Программа Python для поиска самого длинного общего префикса с использованием сопоставления слов по словам
Учитывая набор строк, найдите самый длинный общий префикс.
Примеры:
Input : {“geeksforgeeks”, “geeks”, “geek”, “geezer”}
Output : "gee"
Input : {"apple", "ape", "april"}
Output : "ap"Начнем с примера. Предположим, есть две строки — «geeksforgeeks» и «geeks». Каков самый длинный общий префикс в обоих из них? Это "выродки".
Теперь давайте введем еще одно слово «выродок». Итак, какой самый длинный общий префикс в этих трех словах? это "выродок"
Мы видим, что самый длинный общий префикс обладает ассоциативным свойством, т.е.
LCP(string1, string2, string3)
= LCP (LCP (string1, string2), string3)
Like here
LCP (“geeksforgeeks”, “geeks”, “geek”)
= LCP (LCP (“geeksforgeeks”, “geeks”), “geek”)
= LCP (“geeks”, “geek”) = “geek”Таким образом, мы можем использовать указанное выше ассоциативное свойство, чтобы найти LCP заданных строк. Мы один за другим вычисляем LCP каждой из заданных строк с LCP до сих пор. Конечным результатом будет наш самый длинный общий префикс из всех строк.
Обратите внимание, что данные строки могут не иметь общего префикса. Это происходит, когда первый символ всех строк не совпадает.
Мы показываем алгоритм с входными строками — «geeksforgeeks», «geeks», «geek», «geezer» на рисунке ниже.
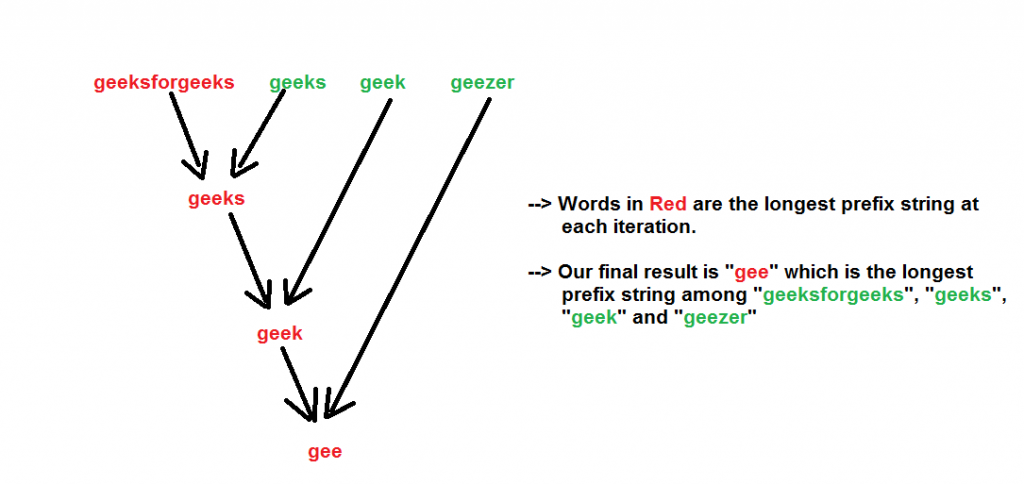
Ниже приведена реализация вышеуказанного подхода:
Выход :
The longest common prefix is - gee
Временная сложность: поскольку мы перебираем все строки и для каждой строки мы перебираем каждый символ, поэтому мы можем сказать, что временная сложность равна O (NM), где
N = Number of strings M = Length of the largest string string
Вспомогательное пространство: для хранения самой длинной строки префикса мы выделяем пространство, равное O(M).
Пожалуйста, обратитесь к полной статье о самом длинном общем префиксе с использованием Word by Word Matching для получения более подробной информации!