Фильтры в Linux
Фильтры - это программы, которые принимают обычный текст (хранящийся в файле или созданный другой программой) в качестве стандартного ввода, преобразует его в осмысленный формат, а затем возвращает его как стандартный вывод. В Linux есть несколько фильтров. Некоторые из наиболее часто используемых фильтров описаны ниже:
1. cat: отображает текст файла построчно.
Синтаксис:
кот [путь]
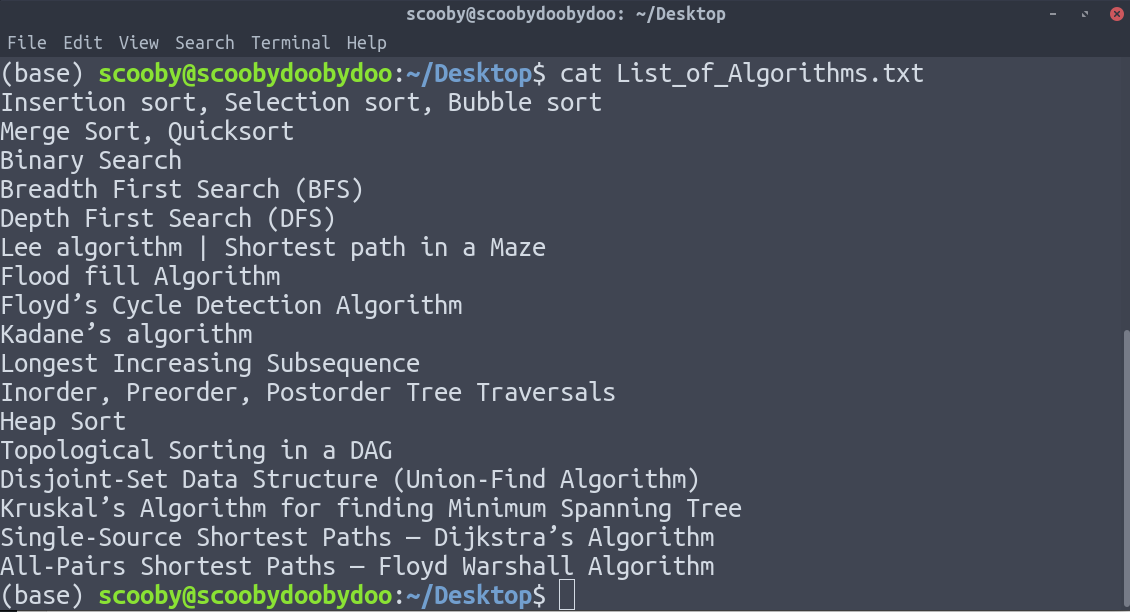
2. head: отображает первые n строк указанных текстовых файлов. Если количество строк не указано, по умолчанию печатаются первые 10 строк.
