Линейная регрессия (реализация на Python)
В этой статье обсуждаются основы линейной регрессии и ее реализация на языке программирования Python.
Линейная регрессия - это статистический метод моделирования отношений между зависимой переменной с заданным набором независимых переменных.
Примечание. В этой статье мы называем зависимые переменные откликом, а независимые переменные - функциями для простоты.
Чтобы обеспечить базовое понимание линейной регрессии, мы начнем с самой базовой версии линейной регрессии, то есть с простой линейной регрессии .
Простая линейная регрессия
Простая линейная регрессия - это подход к прогнозированию ответа с использованием одной функции .
Предполагается, что две переменные связаны линейно. Следовательно, мы пытаемся найти линейную функцию, которая предсказывает значение отклика (y) как можно точнее как функцию функции или независимой переменной (x).
Давайте рассмотрим набор данных, в котором у нас есть значение ответа y для каждой функции x:

Для общности определим:
x как вектор признаков , т.е. x = [x_1, x_2,…., x_n],
y как вектор ответа , т.е. y = [y_1, y_2,…., y_n]
для n наблюдений (в примере выше n = 10).
Диаграмма рассеяния вышеприведенного набора данных выглядит так: -
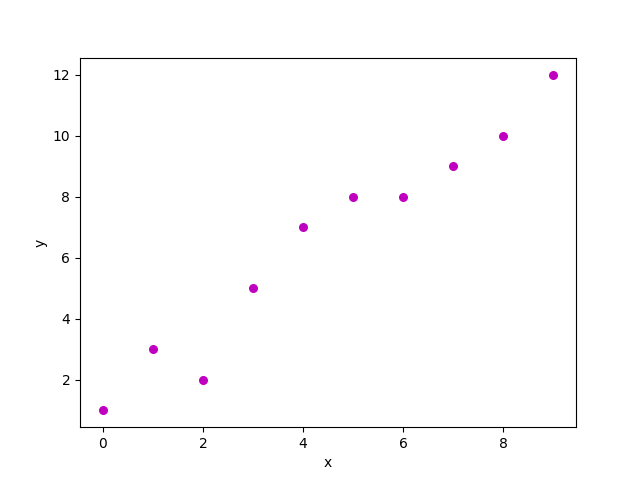
Теперь задача состоит в том, чтобы найти линию, которая лучше всего подходит для приведенного выше графика рассеяния, чтобы мы могли предсказать реакцию на любые новые значения функций. (т.е. значение x отсутствует в наборе данных)
Эта линия называется линией регрессии .
Уравнение линии регрессии представлено в виде: 
Здесь,
- h (x_i) представляет собой предсказанное значение отклика для i- го наблюдения.
- b_0 и b_1 - коэффициенты регрессии и представляют точку пересечения по оси y и наклон линии регрессии соответственно.
To create our model, we must “learn” or estimate the values of regression coefficients b_0 and b_1. And once we’ve estimated these coefficients, we can use the model to predict responses!
In this article, we are going to use the principle of Least Squares .
Now consider:
Here, e_i is residual error in ith observation.
So, our aim is to minimize the total residual error.
We define the squared error or cost function, J as: 
and our task is to find the value of b_0 and b_1 for which J(b_0,b_1) is minimum!
Without going into the mathematical details, we present the result here:

where SS_xy is the sum of cross-deviations of y and x: 
and SS_xx is the sum of squared deviations of x: 
Note: The complete derivation for finding least squares estimates in simple linear regression can be found here.
