4 причины, по которым качественная дедупликация важна для операций резервного копирования

Меня даже по сей день несколько удивляет, как много ИТ-специалистов и менеджеров по закупкам смотрят на позицию на листе бумаги и думают про себя: «Все технологии дедупликации созданы равными». Я полагаю, что на заре технологии это было правдой, но, как и любая функция в ИТ, все меняется. Разработчики создают новые функции, функции и инновации, и этот процесс также применим к дедупликации. Возможно, есть несколько областей хранения данных, которые более важны, чем ваше хранилище резервных копий, поэтому сегодня в этой статье мы рассмотрим дедупликацию через призму хранения резервных копий.
Когда я разговариваю с ИТ-специалистами, мне кажется, что я всегда возвращаюсь к четырем основным моментам относительно того, почему наличие качественной дедупликации в вашей среде резервного копирования имеет большое значение. Да, я, вероятно, мог бы рассказать больше об этом, но в целом большинство пунктов, похоже, попадают в одну из следующих категорий:
– Экономия и повышение эффективности хранения благодаря дедупликации.
– Влияние дедупликации на производительность
– Безопасность данных
– Цели дедупликации
Каждый пункт важен, и они не обязательно ранжируются по степени важности. Тем не менее, я хотел бы рассмотреть каждый пункт в отдельности. Итак, давайте посмотрим.
Экономия и эффективность хранилища благодаря дедупликации
Вероятно, именно это подумает большинство людей, когда я упомяну слово «дедупликация». Уменьшение объема хранилища — это, по сути, основная функция технологий дедупликации. Короче говоря, если вы думаете о том, что в вашей организации будут выполняться резервное копирование и хранение одинаковых данных, хранить их дважды не имеет особого смысла, верно? Цель Dedupe — найти подобные данные и убедиться, что сохраняется только одна копия, а остальные удаляются. Однако важно то, как происходит этот процесс.
Файловая дедупликация
Старые методы дедупликации основывались на файлах. Они будут запрашивать отдельные файлы в файловой системе и на основе полученной информации будут следить за тем, чтобы идентичный файл не сохранялся во второй раз. Однако дедупликация на основе файлов не так эффективна. Большая часть файла может быть идентична другим файлам в системе, даже если файл называется по-другому, имеет другую отметку времени или содержит некоторые другие различия на уровне файла, которые требуют пометки его как уникального. Вы обнаружите, что из-за этого многие данные будут сохраняться больше раз, чем это действительно необходимо, потому что механизм дедупликации недостаточно умен, чтобы действительно понимать сами данные. Именно здесь на сцену вышла дедупликация на уровне блоков.
Дедупликация на уровне блоков
Дедупликация на уровне блоков проникает под файлы. Он просматривает необработанные блоки данных в самой файловой системе. При этом он может более точно понять тип данных, содержащихся в данном блоке, не беспокоясь об общем «файле», частью которого является данный блок. Что это означает с точки зрения хранилища, так это более точное обнаружение похожих данных, что приводит к экономии места на целевом объекте резервного копирования. В качестве примера я включил описание того, как этот процесс работает в нашем собственном приложении для резервного копирования, Altaro VM Backup. Слева направо вы можете увидеть, как блоки сначала разбиваются на виртуальную машину (ВМ), а затем на другие виртуальные машины, прежде чем в конечном итоге сжимаются и сохраняются.
Этот метод обеспечивает лучшую в своем классе экономию резервного хранилища не только для данной виртуальной машины, но и для всех резервных копий виртуальных машин, что позволяет выполнять резервное копирование чаще и чаще без необходимости приобретать дополнительное хранилище.
