Умножение матрицы с помощью потоков
Разумеется, умножение матрицы требует времени. Временная сложность умножения матриц составляет O (n ^ 3) с использованием обычного умножения матриц. И алгоритм Штрассена улучшает его, и его временная сложность составляет O (n ^ (2.8074)).
Но есть ли способ улучшить производительность умножения матриц с помощью обычного метода.
Для его улучшения можно использовать многопоточность. В многопоточности вместо использования одного ядра вашего процессора мы используем все или несколько ядер для решения проблемы.
Мы создаем разные потоки, каждый поток оценивает некоторую часть умножения матриц.
В зависимости от количества ядер вашего процессора вы можете создать необходимое количество потоков. Хотя вы можете создать столько потоков, сколько вам нужно, лучший способ - создать каждый поток для одного ядра.
Во втором подходе мы создаем отдельный поток для каждого элемента в результирующей матрице. Используя pthread_exit (), мы возвращаем вычисленное значение из каждого потока, которое собирает pthread_join () . В этом подходе не используются глобальные переменные.
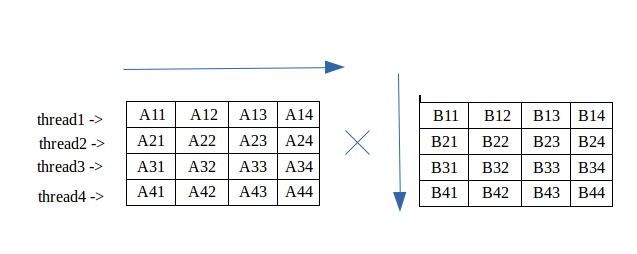
Примеры:
Вход : Матрица А 1 0 0 0 1 0 0 0 1 Матрица B 2 3 2 4 5 1 7 8 6 Выход: умножение A и B 2 3 2 4 5 1 7 8 6
Рекомендуется: сначала попробуйте свой подход в {IDE}, прежде чем переходить к решению.
NOTE* It is advised to execute the program in linux based system
Compile in linux using following code:
g++ -pthread program_name.cpp
// CPP Program to multiply two matrix using pthreads#include <bits/stdc++.h>using namespace std; // maximum size of matrix#define MAX 4 // maximum number of threads#define MAX_THREAD 4 int matA[MAX][MAX];int matB[MAX][MAX];int matC[MAX][MAX];int step_i = 0; void* multi(void* arg){ int core = step_i++; // Each thread computes 1/4th of matrix multiplication for (int i = core * MAX / 4; i < (core + 1) * MAX / 4; i++) for (int j = 0; j < MAX; j++) for (int k = 0; k < MAX; k++) matC[i][j] += matA[i][k] * matB[k][j];} // Driver Codeint main(){ // Generating random values in matA and matB for (int i = 0; i < MAX; i++) { for (int j = 0; j < MAX; j++) { matA[i][j] = rand() % 10; matB[i][j] = rand() % 10; } } // Displaying matA cout << endl << "Matrix A" << endl; for (int i = 0; i < MAX; i++) { for (int j = 0; j < MAX; j++) cout << matA[i][j] << " "; cout << endl; } // Displaying matB cout << endl << "Matrix B" << endl; for (int i = 0; i < MAX; i++) { for (int j = 0; j < MAX; j++) cout << matB[i][j] << " "; cout << endl; } // declaring four threads pthread_t threads[MAX_THREAD]; // Creating four threads, each evaluating its own part for (int i = 0; i < MAX_THREAD; i++) { int* p; pthread_create(&threads[i], NULL, multi, (void*)(p)); } // joining and waiting for all threads to complete for (int i = 0; i < MAX_THREAD; i++) pthread_join(threads[i], NULL); // Displaying the result matrix cout << endl << "Multiplication of A and B" << endl; for (int i = 0; i < MAX; i++) { for (int j = 0; j < MAX; j++) cout << matC[i][j] << " "; cout << endl; } return 0;} |
Выход:
Матрица А 3 7 3 6 9 2 0 3 0 2 1 7 2 2 7 9 Матрица B 6 5 5 2 1 7 9 6 6 6 8 9 0 3 5 2 Умножение A и B 43 100 132 87 56 68 78 36 8 41 61 35 56 93 129 97
Подход без использования глобальных переменных:
NOTE* It is advised to execute the program in linux based system
Compile in linux using following code:
g++ -pthread program_name.cpp
// C Program to multiply two matrix using pthreads without // use of global variables #include<stdio.h>#include<pthread.h>#include<unistd.h>#include<stdlib.h>#define MAX 4 //Each thread computes single element in the resultant matrixvoid *mult(void* arg){ int *data = (int *)arg; int k = 0, i = 0; int x = data[0]; for (i = 1; i <= x; i++) k += data[i]*data[i+x]; int *p = (int*)malloc(sizeof(int)); *p = k; //Used to terminate a thread and the return value is passed as a pointer pthread_exit(p);} //Driver codeint main(){ int matA[MAX][MAX]; int matB[MAX][MAX]; int r1=MAX,c1=MAX,r2=MAX,c2=MAX,i,j,k; // Generating random values in matA for (i = 0; i < r1; i++) for (j = 0; j < c1; j++) matA[i][j] = rand() % 10; // Generating random values in matB for (i = 0; i < r1; i++) for (j = 0; j < c1; j++) matB[i][j] = rand() % 10; // Displaying matA for (i = 0; i < r1; i++){ for(j = 0; j < c1; j++) printf("%d ",matA[i][j]); printf("
"); } // Displaying matB for (i = 0; i < r2; i++){ for(j = 0; j < c2; j++) printf("%d ",matB[i][j]); printf("
"); } int max = r1*c2; //declaring array of threads of size r1*c2 pthread_t *threads; threads = (pthread_t*)malloc(max*sizeof(pthread_t)); int count = 0; int* data = NULL; for (i = 0; i < r1; i++) for (j = 0; j < c2; j++) { //storing row and column elements in data data = (int *)malloc((20)*sizeof(int)); data[0] = c1; for (k = 0; k < c1; k++) data[k+1] = matA[i][k]; for (k = 0; k < r2; k++) data[k+c1+1] = matB[k][j]; //creating threads pthread_create(&threads[count++], NULL, mult, (void*)(data)); } printf("RESULTANT MATRIX IS :-
"); for (i = 0; i < max; i++) { void *k; //Joining all threads and collecting return value pthread_join(threads[i], &k); int *p = (int *)k; printf("%d ",*p); if ((i + 1) % c2 == 0) printf("
"); } return 0;} |
Выход:
Матрица А 3 7 3 6 9 2 0 3 0 2 1 7 2 2 7 9 Матрица B 6 5 5 2 1 7 9 6 6 6 8 9 0 3 5 2 Умножение A и B 43 100 132 87 56 68 78 36 8 41 61 35 56 93 129 97
Вниманию читателя! Не переставай учиться сейчас. Освойте все важные концепции DSA с помощью самостоятельного курса DSA по приемлемой для студентов цене и будьте готовы к работе в отрасли. Чтобы завершить подготовку от изучения языка к DS Algo и многому другому, см. Полный курс подготовки к собеседованию .
Если вы хотите посещать живые занятия с отраслевыми экспертами, пожалуйста, обращайтесь к Geeks Classes Live и Geeks Classes Live USA.