Given below is the python implementation of above technique on our small dataset:
Python
import numpy as npimport matplotlib.pyplot as pltdef estimate_coef(x, y): # number of observations/points n = np.size(x) # mean of x and y vector m_x = np.mean(x) m_y = np.mean(y) # calculating cross-deviation and deviation about x SS_xy = np.sum(y*x) - n*m_y*m_x SS_xx = np.sum(x*x) - n*m_x*m_x # calculating regression coefficients b_1 = SS_xy / SS_xx b_0 = m_y - b_1*m_x return (b_0, b_1)def plot_regression_line(x, y, b): # plotting the actual points as scatter plot plt.scatter(x, y, color = "m", marker = "o", s = 30) # predicted response vector y_pred = b[0] + b[1]*x # plotting the regression line plt.plot(x, y_pred, color = "g") # putting labels plt.xlabel("x") plt.ylabel("y") # function to show plot plt.show()def main(): # observations / data x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) y = np.array([1, 3, 2, 5, 7, 8, 8, 9, 10, 12]) # estimating coefficients b = estimate_coef(x, y) print("Estimated coefficients:
b_0 = {}
b_1 = {}".format(b[0], b[1])) # plotting regression line plot_regression_line(x, y, b)if __name__ == "__main__": main() |
Вывод приведенного выше фрагмента кода:
Расчетные коэффициенты: b_0 = -0,0586206896552 b_1 = 1,45747126437
И полученный график выглядит так:
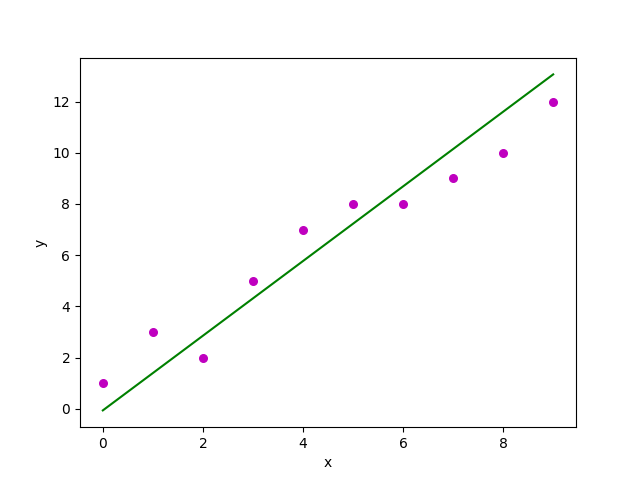
Множественная линейная регрессия
Multiple linear regression attempts to model the relationship between two or more features and a response by fitting a linear equation to the observed data.
Clearly, it is nothing but an extension of simple linear regression.
Consider a dataset with p features(or independent variables) and one response(or dependent variable).
Also, the dataset contains n rows/observations.
We define:
X (feature matrix) = a matrix of size n X p where x_{ij} denotes the values of jth feature for ith observation.
So, 
and
y (response vector) = a vector of size n where y_{i} denotes the value of response for ith observation.
The regression line for p features is represented as: 
where h(x_i) is predicted response value for ith observation and b_0, b_1, …, b_p are the regression coefficients.
Also, we can write: 
where e_i represents residual error in ith observation.
We can generalize our linear model a little bit more by representing feature matrix X as: 
So now, the linear model can be expressed in terms of matrices as: 
where, 
and
Now, we determine estimate of b, i.e. b’ using Least Squares method.
As already explained, Least Squares method tends to determine b’ for which total residual error is minimized.
We present the result directly here: 
where ‘ represents the transpose of the matrix while -1 represents the matrix inverse.
Knowing the least square estimates, b’, the multiple linear regression model can now be estimated as:
where y’ is estimated response vector.
Note: The complete derivation for obtaining least square estimates in multiple linear regression can be found here.
Given below is the implementation of multiple linear regression technique on the Boston house pricing dataset using Scikit-learn.
Python
import matplotlib.pyplot as pltimport numpy as npfrom sklearn import datasets, linear_model, metrics# load the boston datasetboston = datasets.load_boston(return_X_y=False)# defining feature matrix(X) and response vector(y)X = boston.datay = boston.target# splitting X and y into training and testing setsfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)# create linear regression objectreg = linear_model.LinearRegression()# train the model using the training setsreg.fit(X_train, y_train)# regression coefficientsprint("Coefficients: ", reg.coef_)# variance score: 1 means perfect predictionprint("Variance score: {}".format(reg.score(X_test, y_test)))# plot for residual error## setting plot styleplt.style.use("fivethirtyeight")## plotting residual errors in training dataplt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train, color = "green", s = 10, label = "Train data")## plotting residual errors in test dataplt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test, color = "blue", s = 10, label = "Test data")## plotting line for zero residual errorplt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)## plotting legendplt.legend(loc = "upper right")## plot titleplt.title("Residual errors")## method call for showing the plotplt.show() |
Вывод вышеуказанной программы выглядит так:
Coefficients: [ -8.80740828e-02 6.72507352e-02 5.10280463e-02 2.18879172e+00 -1.72283734e+01 3.62985243e+00 2.13933641e-03 -1.36531300e+00 2.88788067e-01 -1.22618657e-02 -8.36014969e-01 9.53058061e-03 -5.05036163e-01] Variance score: 0.720898784611
и график остаточной ошибки выглядит так:
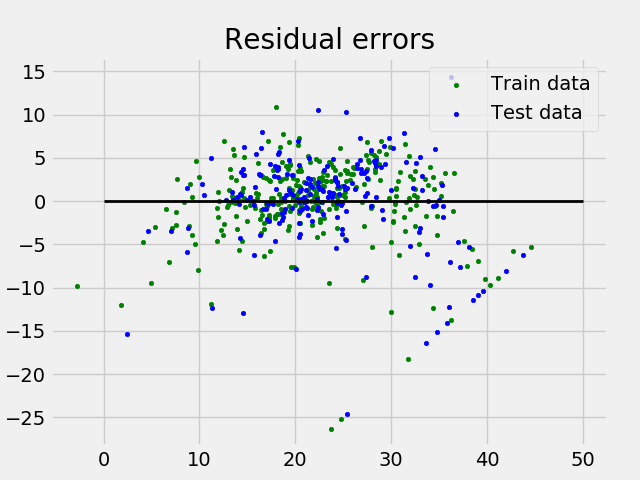
В приведенном выше примере мы определяем показатель точности с помощью показателя объясненной дисперсии .
