Обзор фильтра Калмана для беспилотного автомобиля
Фильтр Калмана - это оптимальный алгоритм оценки. Это может помочь нам предсказать / оценить положение объекта, когда мы находимся в состоянии сомнения из-за различных ограничений, таких как точность или физические ограничения, которые мы обсудим в ближайшее время.
Применение фильтра Калмана:
Фильтры Калмана используются, когда -
- Интересующая переменная, которую можно измерить только косвенно.
- Измерения доступны с различных датчиков, но могут быть вызваны шумом, например Sensor Fusion.
Давайте углубимся в каждое из применений по порядку.
- Косвенное измерение:
Для измерения интересующей переменной (рассматриваемой переменной), которую можно измерить только косвенно. Этот тип переменной называется переменной оценки состояния. Давайте разберемся с этим на примере.
Пример:
Допустим, вы хотите знать, насколько счастлива ваша собака Джеки. Таким образом, интересующая вас переменная y - это счастье Джеки. Теперь единственный способ измерить счастье Джеки - это измерить его косвенно, поскольку счастье не является физическим состоянием, которое можно измерить напрямую. Вы можете увидеть, как Джеки машет хвостом, и предсказать, счастлив он или нет. У вас также может быть совершенно другой подход, чтобы дать вам представление или оценить, насколько счастлив Джеки. Эта уникальная идея - фильтр Калмана. Именно это я имел в виду, когда сказал, что фильтр Калмана - это оптимальный алгоритм оценки. - Sensor Fusion:
Теперь у вас есть интуитивное представление о том, что это за фильтр. Фильтр Калмана объединяет измерение и прогноз, чтобы найти оптимальную оценку положения автомобиля.
Пример:
Предположим, у вас есть автомобиль с дистанционным управлением и он движется со скоростью 1 м / с. допустим, что через 1 секунду вам нужно предсказать точное положение автомобиля, каков будет ваш прогноз ??
Что ж, если вы знаете базовую формулу времени, расстояния и скорости, вы сможете правильно сказать, что на 1 метр опережает текущее положение. Но насколько точна эта модель ??
Всегда есть некоторые отклонения от идеального сценария, и это отклонение является причиной ошибки. Теперь, чтобы минимизировать ошибку в предсказании состояния, выполняется измерение с датчика. Измерение датчика также имеет некоторую погрешность. Итак, теперь у нас есть два распределения вероятности (датчик и прогноз, поскольку они не всегда являются числом, а представляют собой функцию распределения вероятностей (pdf)), которые, как предполагается, сообщают местонахождение автомобиля. Как только мы объединим эти две гауссовские кривые, мы сможем получить совершенно новую гауссову кривую с гораздо меньшей дисперсией.
Пример:
Предположим, у вас есть друг (Сенсор 2), который хорошо разбирается в математике, но не настолько хорош в физике, и вы (Сенсор 1) хорошо разбираетесь в физике, но не так хорошо в математике. Теперь, в день экзамена, когда ваша цель получает хороший результат, вы и ваш друг собираетесь вместе, чтобы преуспеть по обоим предметам. Вы оба сотрудничаете, чтобы минимизировать ошибку и максимизировать результат (вывод).
Пример:
Это похоже на то, как когда вам нужно узнать об инциденте, вы спрашиваете об этом разных людей и, прослушав все их истории, составляете свою собственную, которая, как вам кажется, намного точнее, чем любая из отдельных историй. Смотрите, что это всегда связано с нашей повседневной жизнью, и мы всегда можем установить связь с тем, что мы уже испытали.
Code: Python implementation of the 1-D Kalman filter
def update(mean1, var1, mean2, var2): new_mean = float(var2 * mean1 + var1 * mean2) / (var1 + var2) new_var = 1./(1./var1 + 1./var2) return [new_mean, new_var] def predict(mean1, var1, mean2, var2): new_mean = mean1 + mean2 new_var = var1 + var2 return [new_mean, new_var] measurements = [5., 6., 7., 9., 10.]motion = [1., 1., 2., 1., 1.]measurement_sig = 4.motion_sig = 2.mu = 0.sig = 10000. # print out ONLY the final values of the meanalthough for a better understanding you may choose to # and the variance in a list [mu, sig]. for measurement, motion in zip(measurements, motion): mu, sig = update(measurement, measurement_sig, mu, sig) mu, sig = predict(motion, motion_sig, mu, sig)print([mu, sig]) |
Объяснение:
Как мы уже обсуждали, весь процесс состоит из двух основных этапов: первый этап обновления, а затем этап прогнозирования. Эти два шага повторяются снова и снова, чтобы оценить точное положение робота.
