XGBoost в программировании на R
XGBoost - это быстрый и эффективный алгоритм, который используют победители многих соревнований по машинному обучению. XG Boost работает только с числовыми переменными. Это часть метода повышения, в котором выбор выборки выполняется более разумно для классификации наблюдений. Интерфейсы XGBoost есть в C ++, R, Python, Julia, Java и Scala. Основные функции в XGBoost реализованы на C ++, поэтому модели легко использовать для разных интерфейсов. По статистике зеркала CRAN, пакет был скачан более 81 000 раз. Моделирование XgBoost состоит из двух техник: Bagging и Boosting.
- Бэггинг: это подход, при котором вы можете брать случайные выборки данных, строить алгоритмы обучения и использовать простые средства для определения вероятностей бэггинга.
- Повышение: это подход, при котором выбор подхода осуществляется более разумно, т. Е. Больший вес придается классификации наблюдений.
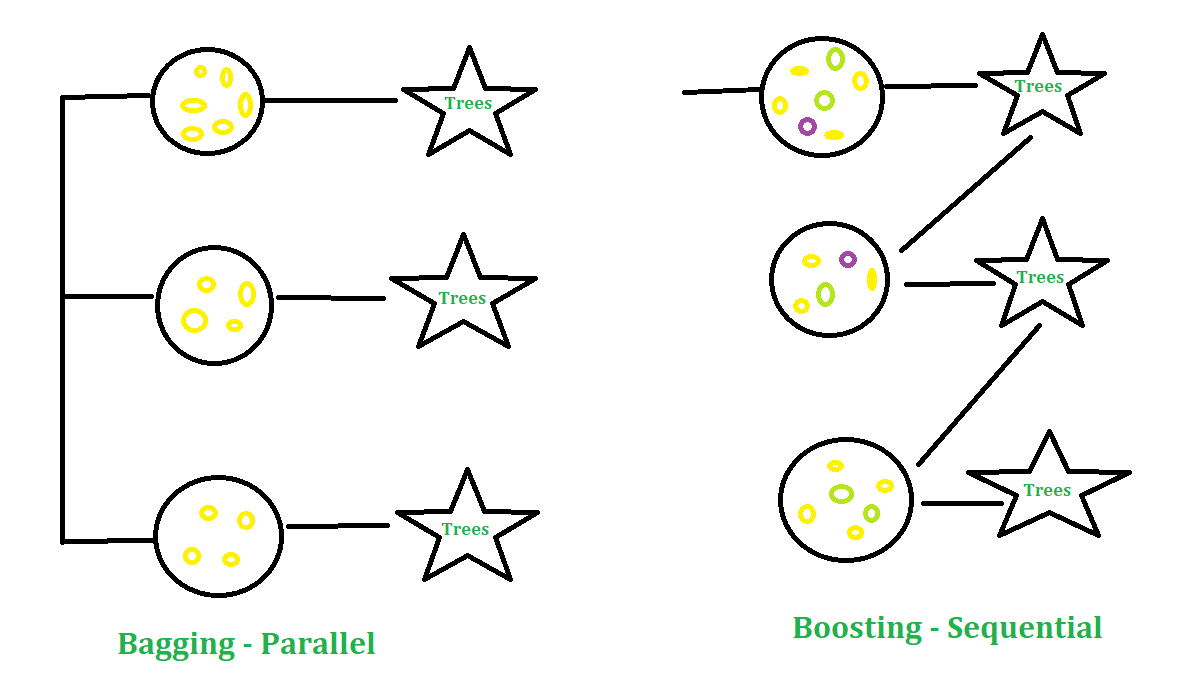
Параметры в XGBoost
- eta: Он уменьшает веса функций, чтобы сделать процесс повышения более консервативным. Диапазон составляет от 0 до 1. Он также известен как скорость обучения или коэффициент сжатия. Низкое значение eta означает, что модель более устойчива к переобучению.
- гамма: чем больше значение гаммы, тем более консервативным будет алгоритм. Диапазон от 0 до бесконечности.
- max_depth: максимальная глубина дерева может быть указана с
max_depthпараметра max_depth. - Подвыборка: это доля строк, которые модель случайным образом выбирает для выращивания деревьев.
- colsample_bytree: это отношение переменных, случайно выбранных для построения каждого дерева в модели.
Набор данных
Набор данных Big Mart состоит из 1559 товаров в 10 магазинах в разных городах. Определены определенные атрибуты каждого продукта и магазина. Он состоит из 12 функций, например, Item_Identifier (уникальный идентификатор продукта, присваиваемый каждому отдельному элементу), Item_Weight (включает вес продукта), Item_Fat_Content (описывает, является ли продукт с низким содержанием жира), Item_Visibility (упоминает процент от общая площадь отображения всех продуктов в магазине, выделенная конкретному продукту), Item_Type (описывает категорию продуктов питания, к которой принадлежит товар), Item_MRP (максимальная розничная цена (прейскурантная цена) продукта), Outlet_Identifier (присвоенный уникальный идентификатор магазина. Он состоит из буквенно-цифровой строки длиной 6), Outlet_Establishment_Year (указывает год открытия магазина), Outlet_Size (указывает размер магазина с точки зрения покрытой площади), Outlet_Location_Type (указывает размер города, в котором магазин расположен), Outlet_Type (указывает, является ли торговая точка просто продуктовым магазином или каким-то супермаркетом) и Item_Outlet_Sales (продажи продукта в конкретном магазине).