Синтаксис:
head [-number_of_lines_to_print] [путь]
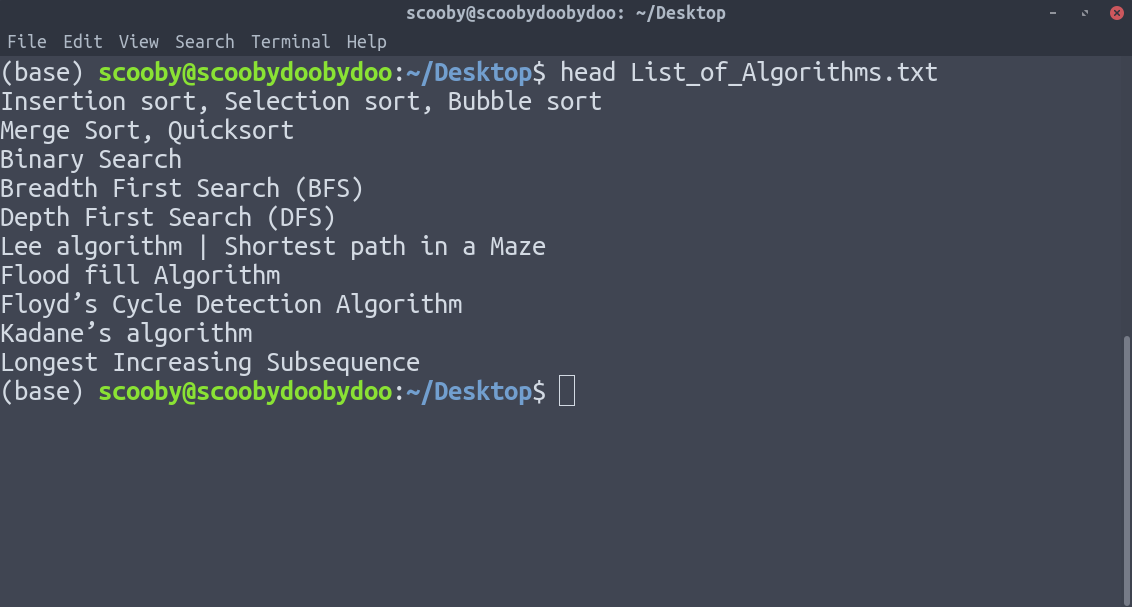
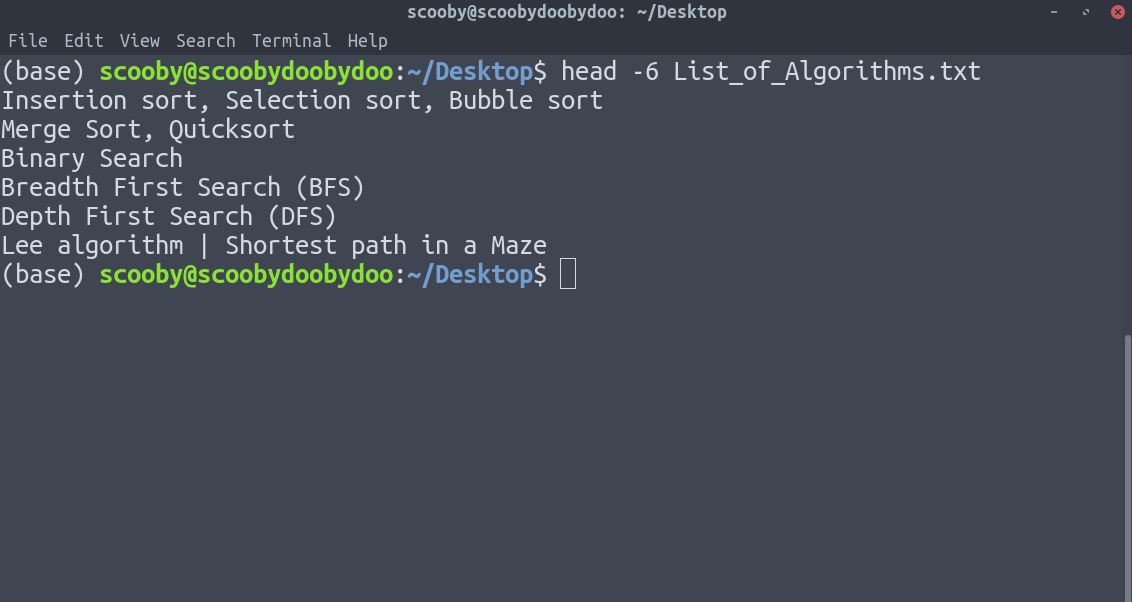
3. Хвост: он работает так же, как голова, только в обратном порядке. Единственное отличие хвоста в том, что он возвращает линии снизу вверх.
