Веб-парсинг из Википедии с использованием Python - полное руководство
В этой статье вы познакомитесь с различными концепциями парсинга веб-сайтов и освоите парсинг различных типов веб-сайтов и их данных. Цель состоит в том, чтобы очистить данные с домашней страницы Википедии и проанализировать их с помощью различных методов очистки веб-страниц. Вы познакомитесь с различными методами парсинга веб-страниц, модулями Python для парсинга веб-страниц и процессами извлечения и обработки данных. Веб-скрапинг - это автоматический процесс извлечения информации из Интернета. Эта статья даст вам подробное представление о парсинге веб-страниц, его сравнении со сканированием веб-страниц и о том, почему вам следует выбрать парсинг веб-страниц.
Введение в парсинг веб-страниц и Python
По сути, это метод или процесс, в котором большие объемы данных с огромного количества веб-сайтов передаются через программное обеспечение для очистки веб-страниц, закодированное на языке программирования, и в результате извлекаются структурированные данные, которые можно сохранить локально на наших устройствах, предпочтительно в таблицах Excel, JSON или электронных таблицах. Теперь нам не нужно вручную копировать и вставлять данные с веб-сайтов, но парсер может выполнить эту задачу за нас за пару секунд.
Web scraping is also known as Screen Scraping, Web Data Extraction, Web Harvesting, etc.
Процесс парсинга веб-страниц
Это помогает программистам писать понятный, логичный код для небольших и крупных проектов. Python в основном известен как лучший язык для веб-парсеров . Он больше похож на универсал и может без проблем справляться с большинством процессов, связанных со сканированием Интернета. Scrapy и Beautiful Soup относятся к числу широко используемых фреймворков на основе Python, что делает парсинг с использованием этого языка таким простым путем.
Краткий список библиотек Python, используемых для парсинга веб-страниц
Давайте посмотрим на библиотеки для парсинга в Python!
- Библиотека запросов (HTTP для людей) для веб-парсинга - используется для выполнения различных типов HTTP-запросов, таких как GET, POST и т. Д. Это самая простая, но самая важная из всех библиотек.
- lxml Library for Web Scraping - библиотека lxml обеспечивает сверхбыстрый и высокопроизводительный синтаксический анализ содержимого HTML и XML с веб-сайтов. Если вы планируете очищать большие наборы данных, вам следует выбрать именно этот.
- Beautiful Soup Library for Web Scraping - ее работа включает создание дерева синтаксического анализа для анализа содержимого. Прекрасная стартовая библиотека для новичков, с которой очень легко работать.
- Библиотека Selenium для парсинга веб-сайтов. Первоначально созданная для автоматического тестирования веб-приложений, эта библиотека решает проблему, с которой сталкиваются все вышеперечисленные библиотеки, то есть соскабливание контента с динамически заполняемых веб-сайтов. Это делает его медленнее и не подходит для проектов отраслевого уровня.
- Scrapy для веб-парсинга - БОСС всех библиотек, весь фреймворк для парсинга веб-страниц, который является асинхронным в своем использовании. Это делает его невероятно быстрым и повышает эффективность.
Практическая реализация - парсинг Википедии
Шаг 1. Как использовать Python для парсинга веб-страниц?
- Нам нужна IDE для Python, и мы должны уметь ее использовать.
- Virtualenv - это инструмент для создания изолированных сред Python. С помощью virtualenv мы можем создать папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые требуются нашему проекту Python. Здесь мы можем добавлять и изменять модули Python, не влияя на глобальную установку.
- Для нашей цели нам нужно установить различные модули и библиотеки Python, используя команду pip. Но мы всегда должны помнить о том, является ли веб-сайт, который мы очищаем, законным или нет.
Требования:
- Запросы: это эффективная HTTP-библиотека, используемая для доступа к веб-страницам.
- Urlib3: используется для получения данных из URL-адресов.
- Selenium: это пакет автоматического тестирования с открытым исходным кодом для веб-приложений в различных браузерах и платформах.
Монтаж:
pip install virtualenv python -m pip установить селен запросы на установку python -m pip python -m pip установить urllib3
Образец изображения при установке
Шаг 2. Знакомство с библиотекой запросов
- Здесь мы изучим различные модули Python для извлечения данных из Интернета.
- Библиотека запросов python используется для загрузки веб-страницы, которую мы пытаемся очистить.
