Что такое Data Science?
Наука о данных - это междисциплинарная область, которая фокусируется на извлечении знаний из наборов данных, которые обычно огромны. Эта область включает анализ, подготовку данных для анализа и представление результатов для принятия решений на высоком уровне в организации. Таким образом, он включает в себя навыки из информатики, математики, статики, визуализации информации, графики и бизнеса.
Решение проблемы
Данные есть повсюду и являются одной из важнейших характеристик каждой организации, которая помогает бизнесу процветать, принимая решения на основе фактов, статистических данных и тенденций. Благодаря такому растущему объему данных появилась наука о данных, которая является междисциплинарной ИТ-областью, и работа специалистов по данным является самой востребованной в 21 веке. Анализ данных / Наука о данных помогает нам получать ответы на вопросы из данных. Наука о данных и, по сути, анализ данных играет важную роль, помогая нам находить полезную информацию из данных, отвечать на вопросы и даже предсказывать будущее или неизвестное. Он использует научные подходы, процедуры, алгоритмы, основу для извлечения знаний и понимания из огромного количества данных.
Наука о данных - это концепция, объединяющая идеи, анализ данных, машинное обучение и связанные с ними стратегии для понимания и анализа реальных явлений с помощью данных. Это расширение областей анализа данных, таких как интеллектуальный анализ данных, статистика, прогнозный анализ. Это огромная область, в которой используется множество методов и концепций, которые относятся к другим областям, таким как информатика, статистика, математика и информатика. Некоторые из методов, используемых в Data Science, включают машинное обучение, визуализацию, распознавание образов, вероятностную модель, инженерию данных, обработку сигналов и т. Д.
Несколько важных шагов, которые помогут вам более успешно работать с проектами в области науки о данных:
- Постановка цели исследования: понимание бизнеса или деятельности, частью которой является наш проект по науке о данных, является ключом к обеспечению его успеха и первой фазы любого надежного проекта по анализу данных. Первоочередной задачей является определение того, что, почему и как для нашего проекта в уставе проекта. Теперь сядьте, чтобы определить график и конкретные ключевые показатели эффективности, и это важный первый шаг к запуску нашей инициативы в области данных!
- Получение данных: следующий шаг - поиск данных, необходимых в нашем проекте, и получение доступа к ним. Смешивание и объединение данных из максимально возможного количества источников данных - вот что делает проект данных отличным, так что смотрите как можно дальше. Эти данные либо находятся внутри компании, либо получаются от третьих лиц. Итак, вот несколько способов получить полезные данные: подключение к базе данных, использование API или поиск открытых данных.
- Подготовка данных: следующий шаг в области науки о данных - это ужасный процесс подготовки данных, который обычно занимает до 80% времени, посвященного нашему проекту данных. Проверка и исправление ошибок данных, обогащение данных данными из других источников данных и преобразование их в подходящий формат для ваших моделей.
- Исследование данных: теперь, когда мы очистили наши данные, пришло время манипулировать ими, чтобы извлечь из них максимальную пользу. Мы исследуем наши данные глубже, используя описательную статистику и визуальные методы. Одним из примеров этого является обогащение наших данных путем создания функций на основе времени, таких как: извлечение компонентов даты (месяц, час, день недели, неделя года и т. Д.), Вычисление разницы между столбцами даты или отметка национальных праздников. . Другой способ обогащения данных - объединение наборов данных - по сути, извлечение столбцов из одного набора данных или вкладки в эталонный набор данных.
- Презентация и автоматизация: представление наших результатов заинтересованным сторонам и индустриализация нашего процесса анализа для многократного повторного использования и интеграции с другими инструментами. Когда мы имеем дело с большими объемами данных, визуализация - лучший способ изучить и сообщить о наших выводах и является следующим этапом нашего проекта по анализу данных.
