new tape with the same attributes than this def clone( self ): return Tape( self .blank, self .symbols, self .head) # String representation of the tape def __str__( self ): return str ( self .symbols[: self .head]) + str ( self .symbols[ self .head:]) class NDTM: # Constructor. Sets the start and final states and # inits the TM tapes def __init__( self , start, final, blank = '#' , ntapes = 1 ): self .start = self .state = start self .final = final self .tapes = [Tape(blank) for _ in range (ntapes)] self .trans = defaultdict( list ) # Puts the TM in the start state and loads an input # string into the first tape def restart( self , string): self .state = self .start self .tapes[ 0 ].loadString(string, 0 ) for tape in self .tapes[ 1 :]: tape.loadString('', 0 ) # Returns a tuple with the current symbols read def readSymbols( self ): return tuple (tape.readSymbol() for tape in self .tapes) # Add an entry to the transaction table def addTrans( self , state, read_sym, new_state, moves): self .trans[(state, read_sym)].append((new_state, moves)) # Returns the transaction that corresponds to the # current state & read symbols, or None if there is not def getTrans( self ): key = ( self .state, self .readSymbols()) return self .trans[key] , key in self .trans else None if key in self .trans else None # Executes a transaction updating the state and the # tapes. Returns the TM object to allow chaining def execTrans( self , trans): self .state, moves = trans for tape, move in zip ( self .tapes, moves): symbol, direction = move tape.writeSymbol(symbol) tape.moveHead(direction) return self # Returns a copy of the current TM def clone( self ): tm = NDTM( self .start, self .final) tm.state = self .state tm.tapes = [tape.clone() for tape in self .tapes] tm.trans = self .trans # shallow copy return tm # Simulates the TM computation. Returns the TM that # accepted the input string if any, or None. def accepts( self , string): self .restart(string) queue = deque([ self ]) while len (queue) > 0 : tm = queue.popleft() transitions = tm.getTrans() if transitions is None : # there are not transactions. Exit # if the TM is in the final state if tm.state = = tm.final: return tm else : # If the transaction is not deterministic # add replicas of the TM to the queue for trans in transitions[ 1 :]: queue.append(tm.clone().execTrans(trans)) # execute the current transition queue.append(tm.execTrans(transitions[ 0 ])) return None def __str__( self ): out = '' for tape in self .tapes: out + = self .state + ': ' + str (tape) + '
' return out # Simple parser that builds a TM from a text file @staticmethod def parse(filename): tm = None with open (filename) as file : for line in file : spec = line.strip() if len (spec) = = 0 or spec[ 0 ] = = '%' : continue if tm is None : start, final, blank, ntapes = spec.split() ntapes = int (ntapes) tm = NDTM(start, final, blank, ntapes) else : fields = line.split() state = fields[ 0 ] symbols = tuple (fields[ 1 ].split( ', ' )) new_st = fields[ 2 ] moves = tuple ( tuple (m.split( ', ' )) for m in fields[ 3 :]) tm.addTrans(state, symbols, new_st, moves) return tm if __name__ = = '__main__' : # Example TM that performs unary complement tm = NDTM( 'q0' , 'q1' , '#' ) tm.addTrans( 'q0' , ( '0' , ), 'q0' , (( '1' , 'R' ), )) tm.addTrans( 'q0' , ( '1' , ), 'q0' , (( '0' , 'R' ), )) tm.addTrans( 'q0' , ( '#' , ), 'q1' , (( '#' , 'S' ), )) acc_tm = tm.accepts( '11011101' ) if acc_tm: print (acc_tm) else : print ( 'NOT ACCEPTED' ) |
Нетривиальный пример
В качестве последнего примера мы представляем спецификацию трехленточной TM, которая распознает неконтекстно-свободный язык. 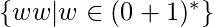 .
.
TM недетерминированно копирует содержимое первой половины строки на ленте №2 и второй половины на ленте №3. Затем он переходит к проверке совпадения обеих частей.
% 3-ленточный NDTM, распознающий L = {ww | w в {0, 1} *}
q0 q4 # 3
% ПЕРЕХОДОВ
% поместил маркеры левых концов на ленты №2 и №3
q0 0, #, # q1 0, S $, R $, R
q0 1, #, # q1 1, S $, R $, R
% первая половина строки: скопируйте символы на ленту №2
q1 0, #, # q1 0, R 0, R #, S
q1 1, #, # q1 1, R 1, R #, S
% угадайте вторую половину строки: скопируйте символы на ленту №3
q1 0, #, # q2 0, R #, S 0, R
q1 1, #, # q2 1, R #, S 1, R
q2 0, #, # q2 0, R #, S 0, R
q2 1, #, # q2 1, R #, S 1, R
% достиг конца входной строки: перейти в состояние сравнения
q2 #, #, # q3 #, S #, L #, L
% сравнить строки на лентах №2 и №3
q3 #, 0, 0 q3 #, S 0, L 0, L
q3 #, 1, 1 q3 #, S 1, L 1, L
%, если обе строки равны, перейти в конечное состояние
q3 #, $, $ q4 #, S $, S $, S
Пример использования. Сохраните указанный выше файл как «3ww.tm» и запустите следующий код:
from NDTM import NDTMtm = NDTM.parse( '3ww.tm' )print (tm.accepts( '11001100' )) |
Результат получился таким, как задумано: TM достигла конечного состояния, и содержимое двух половин входной строки находится