Синтаксис:
хвост [-number_of_lines_to_print] [путь]
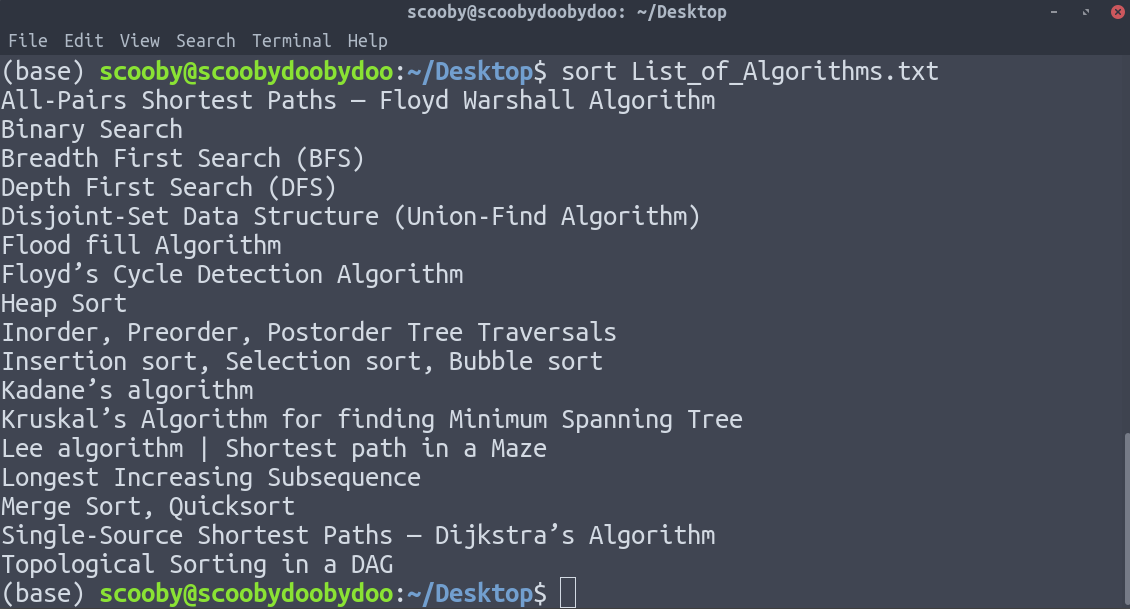
4. Сортировка: по умолчанию строки сортируются в алфавитном порядке, но есть много вариантов, позволяющих изменить механизм сортировки. Обязательно загляните на страницу руководства, чтобы увидеть все, на что он способен.
Синтаксис:
sort [-options] [путь]
5. uniq: Удаляет повторяющиеся строки. У uniq есть ограничение, заключающееся