Агрегатно-ориентированные базы данных в NoSQL
Агрегатно-ориентированная база данных — это база данных NoSQL, которая не поддерживает транзакции ACID и жертвует одним из свойств ACID. Операции агрегатной ориентации отличаются от операций с реляционной базой данных. Мы можем выполнять операции OLAP в базе данных, ориентированной на агрегаты. Эффективность базы данных, ориентированной на агрегаты, высока, если транзакции и взаимодействия с данными происходят в одном и том же агрегате. Несколько полей данных могут быть помещены в агрегаты, чтобы к ним можно было получить общий доступ вместе. Мы можем манипулировать только одним агрегатом за раз. Мы не можем манипулировать несколькими агрегатами одновременно атомарным образом.
Агрегатно-ориентированные базы данных подразделяются на четыре основные модели данных. Они следующие:
- Ключ-значение
- Документ
- Семейство столбцов
- на основе графика
Каждая из приведенных выше моделей данных имеет собственный язык запросов.
- Модель данных «ключ-значение»: базы данных «ключ-значение» и документы были строго ориентированы на агрегаты. Модель данных "ключ-значение" содержит ключ или идентификатор, который используется для доступа к данным агрегатов. Модель данных "ключ-значение" очень безопасна, поскольку агрегаты непрозрачны для базы данных. Агрегаты шифруются как большой блок битов, которые можно расшифровать с помощью ключа или идентификатора. В модели данных «ключ-значение» мы можем размещать в ней данные любой структуры и типа данных. Преимущество модели данных «ключ-значение» заключается в том, что мы можем хранить конфиденциальную информацию в совокупности. Но недостатком этой модели является то, что база данных имеет некоторые общие ограничения по размеру. Мы можем хранить только ограниченные данные.
- Модель данных документа: в модели данных документа мы можем получить доступ к частям агрегатов. Доступ к данным в этой модели может быть негибким. мы можем отправлять запросы в базу данных на основе полей в совокупности. В этой модели данных существует ограничение на структуру и типы данных, подлежащих стимуляции. Доступ к структуре агрегата можно получить с помощью модели данных документа.
- Модель данных семейства столбцов: семейство столбцов также называют двухуровневой картой. Но, тем не менее, мы думаем о структуре, это была модель, которая повлияла на более поздние базы данных, такие как HBase и Cassandra. Эти базы данных с большой табличной моделью данных часто называют хранилищами столбцов. Модели семейства столбцов делят совокупность на семейства столбцов. Модель семейства столбцов представляет собой двухуровневую совокупную структуру. Первый уровень состоит из ключей, которые действуют как идентификатор строки, выбирающий агрегат. Значения второго уровня в модели данных семейства столбцов называются столбцами.
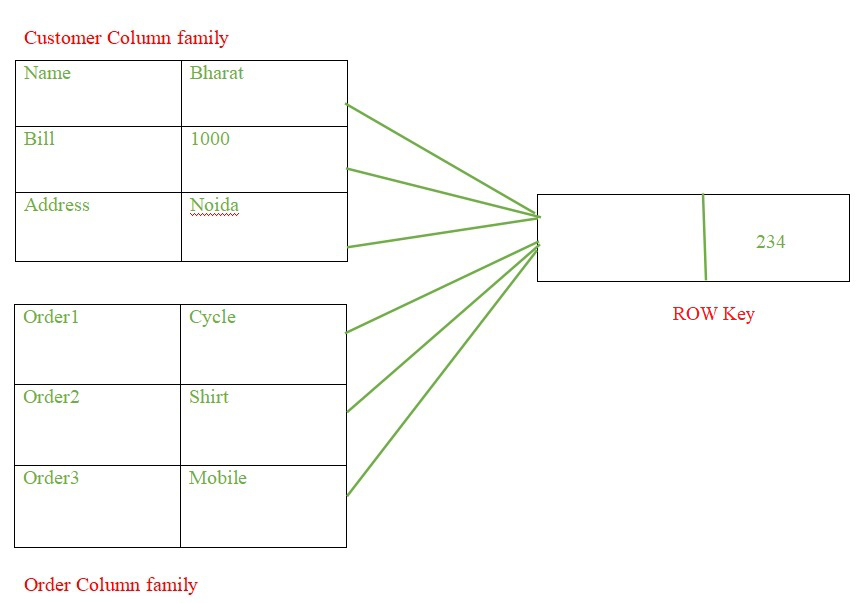
- В приведенном выше примере ключом строки является 234, который выбирает агрегат. Здесь клавиша строки выбирает семейства столбцов клиентов и заказов. Каждое семейство столбцов содержит столбцы данных. В семействе столбцов заказов у нас есть заказы, размещенные клиентами.
- Модель данных графа. В модели данных графа данные хранятся в узлах, соединенных ребрами. Эта модель предпочтительна для хранения огромного количества сложных агрегатов и многомерных данных со множеством взаимосвязей между ними. Модель графических данных имеет такое приложение, как мы можем хранить учетные записи пользователей Facebook в узлах и узнавать друзей конкретного пользователя, следуя краям графа.
Мы можем найти друзей человека, наблюдая за этой графовой моделью данных. Если между двумя узлами есть ребро, мы можем сказать, что они друзья. Здесь мы также рассматриваем косвенные связи между узлами, чтобы определить предложения друзей.