Влияние дедупликации на производительность
Другая сторона медали «дедупликации» — производительность. Ранние версии технологий дедупликации были ресурсоемкими. Добавленная перегрузка диска часто не стоила экономии памяти. Это произошло по разным причинам. Для дедупликации на основе файлов требуется больше системных циклов, чем для дедупликации на уровне блоков, поэтому, просто используя технологию дедупликации на уровне блоков, вы ставите себя впереди игры. Тем не менее, еще одна вещь, на которую следует обратить внимание, — это где в процессе происходит дедупликация? Обычно все сводится к двум вариантам:
Постпроцессная дедупликация
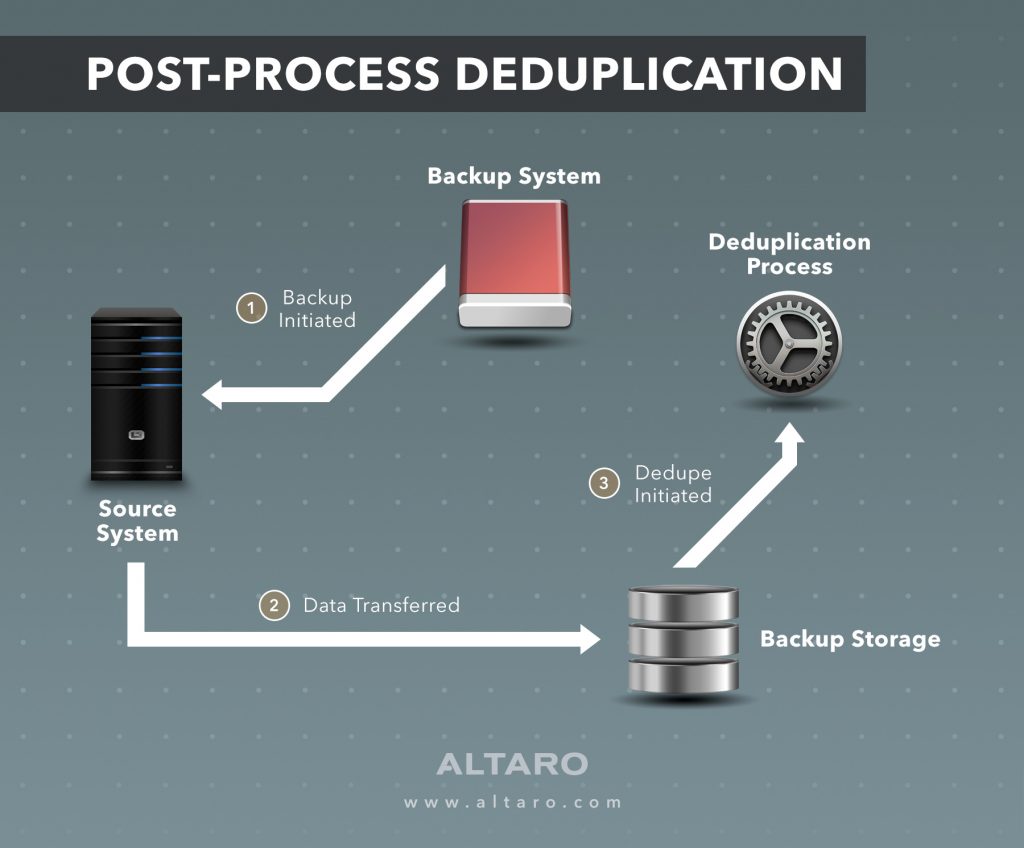
Постпроцессная дедупликация — это действие по дедупликации полезной нагрузки после ее копирования в хранилище резервных копий. Вспомните, насколько недружественными были старые технологии дедупликации при загрузке системы. Мыслительный процесс здесь заключался в том, чтобы как можно скорее скопировать данные (включая аналогичные данные), чтобы рабочие серверы и система резервного копирования не увязли в этом процессе. После задания копирования вторичное устройство или сервер будет затем анализировать все данные и дедуплицировать их в месте хранения.
С этим подходом возник ряд проблем. Во-первых, вы многократно копируете данные, которые не нужно копировать. Во-вторых, вы усложняете свою среду, требуя наличия устройства или выделенного оборудования для дедупликации после обработки. Вот где вступает в действие встроенный дедупликатор.
Встроенная дедупликация
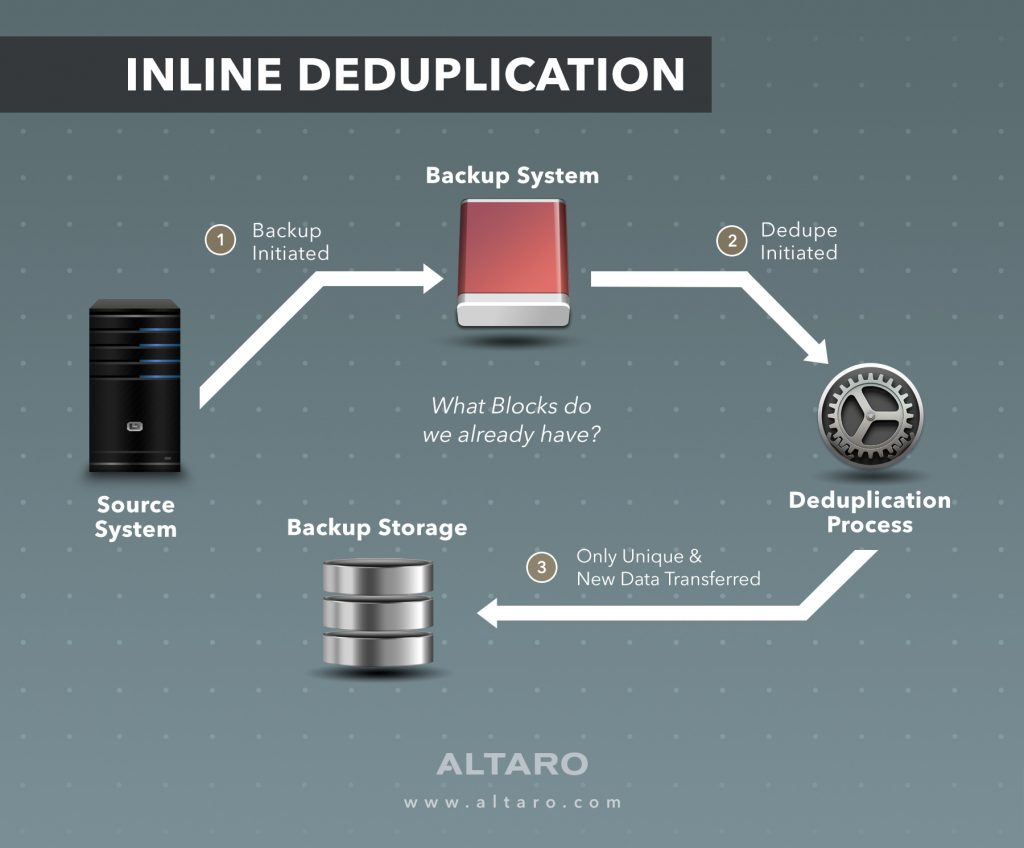
Встроенная дедупликация более интеллектуальна, поскольку она сначала использует комбинацию функций, чтобы определить перед процессом копирования, какие блоки действительно должны перемещаться по сети. Например, Altaro VM Backup хранит базу данных защищенных блоков. Это в основном список блоков, которые уже были зарезервированы. Когда происходит процесс резервного копирования, эта база данных запрашивается, и, если блок новый, он отправляется по сети в хранилище резервных копий. Если он не новый, процесс резервного копирования игнорирует его, и жизнь продолжается.
Этот метод служит не только для обеспечения защиты уникальных данных, но и для сокращения времени резервного копирования. Этот процесс стал настолько эффективным, что на его выполнение таким образом требуется меньше времени, чем на простое копирование полезной нагрузки и последующую дедупликацию.
Безопасность данных
