Глубокая нейронная сеть с L - слоями
Эта статья направлена на реализацию глубокой нейронной сети с произвольным количеством скрытых слоев, каждый из которых содержит разное количество нейронов. Мы будем реализовывать эту нейронную сеть, используя несколько вспомогательных функций, и, наконец, мы объединим эти функции, чтобы создать модель нейронной сети L-уровня.
L - слой глубокой структуры нейронной сети (для понимания)
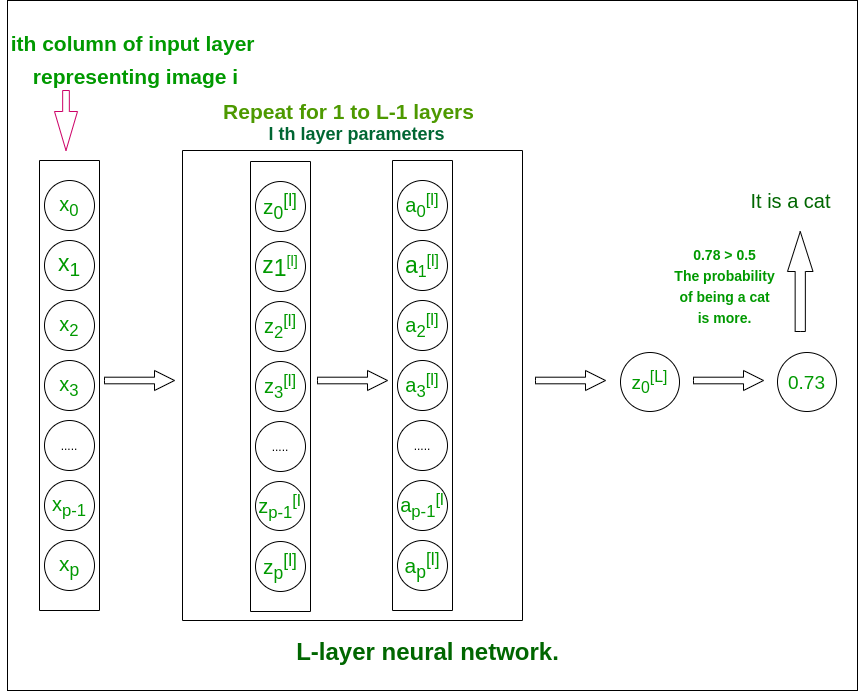
L - слой нейронной сети
Структура модели [LINEAR -> tanh] (L-1 times) -> LINEAR -> SIGMOID. то есть, он имеет слои L-1, использующие функцию гиперболического тангенса в качестве функции активации, за которой следует выходной слой с функцией активации сигмоида.
Подробнее о функциях активации
Пошаговая реализация нейронной сети:
- Инициализируйте параметры для L-слоев
- Реализуйте модуль прямого распространения
- Вычислить потери на последнем слое
- Реализуйте модуль обратного распространения
- Наконец, обновите параметры
- Обучите модель, используя существующий набор обучающих данных
- Используйте обученные параметры для тестирования модели
Соглашения об именах, использованные в статье, чтобы избежать путаницы:
- Каждый уровень в сети представлен набором из двух параметров W- матрица (матрица весов) и b- матрица (матрица смещения). Для слоя i эти параметры представлены как Wi и bi соответственно.
- Линейный выход слоя i представлен как Zi , а выходной сигнал после активации представлен как Ai . Размеры Zi и Ai одинаковы.
Размеры матриц весов и смещений.