- Моделирование данных: использование машинного обучения и статистических методов - это шаг к дальнейшему достижению цели нашего проекта и прогнозированию будущих тенденций. Работая с алгоритмами кластеризации, мы можем создавать модели для выявления тенденций в данных, которые нельзя было различить на графиках и в статистике. Они создают группы похожих событий (или кластеров) и более или менее явно выражают, какая особенность является решающей в этих результатах.
Почему Data Scientist?
Специалисты по обработке данных работают в мире бизнеса и ИТ и обладают уникальными навыками. Их роль приобрела значимость благодаря тому, как сегодня компании относятся к большим данным. Бизнес хочет использовать неструктурированные данные, которые могут увеличить их доход. Специалисты по обработке данных анализируют эту информацию, чтобы разобраться в ней и получить бизнес-идеи, которые помогут в росте бизнеса.
Пакеты Python для науки о данных
Теперь давайте начнем с главной темы, то есть с пакетов Python для науки о данных, которые станут отправной точкой для начала нашего путешествия по науке о данных. Библиотека Python - это набор функций и методов, которые позволяют нам выполнять множество действий без написания кода.
1. Научно-вычислительные библиотеки:
- Pandas - это двумерная потенциально неоднородная структура табличных данных с изменяемым размером и помеченной осью. Он предлагает структуры данных и инструменты для эффективного управления и анализа. Обеспечивает быстрый доступ к структурированным данным.
Пример:
importpandas as pdlst=['I','Love','Data','Science']df=pd.DataFrame(lst)print(df)Выход:
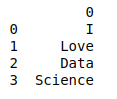
- Numpy - он использует массивы для своих входов и выходов. Его можно распространить на объекты для матриц. Это позволяет разработчикам выполнять быструю обработку массивов с незначительными изменениями кода.
Пример:
importnumpy as nparr=np.array ([[1,2,3], [4,6,8]])print("Array is of type: ",type(arr))print("No. od dimensions:", arr.ndim)print("Shape of array: ", arr.shape)Выход:
Массив имеет тип: <class 'numpy.ndarray'> Кол-во размеров: 2 Форма массива: (2, 3)
- Scipy - это библиотека на основе Python с открытым исходным кодом. Он работает для некоторых сложных математических задач - интегралов, дифференциальных уравнений, оптимизации и визуализации данных. Он прост в использовании и понимании, а также отличается высокой вычислительной мощностью.
Пример:
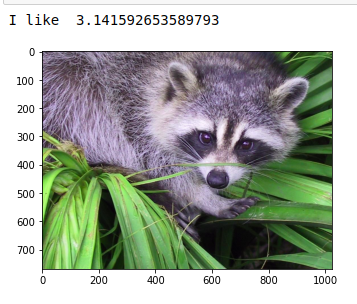
importnumpy as npfromscipyimportmiscimportmatplotlib.pyplot as pltprint("I like ", np.pi)face=misc.face()plt.imshow(face)plt.show()Выход:
2. Библиотеки визуализации:
- Matplotlib - предоставляет объектно-ориентированный API для встраивания графиков в приложения. Каждая функция pyplot вносит некоторые изменения в фигуру. Он создает фигуру или область построения на фигуре, вычерчивает некоторые линии в области построения.
Пример:
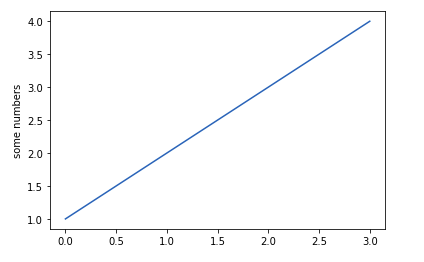
importmatplotlib.pyplot as pltplt.plot([1,2,3,4])plt.ylabel('some numbers')plt.show()Выход:
- Seaborn - используется для создания статистических графиков. Он предоставляет высокоуровневый интерфейс для рисования привлекательной и информативной графики. Это очень легко сгенерировать в различных сюжетах, таких как карты кучи, командные серии, сюжеты для скрипки.