# Loading datatrain = fread ( "Train_UWu5bXk.csv" )test = fread ( "Test_u94Q5KV.csv" ) # Structurestr (train) |
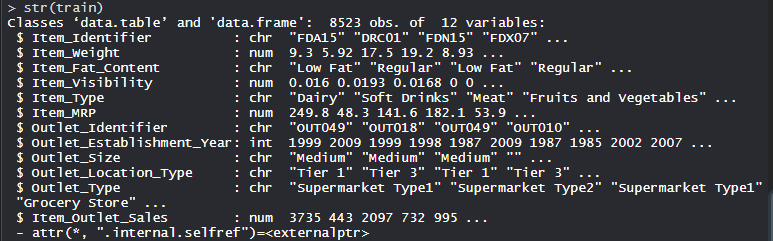
Выполнение XGBoost для набора данных
Использование алгоритма XGBoost в наборе данных, который включает 12 функций с 1559 продуктами в 10 магазинах в разных городах.
# Installing Packagesinstall.packages("data.table")install.packages("dplyr")install.packages("ggplot2")install.packages("caret")install.packages("xgboost")install.packages("e1071")install.packages("cowplot") # Loading packageslibrary(data.table) # for reading and manipulation of datalibrary(dplyr) # for data manipulation and joininglibrary(ggplot2) # for ploting library(caret) # for modelinglibrary(xgboost) # for building XGBoost modellibrary(e1071) # for skewnesslibrary(cowplot) # for combining multiple plots # Setting test dataset# Combining datasets# add Item_Outlet_Sales to test datatest[, Item_Outlet_Sales := NA] combi = rbind(train, test) # Missing Value Treatmentmissing_index = which(is.na(combi$Item_Weight))for(i in missing_index){ item = combi$Item_Identifier[i] combi$Item_Weight[i] = mean(combi$Item_Weight [combi$Item_Identifier == item], na.rm = T)} # Replacing 0 in Item_Visibility with meanzero_index = which(combi$Item_Visibility == 0)for(i in zero_index){ item = combi$Item_Identifier[i] combi$Item_Visibility[i] = mean( combi$Item_Visibility[combi$Item_Identifier == item], na.rm = T)} # Label Encoding# To convert categorical in numericalcombi[, Outlet_Size_num := ifelse(Outlet_Size == "Small", 0, ifelse(Outlet_Size == "Medium", 1, 2))] combi[, Outlet_Location_Type_num := ifelse(Outlet_Location_Type == "Tier 3", 0, ifelse(Outlet_Location_Type == "Tier 2", 1, 2))] combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL] # One Hot Encoding# To convert categorical in numericalohe_1 = dummyVars("~.", data = combi[, -c("Item_Identifier", "Outlet_Establishment_Year", "Item_Type")], fullRank = T)ohe_df = data.table(predict(ohe_1, combi[, -c("Item_Identifier", "Outlet_Establishment_Year", "Item_Type")])) combi = cbind(combi[, "Item_Identifier"], ohe_df) # Remove skewnessskewness(combi$Item_Visibility) skewness(combi$price_per_unit_wt) # log + 1 to avoid division by zerocombi[, Item_Visibility := log(Item_Visibility + 1)] # Scaling