в том, что он может удалять только непрерывные повторяющиеся строки (хотя это можно исправить с помощью конвейера). Предполагая, что у нас есть следующие данные.
Синтаксис:
uniq [параметры] [путь]
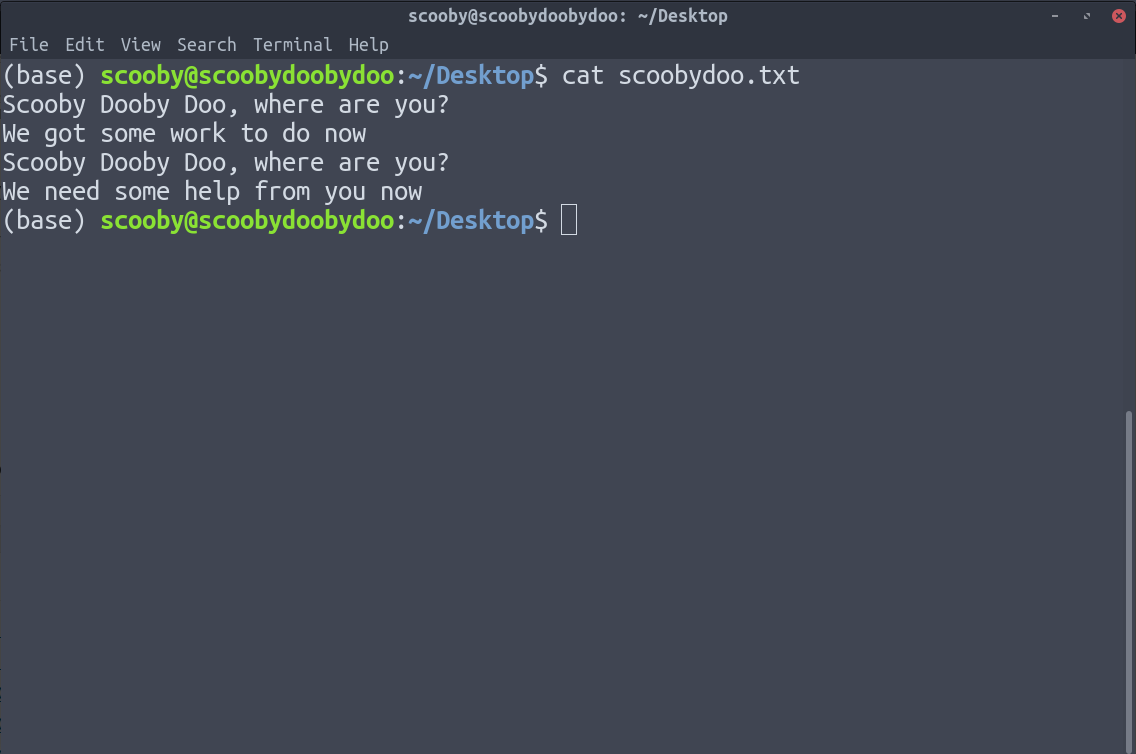
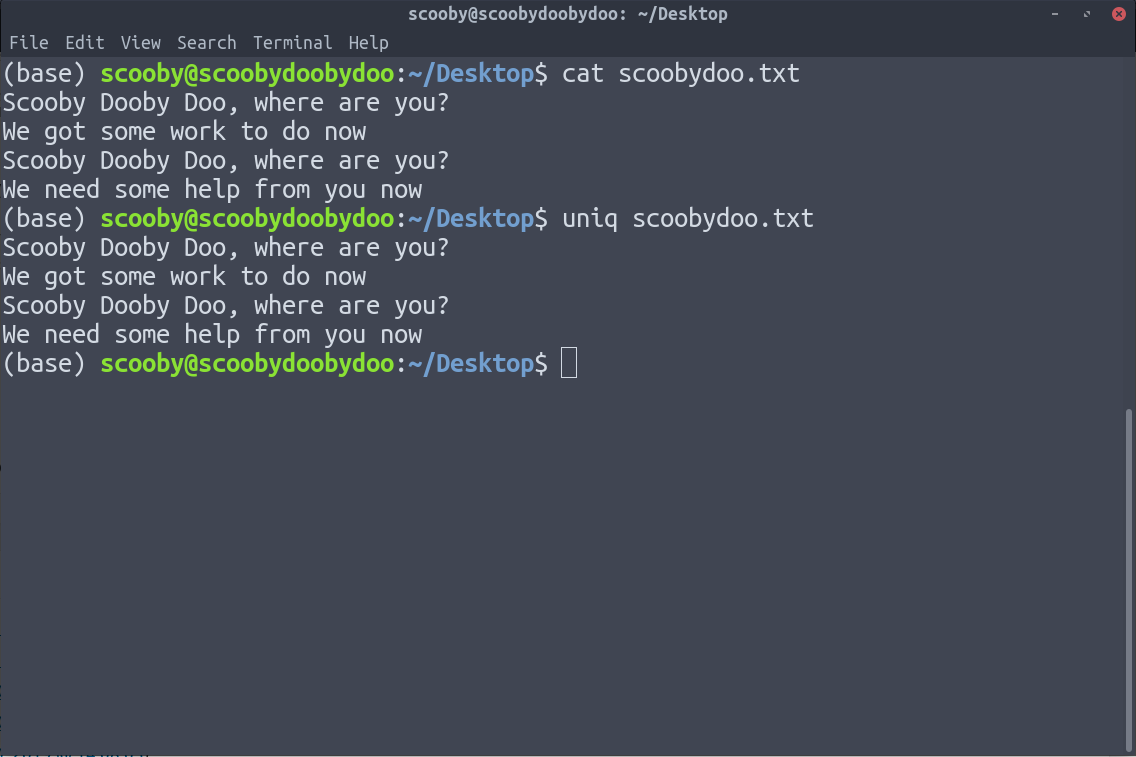
Вы можете видеть, что применение uniq не удаляет повторяющиеся строки, потому что uniq удаляет только повторяющиеся строки, которые находятся вместе.
