Введение в распределенную файловую систему Hadoop (HDFS)
С ростом скорости передачи данных размер данных легко превышает предел памяти машины. Решением было бы хранить данные в сети машин. Такие файловые системы называются распределенными файловыми системами . Поскольку данные хранятся в сети, возникают все сложности сети.
Здесь на помощь приходит Hadoop. Он предоставляет одну из самых надежных файловых систем. HDFS (Распределенная файловая система Hadoop) - это уникальный дизайн, который обеспечивает хранение очень больших файлов с использованием схемы доступа к потоковым данным и работает на стандартном оборудовании . Уточним термины:
- Чрезвычайно большие файлы : здесь мы говорим о данных в диапазоне петабайт (1000 ТБ).
- Шаблон доступа к потоковым данным : HDFS разработана по принципу однократной записи и многократного чтения . После записи данных большие части набора данных можно обрабатывать любое количество раз.
- Товарное оборудование: оборудование, которое недорогое и легко доступно на рынке. Это одна из особенностей, которая отличает HDFS от других файловых систем.
Узлы: ведущие и ведомые узлы обычно образуют кластер HDFS.
- Мастер-узел:
- Управляет всеми подчиненными узлами и назначает им работу.
- Он выполняет операции пространства имен файловой системы, такие как открытие, закрытие, переименование файлов и каталогов.
- Его следует развертывать на надежном оборудовании с высокой конфигурацией. не на товарном оборудовании.
- Имя Узел:
- Фактические рабочие узлы, которые выполняют фактическую работу, такую как чтение, запись, обработка и т. Д.
- Они также выполняют создание, удаление и репликацию по команде мастера.
- Их можно развернуть на обычном оборудовании.
Демоны HDFS: Демоны - это процессы, работающие в фоновом режиме.
- Запускаем на главном узле.
- Храните метаданные (данные о данных), такие как путь к файлу, количество блоков, идентификаторы блоков. и т.п.
- Требуется большой объем оперативной памяти.
- Храните метаданные в ОЗУ для быстрого поиска, т.е. для сокращения времени поиска. Хотя постоянная его копия хранится на диске.
- Запуск на подчиненных узлах.
- Требуется высокая память, поскольку данные фактически хранятся здесь.
Хранение данных в HDFS: теперь давайте посмотрим, как данные хранятся распределенным образом.
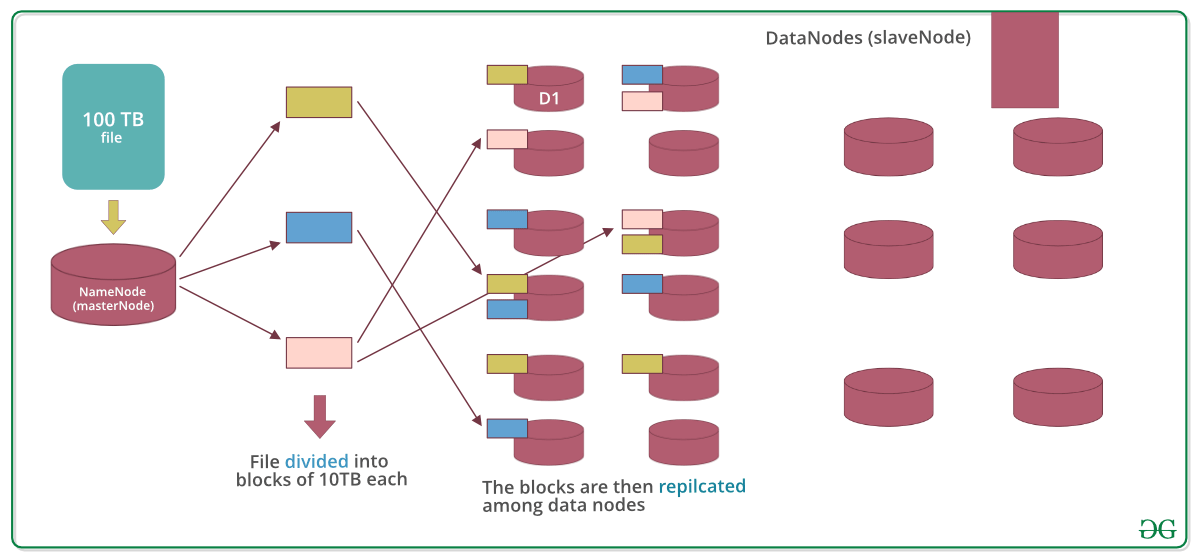
Предположим, что вставлен файл размером 100 ТБ, затем мастернода (namenode) сначала разделит файл на блоки по 10 ТБ (размер по умолчанию 128 МБ в Hadoop 2.x и выше). Затем эти блоки сохраняются на разных узлах данных (slavenode). Датаноды (slavenode) реплицируют блоки между собой, и информация о том, какие блоки они содержат, отправляется мастеру. Коэффициент репликации по умолчанию равен 3, значит для каждого блока создается 3 реплики (включая его самого). В hdfs.site.xml мы можем увеличивать или уменьшать коэффициент репликации, т.е. мы можем редактировать его конфигурацию здесь.
