ML | Обнаружение мошенничества с кредитными картами
Задача состоит в том, чтобы распознать мошеннические транзакции по кредитным картам, чтобы с клиентов компаний, выпускающих кредитные карты, не взималась плата за товары, которые они не покупали.
Основные проблемы, возникающие при обнаружении мошенничества с кредитными картами:
- Огромные данные обрабатываются каждый день, и построение модели должно быть достаточно быстрым, чтобы вовремя отреагировать на мошенничество.
- Несбалансированные данные, т.е. большинство транзакций (99,8%) не являются мошенническими, что затрудняет обнаружение мошеннических транзакций.
- Доступность данных, поскольку данные в основном конфиденциальны.
- Неправильно классифицированные данные могут быть еще одной серьезной проблемой, поскольку не все мошеннические транзакции обнаруживаются и сообщаются.
- Адаптивные приемы, используемые мошенниками против модели.
Как решить эти проблемы?
- Используемая модель должна быть простой и достаточно быстрой, чтобы как можно быстрее обнаружить аномалию и классифицировать ее как мошенническую транзакцию.
- С дисбалансом можно справиться, правильно используя некоторые методы, о которых мы поговорим в следующем абзаце.
- Для защиты конфиденциальности пользователя размерность данных может быть уменьшена.
- Необходимо выбрать более надежный источник, который перепроверит данные, по крайней мере, для обучения модели.
- Мы можем сделать модель простой и интерпретируемой, чтобы, когда мошенник адаптируется к ней с помощью лишь некоторых настроек, мы могли бы запустить новую модель для развертывания.
Перед тем, как перейти к коду, предлагается поработать на ноутбуке jupyter. Если он не установлен на вашем компьютере, вы можете использовать Google colab.
Вы можете скачать набор данных по этой ссылке
Если ссылка не работает, перейдите по этой ссылке и войдите в kaggle, чтобы загрузить набор данных.
Код: импорт всех необходимых библиотек
# import the necessary packagesimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom matplotlib import gridspec |
Код: загрузка данных
# Load the dataset from the csv file using pandas# best way is to mount the drive on colab and# copy the path for the csv filedata = pd.read_csv( "credit.csv" ) |
Код: понимание данных
# Grab a peek at the datadata.head() |

Код: описание данных
# Print the shape of the data# data = data.sample(frac = 0.1, random_state = 48)print (data.shape)print (data.describe()) |
Выход :
(284807, 31)
Время V1 ... Сумма Класс
счет 284807.000000 2.848070e + 05 ... 284807.000000 284807.000000
среднее 94813,859575 3,919560e-15 ... 88,349619 0,001727
стандартный 47488.145955 1.958696e + 00 ... 250.120109 0,041527
мин. 0,000000 -5,640751e + 01 ... 0,000000 0,000000
25% 54201.500000 -9.203734e-01 ... 5.600000 0.000000
50% 84692.000000 1.810880e-02 ... 22.000000 0.000000
75% 139320.500000 1.315642e + 00 ... 77.165000 0.000000
макс 172792.000000 2.454930e + 00 ... 25691.160000 1.000000
[8 строк x 31 столбец]
Код: несбалансированность данных
Пора объяснить данные, с которыми мы имеем дело.
# Determine number of fraud cases in datasetfraud = data[data[ 'Class' ] = = 1 ]valid = data[data[ 'Class' ] = = 0 ]outlierFraction = len (fraud) / float ( len (valid))print (outlierFraction)print ( 'Fraud Cases: {}' . format ( len (data[data[ 'Class' ] = = 1 ])))print ( 'Valid Transactions: {}' . format ( len (data[data[ 'Class' ] = = 0 ]))) |
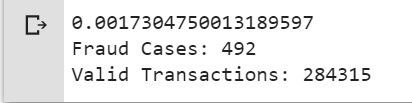
Только 0,17% мошеннических транзакций из всех транзакций. Данные сильно несбалансированы. Давайте сначала применим наши модели без балансировки, и если мы не получим хорошую точность, мы сможем найти способ сбалансировать этот набор данных. Но сначала давайте реализуем модель без него и будем балансировать данные только в случае необходимости.
Код: распечатать сведения о сумме мошеннической транзакции.
print (“Amount details of the fraudulent transaction”)fraud.Amount.describe() |
Выход :
Сведения о сумме мошеннической транзакции кол 492.000000 среднее значение 122.211321 стандартный 256.683288 мин. 0,000000 25% 1.000000 50% 9.250000 75% 105.890000 макс 2125,870000 Имя: Сумма, dtype: float64
Код: распечатать сведения о сумме для обычной транзакции
print (“details of valid transaction”)valid.Amount.describe() |
Выход :
Сведения о сумме действительной транзакции кол 284315.000000 среднее 88.29 · 1022 std 250.105092 мин. 0,000000 25% 5,650000 50% 22.000000 75% 77.050000 макс 25691.160000 Имя: Amount, dtype: float64
Как мы можем ясно заметить из этого, средняя денежная транзакция для мошеннических транзакций больше. Это делает эту проблему критически важной.
Код: построение корреляционной матрицы
Матрица корреляции графически дает нам представление о том, как функции коррелируют друг с другом, и может помочь нам предсказать, какие функции наиболее важны для прогноза.
# Correlation matrixcorrmat = data.corr()fig = plt.figure(figsize = ( 12 , 9 ))sns.heatmap(corrmat, vmax = . 8 , square = True )plt.show() |