Входной слой имеет размер (x, m), где m - количество изображений.
| Номер слоя | Форма W | Форма b | Линейный выход | Форма активации |
|---|---|---|---|---|
| Слой 1 | 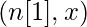 | 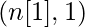 | 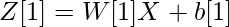 | 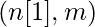 |
| Слой 2 | 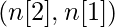 | 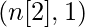 | 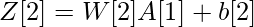 | 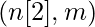 |
| : |  | | | |
| Слой L - 1 | 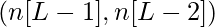 | 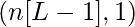 | 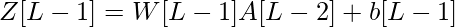 | 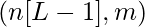 |
| Слой L | 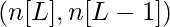 | 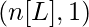 | 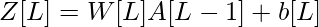 | 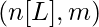 |
Код: импорт всех необходимых библиотек Python.
time importimport numpy as npimport h5pyimport matplotlib.pyplot as pltimport scipyfrom PIL import Imagefrom scipy import ndimage |
Инициализация:
- Мы будем использовать случайную инициализацию для весовых матриц (чтобы избежать идентичного вывода от всех нейронов в одном слое).
- Нулевая инициализация смещений.
- Количество нейронов в каждом слое хранится в словаре layer_dims с ключами в качестве номера слоя.
Код:
def initialize_parameters_deep(layer_dims): # 0th layer is the input layer with number # of columns stored in layer_dims. parameters = {} # number of layers in the network L = len (layer_dims) for l in range ( 1 , L): parameters[ 'W' + str (l)] = np.random.randn(layer_dims[l], layer_dims[l - 1 ]) * 0.01 parameters[ 'b' + str (l)] = np.zeros((layer_dims[l], 1 )) return parameters |
Модуль прямого распространения:
Модуль прямого распространения будет завершен в три этапа. В этом порядке мы выполним три функции:
- linear_forward (для вычисления линейного выхода Z для любого слоя)
- linear_activation_forward, где активация будет либо tanh, либо Sigmoid.
- L_model_forward [LINEAR -> tanh] (L-1 раз) -> LINEAR -> SIGMOID (вся модель)
Модуль linear forward (векторизованный по всем примерам) вычисляет следующие уравнения:
Код:
def linear_forward(A_prev, W, b): # cache is stored to be used in backward propagation module Z = np.dot(W, A_prev) + b cache = (A, W, b) return Z, cache |
def sigmoid(Z): A = 1 / ( 1 + np.exp( - Z)) return A, { 'Z' : Z} def tanh(Z): A = np.tanh(Z) return A, { 'Z' : Z} def linear_activation_forward(A_prev, W, b, activation): # cache is stored to be used in backward propagation module if activation = = "sigmoid" : Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) elif activation = = "tanh" : Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = tanh(Z) cache = (linear_cache, activation_cache) return A, cache |
def L_model_forward(X, parameters): """ Arguments: X -- data, numpy array of shape (input size, number of examples) parameters -- output of initialize_parameters_deep() Returns: AL -- last post-activation value caches -- list of caches containing: every cache of linear_activation_forward() (there are L-1 of them, indexed from 0 to L-1) """ caches = [] A = X # number of layers in the neural network L = len (parameters) / / 2 # Implement [LINEAR -> TANH]*(L-1). Add "cache" to the "caches" list. for l in range ( 1 , L): A_prev = A A, cache = linear_activation_forward(A_prev, parameters[ 'W' + str (l)], parameters[ 'b' + str (l)], 'tanh' ) caches.append(cache) # Implement LINEAR -> SIGMOID. Add "cache" to the "caches" list. AL, cache = linear_activation_forward(A, parameters[ 'W' + str (L)], parameters[ 'b' + str (L)], 'sigmoid' ) caches.append(cache) return AL, caches |

Мы будем использовать эту функцию стоимости, которая будет измерять стоимость выходного слоя для всех данных обучения.
Код:
def compute_cost(AL, Y): """ Implement the cost function defined by the equation. m = Y.shape[ 1 ] cost = ( - 1 / m) * (np.dot(np.log(AL), YT) + np.dot(np.log(( 1 - AL)), ( 1 - Y).T)) # To make sure your cost's shape is what we # expect (eg this turns [[20]] into 20). cost = np.squeeze(cost) return cost |
Модуль обратного распространения:
Подобно модулю прямого распространения, в этом модуле мы также будем реализовывать три функции.