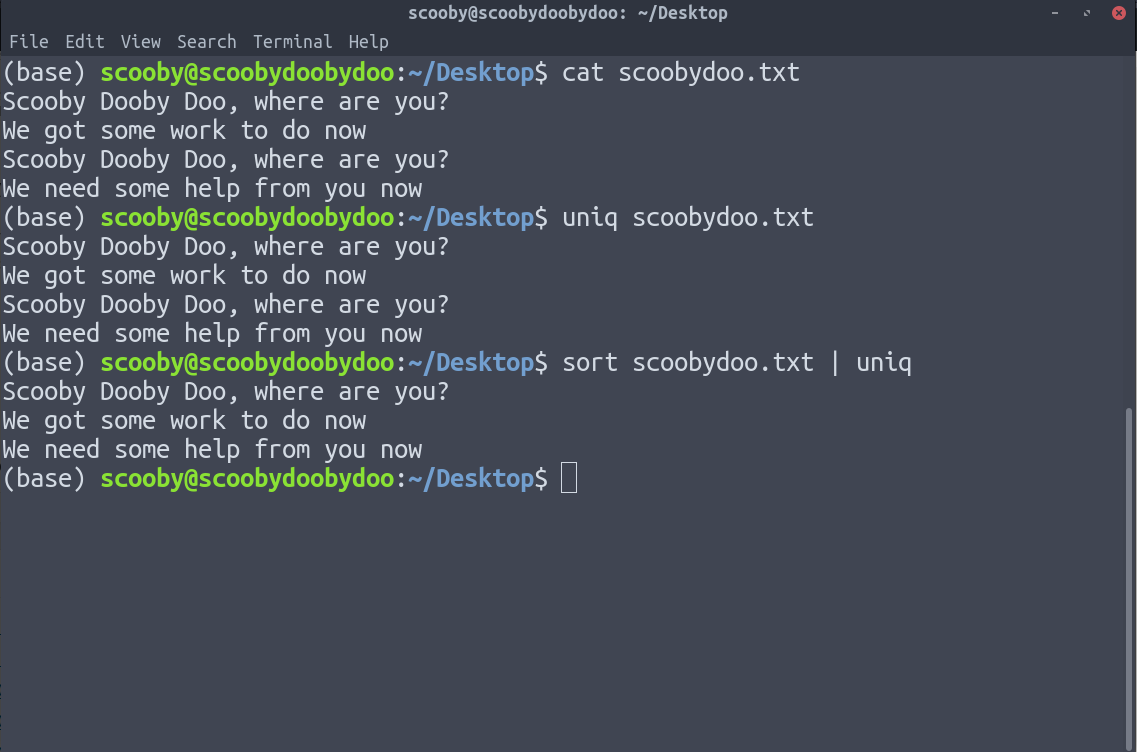
При применении uniq к отсортированным данным он удаляет повторяющиеся строки, потому что после сортировки данных повторяющиеся строки объединяются.
6. Команда wc: wc выдает количество строк, слов и символов в данных.