На тепловой карте мы можем ясно видеть, что большинство функций не коррелируют с другими функциями, но есть некоторые функции, которые имеют положительную или отрицательную корреляцию друг с другом. Например, V2 и V5 сильно отрицательно коррелируют с функцией Amount . Мы также видим некоторую корреляцию с V20 и Amount . Это дает нам более глубокое понимание доступных нам данных.
Код: разделение значений X и Y
Разделение данных на входные параметры и формат выходных значений
# dividing the X and the Y from the datasetX = data.drop([ 'Class' ], axis = 1 )Y = data[ "Class" ]print (X.shape)print (Y.shape)# getting just the values for the sake of processing# (its a numpy array with no columns)xData = X.valuesyData = Y.values |
Выход :
(284807, 30) (284807,)
Бифуркация данных обучения и тестирования
Мы разделим набор данных на две основные группы. Один для обучения модели, а другой для тестирования производительности нашей обученной модели.
# Using Skicit-learn to split data into training and testing setsfrom sklearn.model_selection import train_test_split# Split the data into training and testing setsxTrain, xTest, yTrain, yTest = train_test_split( xData, yData, test_size = 0.2 , random_state = 42 ) |
Код: построение модели случайного леса с помощью skicit learn
# Building the Random Forest Classifier (RANDOM FOREST)from sklearn.ensemble import RandomForestClassifier# random forest model creationrfc = RandomForestClassifier()rfc.fit(xTrain, yTrain)# predictionsyPred = rfc.predict(xTest) |
Код: создание всех видов оценивающих параметров
# Evaluating the classifier# printing every score of the classifier# scoring in anythingfrom sklearn.metrics import classification_report, accuracy_scorefrom sklearn.metrics import precision_score, recall_scorefrom sklearn.metrics import f1_score, matthews_corrcoeffrom sklearn.metrics import confusion_matrix n_outliers = len (fraud)n_errors = (yPred ! = yTest). sum ()print ( "The model used is Random Forest classifier" ) acc = accuracy_score(yTest, yPred)print ( "The accuracy is {}" . format (acc)) prec = precision_score(yTest, yPred)print ( "The precision is {}" . format (prec)) rec = recall_score(yTest, yPred)print ( "The recall is {}" . format (rec)) f1 = f1_score(yTest, yPred)print ( "The F1-Score is {}" . format (f1)) MCC = matthews_corrcoef(yTest, yPred)print ( "The Matthews correlation coefficient is{}" . format (MCC)) |
Выход :
Используемая модель - классификатор случайного леса. Точность: 0,9995611109160493 Точность 0,9866666666666667 Отзыв 0,7551020408163265 F1-Score составляет 0,8554913294797689. Коэффициент корреляции Мэтьюза равен 0,8629589216367891.
Код: визуализация матрицы путаницы
# printing the confusion matrixLABELS = [ 'Normal' , 'Fraud' ]conf_matrix = confusion_matrix(yTest, yPred)plt.figure(figsize = ( 12 , 12 ))sns.heatmap(conf_matrix, xticklabels = LABELS, yticklabels = LABELS, annot = True , fmt = "d" );plt.title( "Confusion matrix" )plt.ylabel( 'True class' )plt.xlabel( 'Predicted class' )plt.show() |
Выход :

Сравнение с другими алгоритмами без разбалансировки данных. 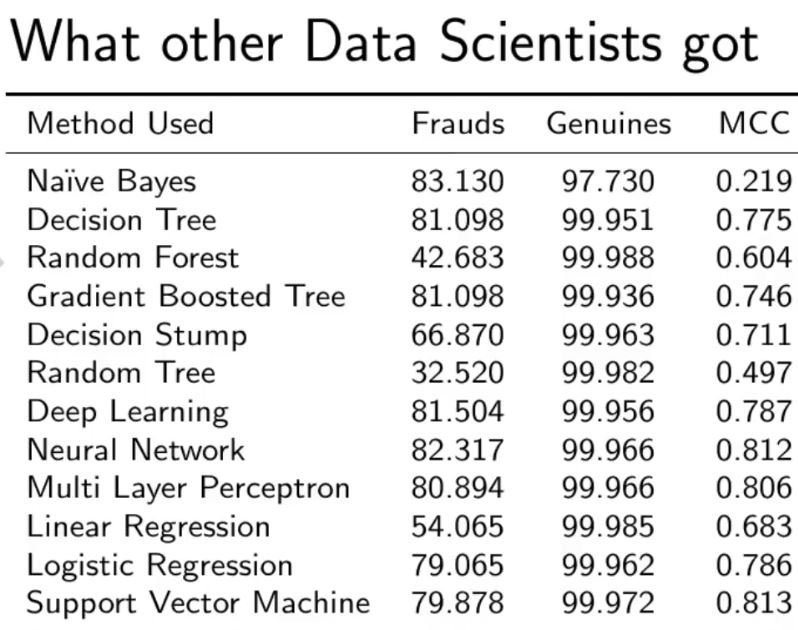
Как вы можете видеть, с нашей моделью случайного леса мы получаем лучший результат даже для отзыва, который является наиболее сложной частью.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.
- Аканкша_Рай
- Ashwinsharmap
- Машинное обучение
- Проект
- Python
- Машинное обучение