- linear_backward (для вычисления линейного выхода Z для любого слоя)
- linear_activation_backward, где активация будет либо tanh, либо Sigmoid.
- L_model_backward [LINEAR -> tanh] (L-1 раз) -> LINEAR -> SIGMOID (обратное распространение всей модели)
Для слоя i линейная часть: Zi = Wi * A (i - 1) + bi
Обозначая dZi = 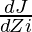 мы можем получить dWi, dbi и dA (i - 1) как -
мы можем получить dWi, dbi и dA (i - 1) как -
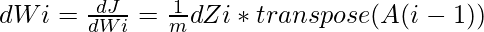
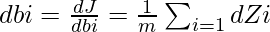

Эти уравнения сформулированы с использованием дифференциального исчисления и сохранения размеров матриц, подходящих для матричного умножения с использованием функции
np.dot() .Код: код Python для реализации
def linear_backward(dZ, cache): A_prev, W, b = cache m = A_prev.shape[ 1 ] dW = ( 1 / m) * np.dot(dZ, A_prev.T) db = ( 1 / m) * np. sum (dZ, axis = 1 , keepdims = True ) dA_prev = np.dot(WT, dZ) return dA_prev, dW, db |
Здесь мы будем вычислять производную сигмоидальных и tanh функций.
Код:
def sigmoid_backward(dA, activation_cache): Z = activation_cache[ 'Z' ] A = sigmoid(Z) return dA * (A * ( 1 - A)) # A*(1 - A) is the derivative of sigmoid function def tanh_backward(dA, activation_cache): Z = activation_cache[ 'Z' ] A = sigmoid(Z) return dA * ( 1 - np.power(A, 2 )) # A*(1 - def linear_activation_backward(dA, cache, activation): linear_cache, activation_cache = cache if activation = = "tanh" : dZ = tanh_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) elif activation = = "sigmoid" : dZ = sigmoid_backward(dA, activation_cache) dA_prev, dW, db = linear_backward(dZ, linear_cache) return dA_prev, dW, db |
 ) is the derivative of tanh function
) is the derivative of tanh functionL-модель назад:
Напомним, что при реализации функции L_model_forward на каждой итерации вы сохраняли кеш, содержащий (X, W, b и Z). В модуле обратного распространения вы будете использовать эти переменные для вычисления градиентов.
def L_model_backward(AL, Y, caches): """ AL -- probability vector, output of the forward propagation (L_model_forward()) Y -- true "label" vector (containing 0 if non-cat, 1 if cat) caches -- list of caches containing: every cache of linear_activation_forward() with "tanh" (it's caches[l], for l in range(L-1) ie l = 0...L-2) the cache of linear_activation_forward() with "sigmoid" (it's caches[L-1]) Returns: grads -- A dictionary with the gradients grads["dA" + str(l)] = ... grads["dW" + str(l)] = ... grads["db" + str(l)] = ... """ grads = {} L = len (caches) # the number of layers m = AL.shape[ 1 ] Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL # Initializing the backpropagation # derivative of cost with respect to AL dAL = - (np.divide(Y, AL) - np.divide( 1 - Y, 1 - AL)) # Lth layer (SIGMOID -> LINEAR) gradients. Inputs: "dAL, current_cache". # Outputs: "grads["dAL-1"], grads["dWL"], grads["dbL"] current_cache = caches[L - 1 ] grads[ "dA" + str (L - 1 )], grads[ "dW" + str (L)], grads[ "db" + str (L)] = linear_activation_backward(dAL, current_cache, 'sigmoid' ) # Loop from l = L-2 to l = 0 for l in reversed ( range (L - 1 )): current_cache = caches[l] dA_prev_temp, dW_temp, db_temp = linear_activation_backward( grads[ 'dA' + str (l + 1 )], current_cache, 'tanh' ) grads[ "dA" + str (l)] = dA_prev_temp grads[ "dW" + str (l + 1 )] = dW_temp grads[ "db" + str (l + 1 )] = db_temp return grads |
Параметры обновления:
bi = bi - a * dbi
(где a - соответствующая константа, известная как скорость обучения)
def update_parameters(parameters, grads, learning_rate): L = len (parameters) / / 2 # number of layers in the neural network # Update rule for each parameter. Use a for loop. for l in range (L): parameters[ "W" + str (l + 1 )] = parameters[ "W" + str (l + 1 )] - learning_rate * grads[ 'dW' + str (l + 1 )] parameters[ "b" + str (l + 1 )] = parameters[ 'b' + str (l + 1 )] - learning_rate * grads[ 'db' + str (l + 1 )] return parameters |
Код: обучение модели
Теперь пришло время собрать все функции, написанные ранее, чтобы сформировать окончательную L-слоистую модель нейронной сети. Аргумент X в L_layer_model будет набором обучающих данных, а Y - соответствующими метками.