Синтаксис:
wc [-options] [путь]
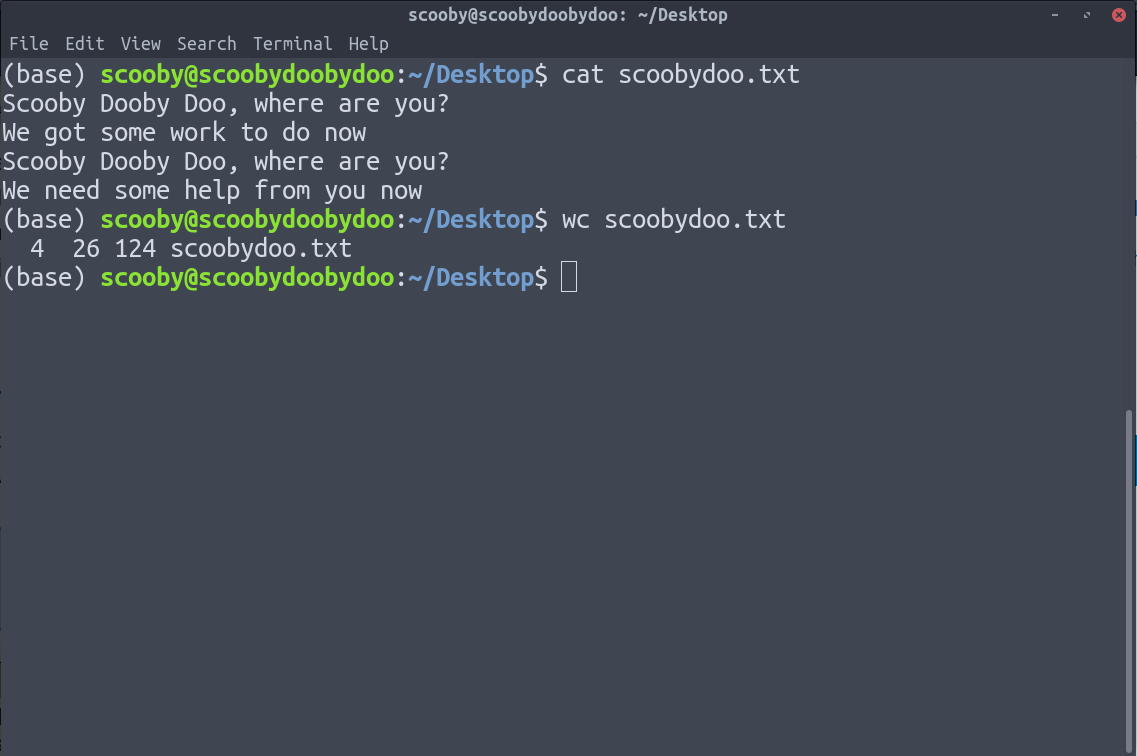
На изображении выше wc дает 4 вывода как:
- количество строк
- число слов
- количество символов
- дорожка
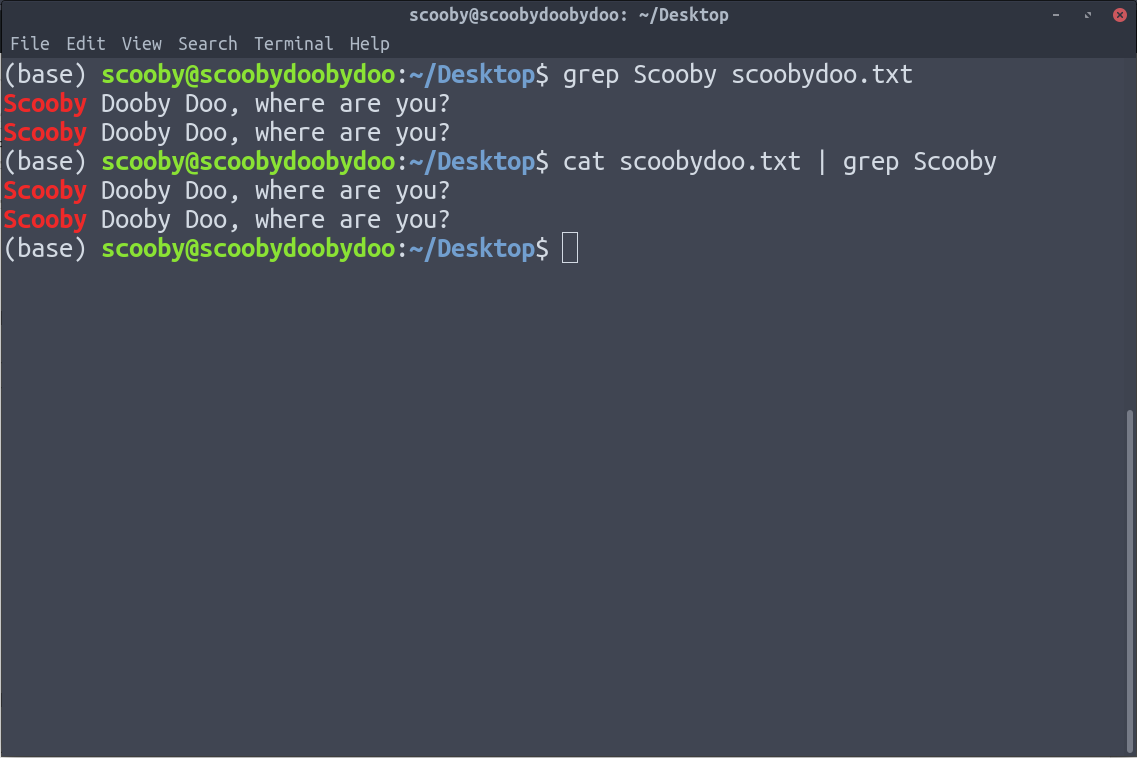
7. grep: grep используется для поиска определенной информации в текстовом файле.
Синтаксис:
grep [параметры] шаблон [путь]
Ниже приведены два способа реализации grep.