and Centering data# index of numeric featuresnum_vars = which(sapply(combi, is.numeric)) num_vars_names = names(num_vars) combi_numeric = combi[, setdiff(num_vars_names, "Item_Outlet_Sales"), with = F] prep_num = preProcess(combi_numeric, method = c("center", "scale"))combi_numeric_norm = predict(prep_num, combi_numeric) # removing numeric independent variablescombi[, setdiff(num_vars_names, "Item_Outlet_Sales") := NULL] combi = cbind(combi, combi_numeric_norm) # Splitting data back to train and testtrain = combi[1:nrow(train)]test = combi[(nrow(train) + 1):nrow(combi)] # Removing Item_Outlet_Salestest[, Item_Outlet_Sales := NULL] # Model Building: XGBoostparam_list = list( objective = "reg:linear", eta = 0.01, gamma = 1, max_depth = 6, subsample = 0.8, colsample_bytree = 0.5) # Converting train and test into xgb.DMatrix formatDtrain = xgb.DMatrix( data = as.matrix(train[, -c("Item_Identifier", "Item_Outlet_Sales")]), label = train$Item_Outlet_Sales)Dtest = xgb.DMatrix( data = as.matrix(test[, -c("Item_Identifier")])) # 5-fold cross-validation to # find optimal value of nroundsset.seed(112) # Setting seedxgbcv = xgb.cv(params = param_list, data = Dtrain, nrounds = 1000, nfold = 5, print_every_n = 10, early_stopping_rounds = 30, maximize = F) # Training XGBoost model at nrounds = 428xgb_model = xgb.train(data = Dtrain, params = param_list, nrounds = 428)xgb_model # Variable Importancevar_imp = xgb.importance( feature_names = setdiff(names(train), c("Item_Identifier", "Item_Outlet_Sales")), model = xgb_model) # Importance plotxgb.plot.importance(var_imp) |
Выход:
- Обучение модели Xgboost:
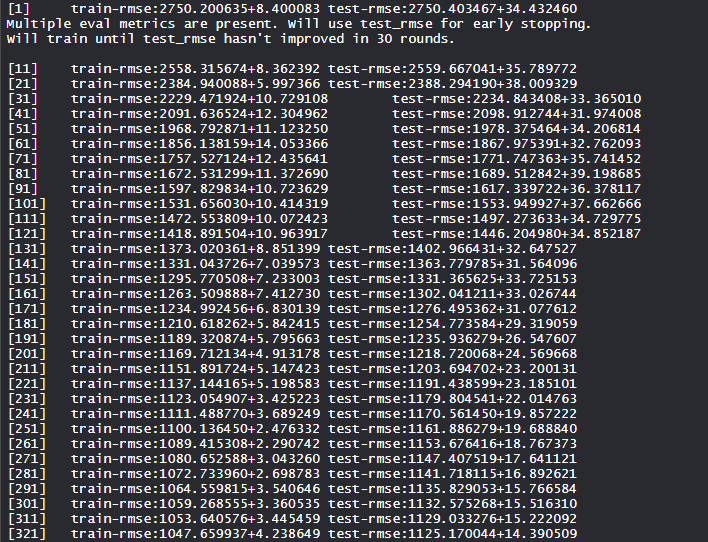
Модель xgboost обучена вычислению оценок train-rmse и test-rmse и нахождению самого низкого значения во многих раундах.
- Модель xgb_model:
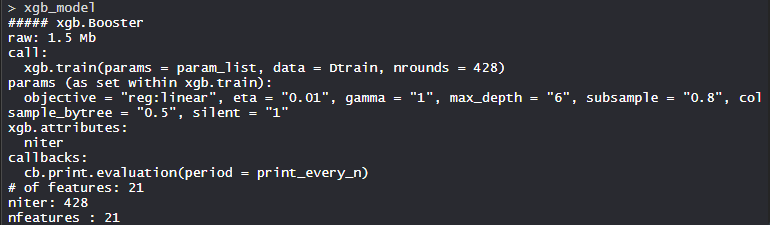
Модели XgBoost состоят из 21 функции с целью линейной регрессии, eta - 0,01, гамма - 1, max_depth - 6, подвыборка - 0,8, colsample_bytree = 0,5 и silent - 1.
- График переменной важности:
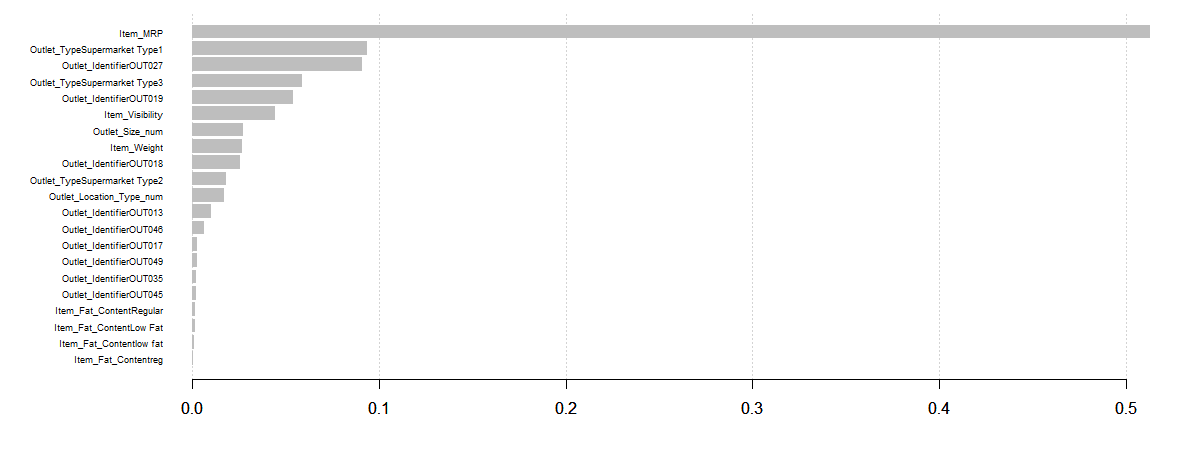
Item_MRP - самая важная переменная, за которой следуют Item_Visibility и Outlet_Location_Type_num.
Таким образом, Xgboost находит свое применение во многих отраслях промышленности и используется на полную мощность.