Пример:
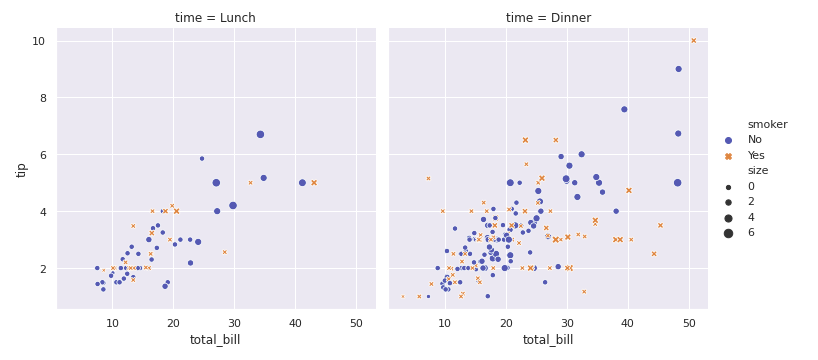
importseaborn as snssns.set()tips=sns.load_dataset("tips")sns.relplot(x="total_bill",y="tip",col="time",hue="smoker",style="smoker",size="size",data=tips);Выход:
3. Алгоритмические библиотеки:
- Scikit learn - предоставляет статистическое моделирование, включая регрессию, классификацию, кластеризацию. Это бесплатная библиотека машинного обучения для программирования на Python. Он использует NumPy для высокопроизводительных операций с линейной алгеброй и массивами.
Пример:
fromdatasetsimportsklearniris=datasets.load_iris( )digits=datasets.load_digits( )print(digits)Выход:
{‘data’: array([[ 0., 0., 5., …, 0., 0., 0.],
[ 0., 0., 0., …, 10., 0., 0.],
[ 0., 0., 0., …, 16., 9., 0.],
…,
[ 0., 0., 1., …, 6., 0., 0.],
[ 0., 0., 2., …, 12., 0., 0.],
[ 0., 0., 10., …, 12., 1., 0.]]), ‘target’: array([0, 1, 2, …, 8, 9, 8]), ‘target_names’: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), ‘images’: array([[[ 0., 0., 5., …, 1., 0., 0.],
[ 0., 0., 13., …, 15., 5., 0.],
[ 0., 3., 15., …, 11., 8., 0.],
…,
[ 0., 4., 11., …, 12., 7., 0.],
[ 0., 2., 14., …, 12., 0., 0.],
[ 0., 0., 6., …, 0., 0., 0.]],[[ 0., 0., 0., …, 5., 0., 0.],
[ 0., 0., 0., …, 9., 0., 0.],
[ 0., 0., 3., …, 6., 0., 0.],
…,
[ 0., 0., 1., …, 6., 0., 0.],
[ 0., 0., 1., …, 6., 0., 0.],
[ 0., 0., 0., …, 10., 0., 0.]],[[ 0., 0., 0., …, 12., 0., 0.],
[ 0., 0., 3., …, 14., 0., 0.],
[ 0., 0., 8., …, 16., 0., 0.],
…,
[ 0., 9., 16., …, 0., 0., 0.],
[ 0., 3., 13., …, 11., 5., 0.],
[ 0., 0., 0., …, 16., 9., 0.]],…,
[[ 0., 0., 1., …, 1., 0., 0.],
[ 0., 0., 13., …, 2., 1., 0.],
[ 0., 0., 16., …, 16., 5., 0.],
…,
[ 0., 0., 16., …, 15., 0., 0.],
[ 0., 0., 15., …, 16., 0., 0.],
[ 0., 0., 2., …, 6., 0., 0.]],[[ 0., 0., 2., …, 0., 0., 0.],
[ 0., 0., 14., …, 15., 1., 0.],
[ 0., 4., 16., …, 16., 7., 0.],
…,
[ 0., 0., 0., …, 16., 2., 0.],
[ 0., 0., 4., …, 16., 2., 0.],
[ 0., 0., 5., …, 12., 0., 0.]],[[ 0., 0., 10., …, 1., 0., 0.],
[ 0., 2., 16., …, 1., 0., 0.],
[ 0., 0., 15., …, 15., 0., 0.],
…,
[ 0., 4., 16., …, 16., 6., 0.],
[ 0., 8., 16., …, 16., 8., 0.],