8. tac: tac - это полная противоположность cat и работает таким же образом, то есть вместо печати строк с 1 по n, он печатает строки с n по 1. Это просто обратная команда cat.
Синтаксис:
tac [путь]
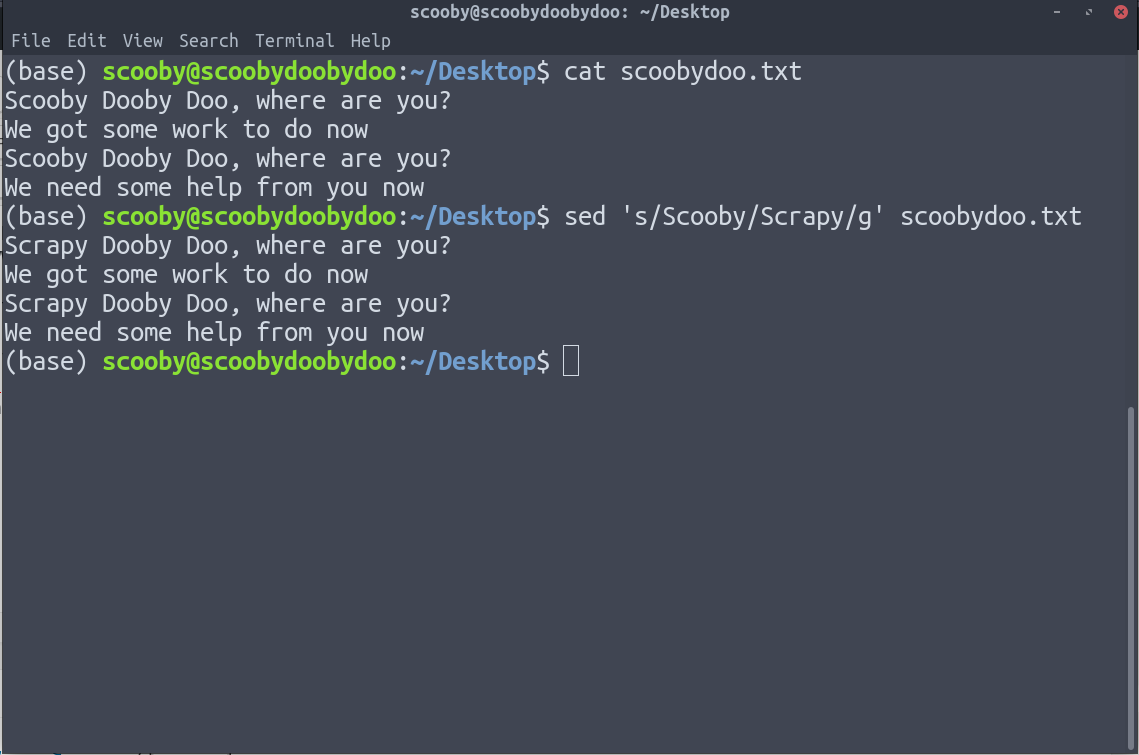
9. sed: sed означает редактор потока. Это позволяет нам эффективно применять операцию поиска и замены к нашим данным. sed - довольно продвинутый фильтр, и все его параметры можно увидеть на его странице руководства.
