Очистите контент с динамических веб-сайтов
Чтобы очистить контент со статической страницы, мы используем BeautifulSoup в качестве нашего пакета для очистки, и он безупречно работает со статическими страницами. Мы используем запросы для загрузки страницы в наш скрипт Python. Теперь, если страница, которую мы пытаемся загрузить, является динамической по своей природе, и мы запрашиваем эту страницу с помощью библиотеки запросов, она отправит код JS для локального выполнения. Пакет запросов не выполняет этот JS-код, а просто предоставляет его в качестве источника страницы.
BeautifulSoup не улавливает взаимодействия с DOM через Java Script. Предположим, у вас есть таблица, созданная JS. BeautifulSoup не сможет его захватить, в то время как Selenium может.
Если бы была необходимость очистить статические веб-сайты, мы бы использовали только bs4. Но для динамически генерируемых веб-страниц мы используем селен.
Селен
Selenium - это бесплатная автоматизированная среда тестирования (с открытым исходным кодом), используемая для проверки веб-приложений в различных браузерах и платформах. Вы можете использовать несколько языков программирования, таких как Java, C #, Python и т. Д., Для создания тестовых скриптов Selenium. Здесь мы используем Python в качестве основного языка.
Сначала установка:
1) Привязки селена в питоне
pip установить селен
2) Веб-драйверы
Selenium требует, чтобы веб-драйвер взаимодействовал с выбранным браузером. Веб-драйверы - это пакет для взаимодействия с веб-браузером. Он взаимодействует с веб-браузером или удаленным веб-сервером через общий для всех проводной протокол. Вы можете проверить и установить веб-драйверы по выбору вашего браузера.
Chrome: https://sites.google.com/a/chromium.org/chromedriver/downloads Firefox: https://github.com/mozilla/geckodriver/releases Safari: https://webkit.org/blog/6900/webdriver-support-in-safari-10/
Beautifulsoup
Beautifulsoup - это библиотека Python для извлечения данных из файлов HTML и XML. Он работает с вашим любимым парсером, обеспечивая идиоматические способы навигации, поиска и изменения дерева синтаксического анализа. Обычно это экономит программистам часы или дни работы.
Чтобы приготовить красивый суп, у нас есть его замечательная привязка к питону:
1) привязки BS4 в python
pip install bs4
Let’s suppose the site is dynamic and simple scraping leads to returning a Nonetype object.
#### This program scrapes naukri.com"s page and gives our result as a #### list of all the job_profiles which are currently present there. import requestsfrom bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time #url of the page we want to scrape # initiating the webdriver. Parameter includes the path of the webdriver.driver = webdriver.Chrome("./chromedriver") driver.get(url) # this is just to ensure that the page is loadedtime.sleep(5) html = driver.page_source # this renders the JS code and stores all# of the information in static HTML code. # Now, we could simply apply bs4 to html variablesoup = BeautifulSoup(html, "html.parser")all_divs = soup.find("div", {"id" : "nameSearch"})job_profiles = all_divs.find_all("a") # printing top ten job profilescount = 0for job_profile in job_profiles : print(job_profile.text) count = count + 1 if(count == 10) : break driver.close() # closing the webdriver |
Вот видео скребка в действии: Working_scraper_video
Вывод кода:
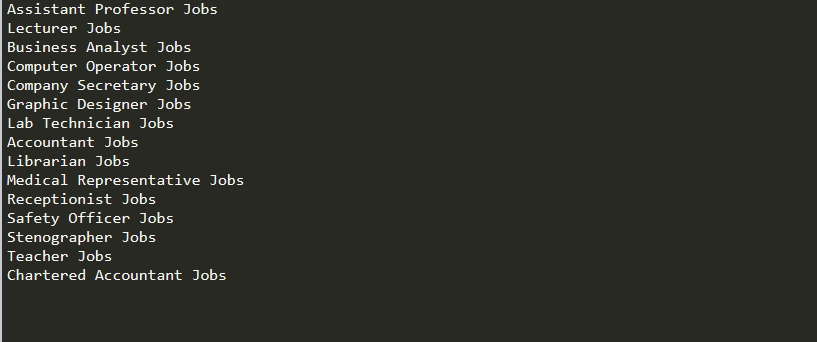
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.