StyleGAN - состязательные сети, генерирующие стиль
Генеративные состязательные сети (GAN) были предложены Яном Гудфеллоу в 2014 году. С момента их создания было предложено множество улучшений, которые сделали его современным методом генерации синтетических данных, включая синтетические изображения. Однако большая часть этих улучшений была внесена в дискриминаторную часть модели, которая улучшает генерирующую способность генератора. Это также означает, что не уделялось много внимания генераторной части, что приводит к отсутствию контроля над генераторной частью GAN. Есть некоторые параметры, которые можно изменить во время генерации, такие как фон, передний план и стиль, или для человеческих лиц есть много функций, которые можно изменить при генерации различных изображений, таких как поза, цвет волос, цвет глаз и т. Д.
Стиль GAN предлагает множество изменений в части генератора, что позволяет генерировать фотореалистичные высококачественные изображения, а также изменять некоторые части части генератора.
Архитектура:
Стиль GAN использует базовую прогрессивную архитектуру GAN и предлагает некоторые изменения в ее генераторной части. Однако архитектура дискриминатора очень похожа на базовую прогрессивную GAN. Давайте посмотрим на эти архитектурные изменения одно за другим.
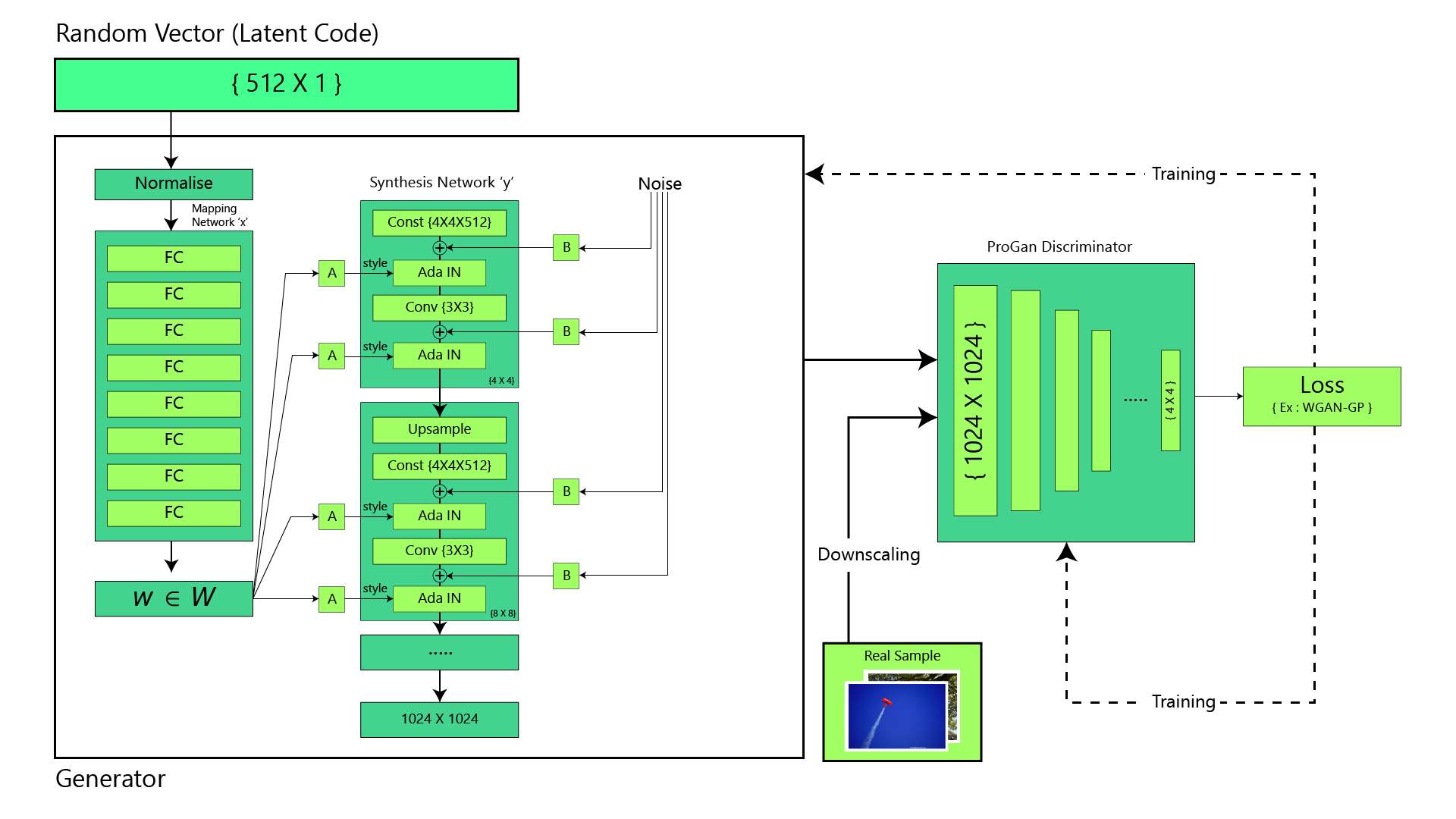
- Базовые прогрессивные растущие сети GAN: стиль GAN использует базовую прогрессивную архитектуру GAN, что означает, что размер сгенерированного изображения постепенно увеличивается от очень низкого разрешения (4 × 4) до высокого разрешения (1024 x 1024) . Это делается путем добавления нового блока к обеим моделям для поддержки большего разрешения после установки модели на меньшее разрешение, чтобы сделать ее более стабильной.