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075 , num_iterations = 3000 , print_cost = False ): """ Arguments: X -- data, numpy array of shape (num_px * num_px * 3, number of examples) Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) layers_dims -- list containing the input size and each layer size, of length (number of layers + 1). learning_rate -- learning rate of the gradient descent update rule num_iterations -- number of iterations of the optimization loop print_cost -- if True, it prints the cost every 100 steps Returns: parameters -- parameters learned by the model. They can then be used to predict. """ np.random.seed( 1 ) costs = [] # keep track of cost parameters = initialize_parameters_deep(layers_dims) # Loop (gradient descent) for i in range ( 0 , num_iterations): # Forward propagation: [LINEAR -> TANH]*(L-1) -> LINEAR -> SIGMOID. AL, caches = L_model_forward(X, parameters) # Compute cost. cost = compute_cost(AL, Y) # Backward propagation. grads = L_model_backward(AL, Y, caches) # Update parameters. parameters = update_parameters(parameters, grads, learning_rate) # Print the cost every 100 training example if print_cost and i % 100 = = 0 : print ( "Cost after iteration % i: % f" % (i, cost)) if print_cost and i % 100 = = 0 : costs.append(cost) # plot the cost plt.plot(np.squeeze(costs)) plt.ylabel( 'cost' ) plt.xlabel( 'iterations (per hundreds)' ) plt.title( "Learning rate =" + str (learning_rate)) plt.show() return parameters |
Код: реализация функции прогнозирования для проверки предоставленного изображения.
def predict(parameters, path_image): my_image = path_image image = np.array(ndimage.imread(my_image, flatten = False )) my_image = scipy.misc.imresize(image, size = (num_px, num_px)).reshape(( num_px * num_px * 3 , 1 )) my_image = my_image / 255. output, cache = L_model_forward(my_image, parameters) output = np.squeeze(output) prediction = round (output) if (prediction = = 1 ): label = "Cat picture" else : label = "Non-Cat picture" # If the model is trained to recognize a cat image. print ( "y = " + str (prediction) + ", your L-layer model predicts a "" + label) |
При условии Layers_dims = [12288, 20, 7, 5, 1], когда эта модель обучается с соответствующим количеством обучающих наборов данных, она имеет точность до 80% на тестовых данных.
Параметры находятся после обучения с соответствующим количеством обучающих данных.
{ 'W1' : array([[ 0.01672799 , - 0.00641608 , - 0.00338875 , ..., - 0.00685887 , - 0.00593783 , 0.01060475 ], [ 0.01395808 , 0.00407498 , - 0.0049068 , ..., 0.01317046 , 0.00221326 , 0.00930175 ], [ - 0.00123843 , - 0.00597204 , 0.00472214 , ..., 0.00101904 , - 0.00862638 , - 0.00505112 ], ..., [ 0.00140823 , - 0.00137711 , 0.0163992 , ..., - 0.00846451 , - 0.00761603 , - 0.00149162 ], [ - 0.00168698 , - 0.00618577 , - 0.01023935 , ..., 0.02050705 ,РЕКОМЕНДУЕМЫЕ СТАТЬИ |