Примечание: MasterNode имеет запись всего, он знает местоположение и информацию о каждом отдельном узле данных и блоках, которые они содержат, т.е. ничего не делается без разрешения мастерноды.
Зачем делить файл на блоки?
Ответ: Допустим, мы не разделяем, сейчас очень сложно хранить файл 100 ТБ на одной машине. Даже если мы сохраняем, каждая операция чтения и записи для всего файла будет занимать очень большое время поиска. Но если у нас есть несколько блоков размером 128 МБ, тогда становится проще выполнять с ними различные операции чтения и записи по сравнению с одновременным выполнением этого для всего файла. Таким образом, мы разделяем файл, чтобы иметь более быстрый доступ к данным, т.е. сократить время поиска.
Зачем реплицировать блоки в узлах данных при хранении?
Ответ: Предположим, что мы не реплицируем, и на датаноде D1 присутствует только один желтый блок. Теперь, если узел данных D1 выйдет из строя, мы потеряем блок, что сделает общие данные несогласованными и ошибочными. Поэтому мы реплицируем блоки для обеспечения отказоустойчивости.
Термины, относящиеся к HDFS:
- HeartBeat : это сигнал, который datanode непрерывно отправляет на namenode. Если namenode не получает пульс от узла данных, он будет считать его мертвым.
- Балансировка : если датанод разбился, блоки, присутствующие на нем, тоже исчезнут, и блоки будут реплицированы недостаточно по сравнению с остальными блоками. Здесь главный узел (namenode) будет давать сигнал узлам данных, содержащим реплики этих потерянных блоков, для репликации, чтобы общее распределение блоков было сбалансированным.
- Репликация:: Это выполняется datanode.
Примечание. На одном узле данных нет двух реплик одного и того же блока.
Функции:
- Распределенное хранилище данных.
- Блоки сокращают время поиска.
- Данные высокодоступны, поскольку один и тот же блок присутствует на нескольких узлах данных.
- Даже если несколько узлов данных не работают, мы все равно можем выполнять свою работу, что делает ее очень надежной.
- Высокая отказоустойчивость.
Ограничения: хотя HDFS предоставляет множество функций, в некоторых областях она не работает.
- Доступ к данным с малой задержкой : приложения, которым требуется доступ к данным с малой задержкой, то есть в диапазоне миллисекунд, не будут работать с HDFS, потому что HDFS разработана с учетом того, что нам нужна высокая пропускная способность данных даже за счет задержки.
- Проблема с небольшим файлом : наличие большого количества маленьких файлов приведет к большому количеству поисков и большому количеству перемещений от одного узла данных к другому для извлечения каждого небольшого файла, весь этот процесс является очень неэффективным шаблоном доступа к данным.