- Билинейная выборка: авторы статьи используют билинейную выборку вместо восходящей / понижающей выборки ближайшего соседа (которая использовалась в предыдущих базовых архитектурах GAN с прогрессивной разверткой) как в генераторе, так и в дискриминаторе. Они реализуют эту билинейную выборку путем фильтрации нижних частот при активации с помощью отделяемого биномиального фильтра 2-го порядка после каждого из слоев повышающей дискретизации и перед каждым из слоев понижающей дискретизации.
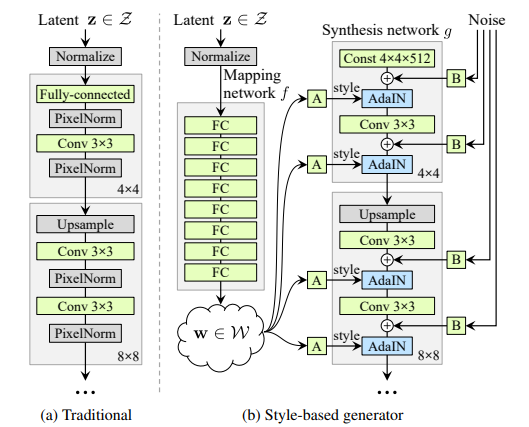
- Сеть отображения и сеть стилей : цель сети отображения - сгенерировать входной скрытый вектор в промежуточный вектор, различные элементы которого управляют различными визуальными характеристиками. Вместо того, чтобы напрямую предоставлять скрытый вектор для входного слоя, используется отображение. В этой статье скрытый вектор (z) размера 512 отображается на другой вектор 512 (w). Функция отображения реализована с использованием 8-слойного MLP (8-ми полносвязных слоев). Выходные данные отображающей сети (w) затем проходят через выученное аффинное преобразование (A) перед передачей в сеть синтеза, которую модуль AdaIN (адаптивная нормализация экземпляров). Эта модель преобразует закодированное отображение в сгенерированное изображение.
- Входными данными в AdaIN является y = (y s, y b ), который генерируется применением (A) к (w). Операция AdaIN определяется следующим уравнением:
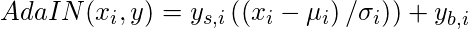
где каждая карта характеристик x нормализуется отдельно, а затем масштабируется и смещается с использованием соответствующих скалярных компонентов из стиля y . Таким образом, размер y в два раза больше количества карт признаков (x) на этом слое. Сеть синтеза содержит 18 сверточных слоев 2 для каждого разрешения (4 × 4 - 1024 × 1024).
- Удаление традиционного (скрытого) ввода: Большинство предыдущих моделей передачи стиля использовали случайный ввод для создания начального скрытого кода генератора, то есть ввода уровня 4 × 4. Однако авторы style-GAN пришли к выводу, что функции генерации изображений контролируются w и AdaIN. Поэтому они заменяют исходный ввод постоянной матрицей 4x4x512. Это также способствовало увеличению производительности сети.
- Добавление шума: входной сигнал Гауссов шум (обозначенный буквой B) добавляется к каждой из этих карт активации перед операциями AdaIN. Для каждого блока генерируется разная выборка шума, которая интерпретируется на основе коэффициентов масштабирования этого уровня.
- В лицах людей есть много аспектов, которые маленькие и могут рассматриваться как стохастические, такие как веснушки, точное расположение волосков, морщины, особенности, которые делают изображение более реалистичным и увеличивают разнообразие результатов. Распространенный метод вставки этих небольших элементов в изображения GAN - это добавление случайного шума к входному вектору.