Требования:
- Python IDE
- Модули Python
- Библиотека запросов
Прохождение кода:
URL: https://en.wikipedia.org/wiki/Main_Page
Python3
# import required modulesrequests import # get URL # display status codeprint (page.status_code) # display scrapped dataprint (page.content) |
Выход:
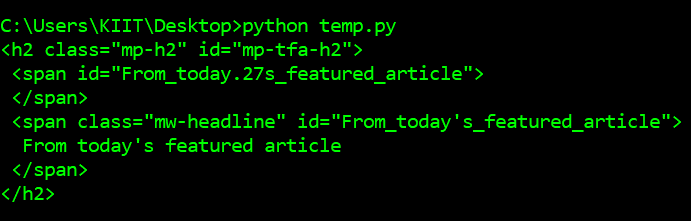
Первое, что нам нужно сделать, чтобы очистить веб-страницу, - это загрузить страницу. Мы можем загружать страницы, используя библиотеку запросов Python. Библиотека запросов отправит GET-запрос на веб-сервер, который загрузит для нас HTML-содержимое данной веб-страницы. Есть несколько типов запросов, которые мы можем делать с помощью запросов, из которых GET - только один. URL-адрес нашего образца веб-сайта: https://en.wikipedia.org/wiki/Main_Page. Задача - скачать его с помощью метода requests.get () . После выполнения нашего запроса мы получаем объект Response. Этот объект имеет свойство status_code , которое указывает, была ли страница загружена успешно. И свойство содержимого, которое выдает HTML-содержимое веб-страницы в качестве вывода.
Шаг 3. Знакомство с Beautiful Soup для разбора страниц
У нас есть много модулей Python для извлечения данных. Мы собираемся использовать BeautifulSoup для нашей цели.
- BeautifulSoup - это библиотека Python для извлечения данных из файлов HTML и XML.
- Ему нужен ввод (документ или URL-адрес) для создания объекта супа, поскольку он не может получить веб-страницу сам по себе.
- У нас есть другие модули, такие как регулярное выражение, lxml для той же цели.
- Затем мы обрабатываем данные в формате CSV, JSON или MySQL.
Требования:
- PythonIDE
- Модули Python
- Библиотека Beautiful Soup
pip install bs4
Прохождение кода:
Python3
# import required modulesfrom bs4 import BeautifulSouprequests import # get URL # scrape webpagesoup = BeautifulSoup(page.content, 'html.parser' ) # display scrapped dataprint (soup.prettify()) |
Выход:
Как вы можете видеть выше, мы загрузили HTML-документ. Мы можем использовать библиотеку BeautifulSoup для анализа этого документа и извлечения текста из тега p. Сначала нам нужно импортировать библиотеку и создать экземпляр класса BeautifulSoup для анализа нашего документа. Теперь мы можем распечатать HTML-содержимое страницы, хорошо отформатированное, используя метод prettify для объекта BeautifulSoup. Поскольку все теги вложены, мы можем перемещаться по структуре на один уровень за раз. Сначала мы можем выбрать все элементы на верхнем уровне страницы, используя свойство супа для детей. Обратите внимание, что потомки возвращают генератор списков, поэтому нам нужно вызвать на нем функцию списка.
Шаг 4. Углубляйтесь в Beautiful Soup.
Три функции, которые делают Beautiful Soup таким мощным:
- Beautiful Soup предоставляет несколько простых методов и идиом Pythonic для навигации, поиска и изменения дерева синтаксического анализа: набор инструментов для анализа документа и извлечения того, что вам нужно. Для написания приложения не требуется много кода
- Beautiful Soup автоматически конвертирует входящие документы в Unicode, а исходящие - в UTF-8. Вам не нужно думать о кодировках, если в документе не указана кодировка, а Beautiful Soup не может ее обнаружить. Тогда вам просто нужно указать исходную кодировку.
- Beautiful Soup расположен поверх популярных парсеров Python, таких как lxml и html5lib, что позволяет вам опробовать различные стратегии синтаксического анализа или торговать скоростью для гибкости. Затем нам нужно просто обработать наши данные в правильном формате, таком как CSV, JSON или MySQL.