Это само собой разумеется, но вам нужна технология дедупликации, которой вы можете доверять, чтобы не повредить ваши данные. Когда у вас есть автоматизированная система, решающая, какие данные остаются, а какие удаляются, вы хотите убедиться, что это качественное программное обеспечение. Большинство механизмов дедупликации выполняют собственные внутренние проверки работоспособности, но какую бы технологию дедупликации ни использовало ваше программное обеспечение для резервного копирования, вам необходимо проверить несколько вещей самостоятельно, чтобы быть в безопасности:
- Регулярно выполняется процесс проверки работоспособности данных.
- Этот процесс проверки работоспособности должен быть самовосстанавливающимся, если это возможно.
- Все защищенные блоки должны быть восстанавливаемы со всех определенных периодов времени в течение срока хранения.
- Регулярное тестирование восстановления должно быть запланировано и автоматизировано для обеспечения жизнеспособности данных.
Следование этим пунктам поможет вам следить за состоянием данных после процесса дедупликации и убедиться, что это не повредит данные резервного копирования непреднамеренно.
Правильные цели дедупликации
Это может показаться глупым, но на самом деле это вопрос. Ищет ли дедупликация похожие блоки в одной системе или в хранилище? Если это внутри одной системы, вы по-прежнему храните аналогичные данные в нескольких системах. Если ваш механизм дедупликации работает на уровне целевого хранилища, то он выполняет дедупликацию блоков для всех данных, хранящихся в этом месте. Последнее, очевидно, является наиболее эффективным, и именно так будет работать Altaro VM Backup. Какого бы поставщика вы ни использовали, вы должны убедиться, что он также использует этот метод для максимальной эффективности.
Задавайте правильные вопросы
Как видите, есть много вопросов, которые нужно задать по поводу вашего выбора дедупликации. Все эти вопросы связаны с механизмом дедупликации, который:
- Обеспечивает большую эффективность хранения
– Не монополизирует системные ресурсы
– Обеспечивает безопасность данных
– Дедупликация схожих данных между рабочими нагрузками
Используя хороший выбор в этой технологической области, вы в конечном итоге сможете делать больше с меньшими затратами, поддерживать работоспособность своих производственных систем во время их использования и меньше головной боли на протяжении всего процесса. Как уже говорилось, наличие качественной дедупликации имеет большое значение.
Бонус (если вам нужна лучшая дедупликация для вашей виртуальной среды)
Так много пользователей Altaro VM Backup уже сэкономили на хранилище благодаря функции расширенной встроенной дедупликации. Узнайте, что они говорят здесь, и если вы хотите увидеть, насколько хорошо расширенная встроенная дедупликация Altaro VM Backup будет работать и для вас, загрузите бесплатную 30-дневную пробную версию Altaro VM Backup сегодня.