- Регуляризация смешивания: Генерация стиля использовала промежуточный вектор на каждом уровне сети синтеза, что могло заставить сеть изучить корреляцию между разными уровнями. Чтобы уменьшить корреляцию, модель случайным образом выбирает два входных вектора (z 1 и z 2 ) и генерирует для них промежуточный вектор (w 1 и w 2 ). Затем он тренирует некоторые уровни с первым и переключается (в случайной точке разделения) на другой, чтобы обучить остальные уровни. Этот переключатель в случайных точках разделения гарантирует, что сеть не очень сильно узнает корреляцию.
Стиль на основе разрешения:

Чтобы иметь больший контроль над стилями сгенерированного изображения, сеть синтеза обеспечивает контроль над стилем с различным уровнем детализации (или разрешения). Эти разные уровни определяются как:
- Грубое - разрешение ( 4 × 4 - 8 × 8 ) - влияет на позу, общую прическу, форму лица и т. Д.
- Среднее - разрешение ( 16 × 16 - 32 × 32 ) - влияет на более тонкие черты лица, прическу, открытые / закрытые глаза и т. Д.
- Высокое - разрешение ( 64 × 64 - 1024 × 1024 ) - влияет на цвета (глаза, волосы и кожа) и микрочипы.
Автор этой статьи также варьировал шум между этими уровнями. Таким образом, шум возьмет на себя управление изменениями стиля на этом уровне. Например: шум на грубом уровне вызывает изменения в более широкой структуре, а на высоком уровне вызывает изменения в более мелких деталях изображения.
Исследования по распутыванию функций :
Цель этого исследования распутывания признаков - измерить вариацию разделения признаков. В этой статье автор представляет две отдельные метрики для распутывания функций:
- Перцепционная длина пути : в этой метрике мы измеряем взвешенную разницу между встраиванием VGG двух последовательных изображений при интерполяции между двумя случайными входными данными.
- Средняя воспринимаемая длина пути в скрытом пространстве Z определяется по всем возможным конечным точкам и определяется как:
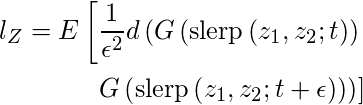
- где z1, z2? P (z), t? U (0, 1), G - генератор (т. Е. G? F для сетей на основе стилей), а d (·, ·) оценивает воспринимаемое расстояние между результирующими изображениями. Здесь slerp означает сферическую интерполяцию. Резкие изменения расстояния восприятия означают, что несколько функций изменились вместе и что они могут быть запутаны.
- Линейная разделимость : в этом методе мы смотрим, насколько хорошо точки скрытого пространства можно разделить на два отдельных набора с помощью линейной гиперплоскости, чтобы каждый набор соответствовал определенному двоичному атрибуту изображения. Например, каждое из изображений лица принадлежит мужчине или женщине.
Авторы этой статьи применили эти метрики как к w (промежуточное отображение), так и к z (скрытое пространство) и пришли к выводу, что w более разделимы. Это также подчеркивает важность 8-уровневой картографической сети.
Полученные результаты:

В этой статье представлены самые современные результаты по набору данных Celeba-HQ. В этом документе также предлагается новый набор данных человеческих лиц, называемый набором данных Flicker Face HQ (FFHQ), который имеет значительно больше вариаций, чем Celeba-HQ. эта архитектура стиля GAN дает довольно хорошие результаты также на наборе данных FFHQ. Ниже приведены результаты (оценка FID) этой архитектуры для этих двух наборов данных.
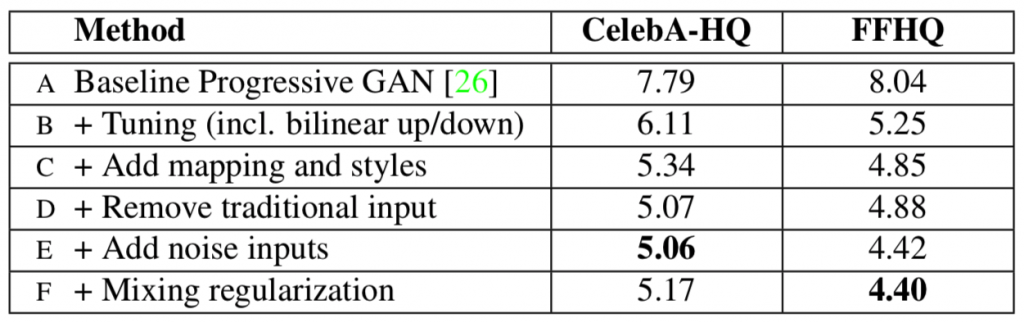
Здесь мы вычисляем оценку FID, используя 50000 случайно выбранных изображений из обучающего набора, и берем наименьшее расстояние, встреченное в ходе обучения.
Рекомендации:
- Бумага StyleGAN