Требования:
- PythonIDE
- Модули Python
- Библиотека Beautiful Soup
Прохождение кода:
Python3
# import required modulesfrom bs4 import BeautifulSouprequests import # get URL # scrape webpagesoup = BeautifulSoup(page.content, 'html.parser' ) list (soup.children) # find all occurance of p in HTML# includes HTML tagsprint (soup.find_all( 'p' )) print ( '
' ) # return only text# does not include HTML tagsprint (soup.find_all( 'p' )[ 0 ].get_text()) |
Выход:
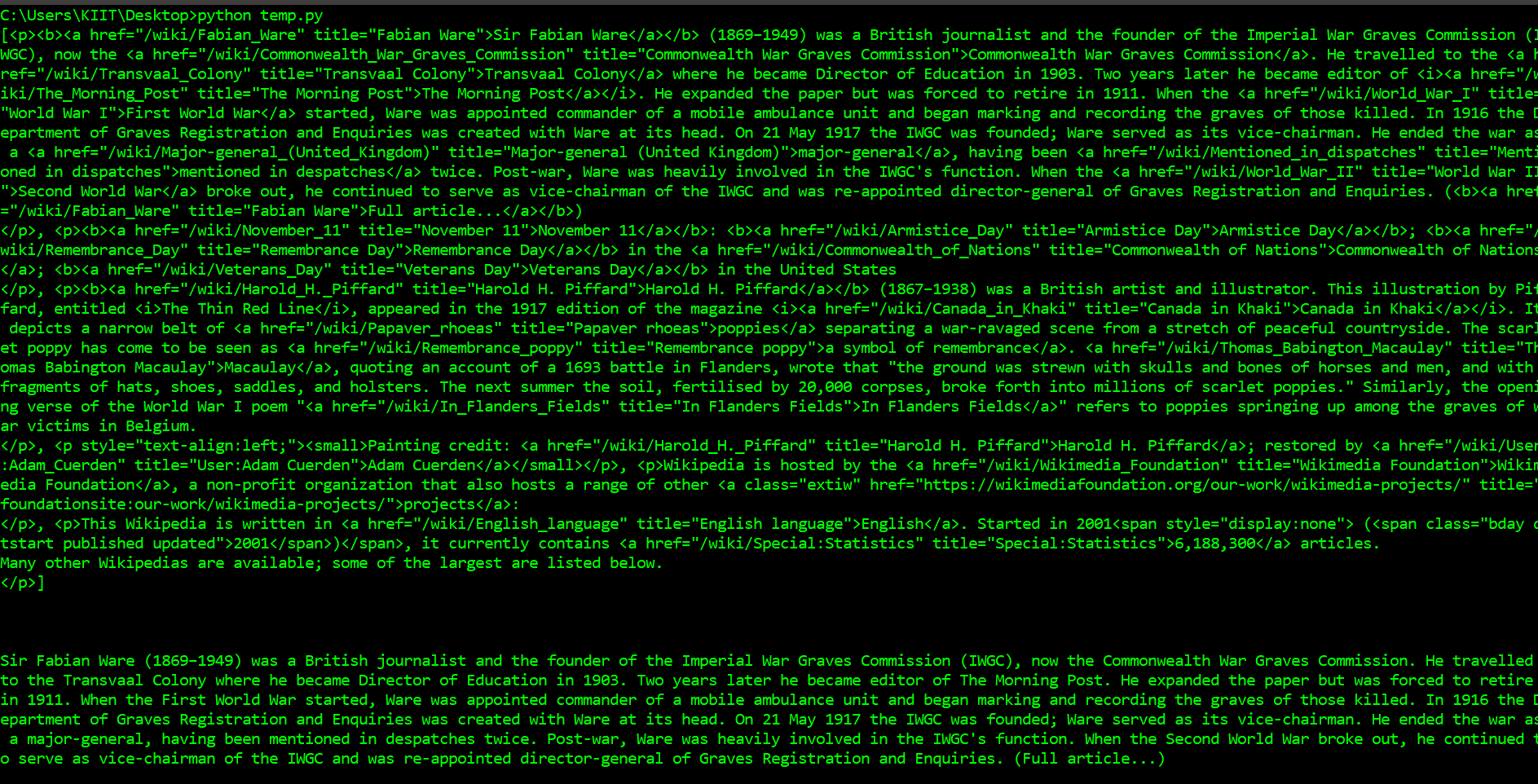
То, что мы сделали выше, было полезно для понимания того, как перемещаться по странице, но потребовалось множество команд, чтобы сделать что-то довольно простое. Если мы хотим извлечь один тег, мы можем вместо этого использовать метод find_all () , который найдет все экземпляры тега на странице. Обратите внимание, что find_all () возвращает список, поэтому нам придется пройти через цикл или использовать индексирование списка для извлечения текста. Если вместо этого вы хотите найти только первый экземпляр тега, вы можете использовать метод find, который вернет один объект BeautifulSoup.