[ 0., 1., 8., …, 12., 1., 0.]]]), ‘DESCR’: “.. _digits_dataset: Optical recognition of handwritten digits dataset ————————————————– **Data Set Characteristics:** :Number of Instances: 5620 :Number of Attributes: 64 :Attribute Information: 8×8 image of integer pixels in the range 0..16. :Missing Attribute Values: None :Creator: E. Alpaydin (alpaydin ‘@’ boun.edu.tr) :Date: July; 1998 This is a copy of the test set of the UCI ML hand-written digits datasets https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits The data set contains images of hand-written digits: 10 classes where each class refers to a digit. Preprocessing programs made available by NIST were used to extract normalized bitmaps of handwritten digits from a preprinted form. From a total of 43 people, 30 contributed to the training set and different 13 to the test set. 32×32 bitmaps are divided into nonoverlapping blocks of 4x4 and the number of on pixels are counted in each block. This generates an input matrix of 8×8 where each element is an integer in the range 0..16. This reduces dimensionality and gives invariance to small distortions. For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G. T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C. L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469, 1994. .. topic:: References – C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their Applications to Handwritten Digit Recognition, MSc Thesis, Institute of Graduate Studies in Science and Engineering, Bogazici University. – E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika. – Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin. Linear dimensionalityreduction using relevance weighted LDA. School of Electrical and Electronic Engineering Nanyang Technological University. 2005. – Claudio Gentile. A New Approximate Maximal Margin Classification Algorithm. NIPS. 2000.”} - Модель статистики - построена на NumPy и SciPy. Он позволяет пользователям исследовать данные, оценивать статистические модели и выполнять тесты. Он также использует Pandas для обработки данных и Patsy для интерфейса R-подобных формул.
Пример:
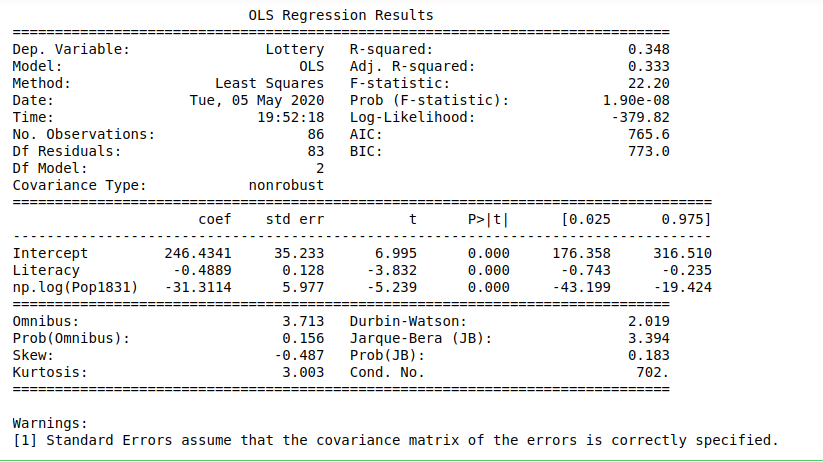
importnumpy as npimportstatsmodels.api as smimportstatsmodels.formula.api as smfdat=sm.datasets.get_rdataset("Guerry","HistData").dataresults=smf.ols('Lottery ~ Literacy + np.log(Pop1831)',data=dat).fit()print(results.summary())Выход:
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.