Синтаксис:
sed [путь]
Выражение, которое мы использовали выше, очень простое и имеет форму s / search / replace / g.
На изображении выше мы можем ясно видеть, что Scooby заменен Scrapy.
10. nl: nl используется для нумерации строк наших текстовых данных.
Синтаксис:
nl [-options] [путь]
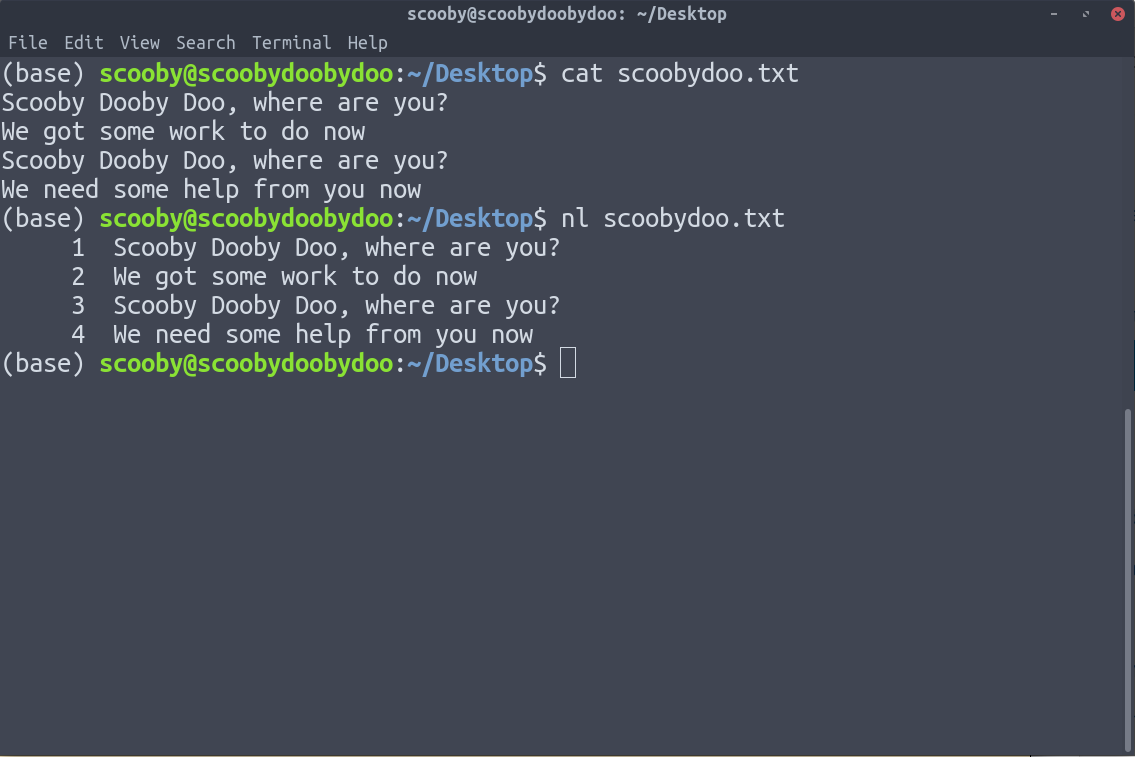
На изображении выше ясно видно, что линии пронумерованы.