Шаг 5. Изучение структуры страницы с помощью инструментов Chrome Dev и извлечение информации
Первое, что нам нужно сделать, это проверить страницу с помощью Chrome Devtools . Если вы используете другой браузер, у Firefox и Safari есть эквиваленты. Однако рекомендуется использовать Chrome.
Вы можете запустить инструменты разработчика в Chrome, щелкнув Вид -> Разработчик -> Инструменты разработчика . У вас должна получиться панель в нижней части браузера, подобная той, что вы видите ниже. Убедитесь, что панель «Элементы» выделена. Панель элементов покажет вам все теги HTML на странице и позволит вам перемещаться по ним. Это действительно удобная функция! Щелкнув правой кнопкой мыши на странице рядом с надписью « Расширенный прогноз» , а затем нажав « Проверить» , мы откроем тег, содержащий текст « Расширенный прогноз» на панели элементов.
Анализ с помощью инструментов Chrome Dev
Прохождение кода:
Python3
# import required modulesfrom bs4 import BeautifulSouprequests import # get URL # scrape webpagesoup = BeautifulSoup(page.content, 'html.parser' ) # create objectobject = soup.find( id = "mp-left" ) # find tagsitems = object .find_all( class_ = "mp-h2" )result = items[ 0 ] # display tagsprint (result.prettify()) |
Выход:
Здесь мы должны выбрать тот элемент, который имеет идентификатор и содержит дочерние элементы того же класса. Например, элемент с идентификатором mp-left является родительским элементом, а его вложенные дочерние элементы имеют класс mp-h2 . Итак, мы распечатаем информацию с первым вложенным потомком и преобразим его с помощью функции prettify () .
Заключение и более глубокий анализ веб-парсинга
Мы изучили различные концепции парсинга веб-страниц и данных с домашней страницы Википедии и проанализировали их с помощью различных методов парсинга. Эта статья помогла нам получить более подробное представление о парсинге веб-страниц, его сравнении со сканированием веб-страниц и о том, почему вам следует выбрать парсинг веб-страниц. Мы также узнали о компонентах и работе парсера.
Хотя веб-парсинг открывает множество возможностей для этических целей, неэтичные практики могут произвести непреднамеренный сбор данных, что создает моральный риск для многих компаний и организаций, где они могут легко получить данные и использовать их в своих эгоистичных целях. Сбор данных в сочетании с большими данными может предоставить компании информацию о рынке и помочь им выявить критические тенденции и закономерности, а также выявить лучшие возможности и решения. Таким образом, довольно точно предсказать, что очистка данных может быть улучшена в ближайшее время.
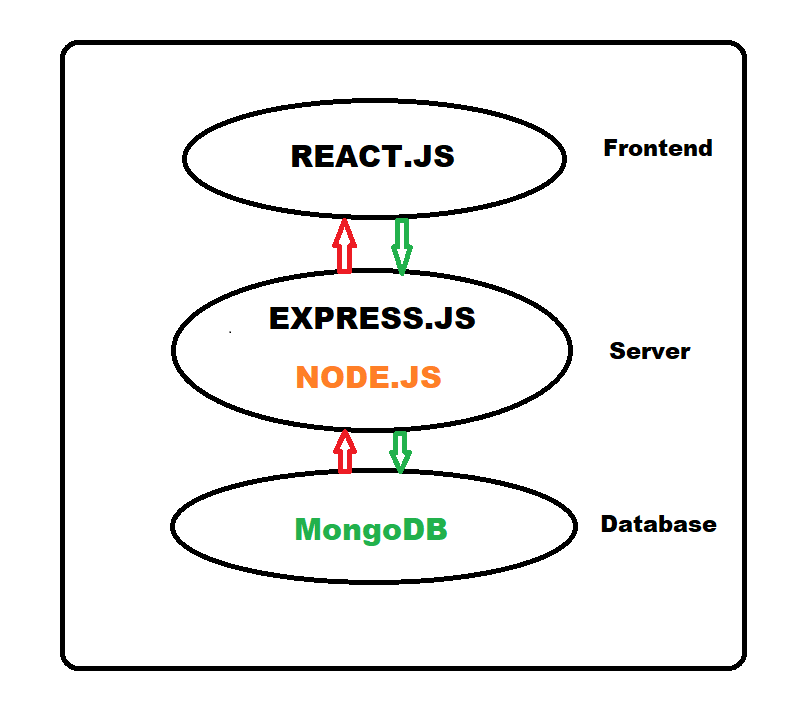
Использование веб-скрапинга
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.