Мы определяем:
объясненная_вариантная_счет = 1 - Вар {y - y '} / Вар {y}
где y '- предполагаемый целевой результат, y - соответствующий (правильный) целевой результат, а Var - это дисперсия, квадрат стандартного отклонения.
Наилучшая возможная оценка - 1.0, более низкие значения - хуже.
Предположения
Ниже приведены основные предположения, которые делает модель линейной регрессии в отношении набора данных, к которому она применяется:
- Линейная взаимосвязь : взаимосвязь между откликом и характеристическими переменными должна быть линейной. Предположение о линейности можно проверить с помощью диаграмм рассеяния. Как показано ниже, 1-й рисунок представляет линейно связанные переменные, тогда как переменные на 2-м и 3-м рисунках, скорее всего, являются нелинейными. Итак, 1-е число даст лучшие прогнозы с использованием линейной регрессии.

- Малая мультиколлинеарность или ее отсутствие. Предполагается, что мультиколлинеарность данных незначительна или отсутствует. Мультиколлинеарность возникает, когда признаки (или независимые переменные) не независимы друг от друга.
- Небольшая автокорреляция или ее отсутствие . Другое предположение состоит в том, что автокорреляция в данных незначительна или отсутствует. Автокорреляция возникает, когда остаточные ошибки не независимы друг от друга. Вы можете обратиться сюда, чтобы получить более подробное представление об этой теме.
- Гомоскедастичность : гомоскедастичность описывает ситуацию, в которой член ошибки (то есть «шум» или случайное нарушение во взаимосвязи между независимыми переменными и зависимой переменной) одинаков для всех значений независимых переменных. Как показано ниже, рисунок 1 имеет гомоскедастичность, а рисунок 2 - гетероскедастичность.

Дойдя до конца этой статьи, мы обсудим некоторые применения линейной регрессии ниже.
Приложения:
1. Линии тренда: линия тренда представляет изменение количественных данных с течением времени (например, ВВП, цены на нефть и т. Д.). Эти тенденции обычно имеют линейную зависимость. Следовательно, линейная регрессия может применяться для прогнозирования будущих значений. Однако этот метод страдает отсутствием научной обоснованности в тех случаях, когда другие потенциальные изменения могут повлиять на данные.
2. Экономика: линейная регрессия - преобладающий эмпирический инструмент в экономике. Например, он используется для прогнозирования потребительских расходов, инвестиций в основной капитал, инвестиций в товарно-материальные запасы, покупок экспорта страны, расходов на импорт, спроса на удержание ликвидных активов, спроса на рабочую силу и предложения рабочей силы.
3. Финансы. Модель стоимости капитала использует линейную регрессию для анализа и количественной оценки систематических рисков инвестиций.
4. Биология: линейная регрессия используется для моделирования причинно-следственных связей между параметрами в биологических системах.
Использованная литература:
- https://en.wikipedia.org/wiki/Linear_regression
- https://en.wikipedia.org/wiki/Simple_linear_regression
- http://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html
- http://www.statisticssolutions.com/assumings-of-linear-regression/
Этот блог предоставлен Нихилом Кумаром. Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.