Шаг предсказания:
Новое положение p 'можно рассчитать по формуле
где p - предыдущая позиция, v - скорость, а dt - временной шаг.
новая скорость v 'будет такой же, как предыдущая скорость, как ее постоянная (предположение). В уравнении это можно представить как
Теперь запишем все это в единую матрицу.
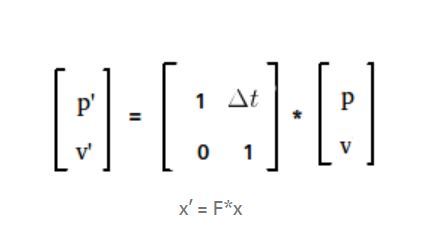
Шаг прогноза
Шаг обновления:
Фильтр, который вы только что реализовали, написан на Python, и он тоже в 1-D. В основном мы имеем дело с более чем одним измерением, и язык меняется для одного и того же. Итак, давайте реализуем фильтр Калмана на C ++.
Требование:
Библиотека Eigen
Вам понадобится библиотека Eigen, особенно класс Dense, чтобы работать с линейной алгеброй, необходимой в процессе. Скачайте библиотеку и вставьте ее в папку, содержащую файлы кода, на случай, если вы не знаете, как библиотеки работают в C ++. Также просмотрите официальную документацию, чтобы лучше понять, как использовать его функции. Я должен признать, что то, как они объяснили в документации, потрясающе и лучше любого учебника, который вы можете попросить.
Now implementing the same prediction and update function in c++ using this new weapon(library) we have found to deal with the algebra part in the process.
Prediction Step:
P’ = F * P * F.transpose() + Q
Here B.u becomes zero as this is used to incorporate changes related to friction or any other force that is hard to calculate. v is the process noise which determines random noise that can be present in the system as a whole.
void KalmanFilter::Predict(){ x = F * x; MatrixXd Ft = F.transpose(); P = F * P * Ft + Q;} |
Благодаря этому мы смогли вычислить предсказанное значение X и ковариационную матрицу P.
Шаг обновления:
где w представляет собой шум измерения датчика.
Итак, для лидара функция измерения выглядит так:
Его также можно представить в матричной форме:
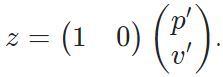
Представление в матричной форме
На этом этапе мы используем последние измерения, чтобы обновить нашу оценку и нашу неопределенность.
H is the measurement function that maps the state to the measurement and helps in calculating the Error (y) by comparing the measurement(z) with our prediction(H*x).
The error is mapped into a matrix S, which is obtained by projecting the System Uncertainty(P) into the measurement space using the measurement function(H) + Matrix R that characters measurement Noise.
This is then mapped into the variable called K. K is the Kalman gain and decides whether the measurement taken needs to be given more weight or the prediction according to the previous data and its uncertainty.
And then finally we update our estimate(x) and our uncertainty(P) using this equation using Kalman gain.
x = x + (K * y)
P = (I – K * H) * P
Here I is an identity matrix.
void KalmanFilter::Update(const VectorXd& z){ VectorXd z_pred = H * x; VectorXd y = z - z_pred; MatrixXd Ht = H.transpose(); MatrixXd S = H * P * Ht + R; MatrixXd Si = S.inverse(); MatrixXd PHt = P * Ht; MatrixXd K = PHt * Si; // new estimate x = x + (K * y); long x_size = x_.size(); MatrixXd I = MatrixXd::Identity(x_size, x_size); P = (I - K * H) * P;} |
Code:
// create a 4D state vector, we don"t know yet the values of the x statex = VectorXd(4); // state covariance matrix PP = MatrixXd(4, 4);P << 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1000, 0, 0, 0, 0, 1000; // measurement covarianceR = MatrixXd(2, 2);R << 0.0225, 0, 0, 0.0225; // measurement matrixH = MatrixXd(2, 4);H << 1, 0, 0, 0, 0, 1, 0, 0; // the initial transition matrix FF = MatrixXd(4, 4);F << 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1; // set the acceleration noise componentsnoise_ax = 5;noise_ay = 5; |
Причина, по которой я не инициализировал матрицы сначала, заключается в том, что это не основная часть, пока мы пишем фильтр Калмана. Во-первых, мы должны знать, как работают две основные функции. потом идет инициализация и прочее.
Некоторые недостатки:
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.