Нормальное распределение в R
Нормальное распределение - это функция вероятности, используемая в статистике, которая сообщает о том, как распределяются значения данных. Это наиболее важная функция распределения вероятностей, используемая в статистике, из-за ее преимуществ в реальных сценариях. Например, рост населения, размер обуви, уровень IQ, игра в кости и многое другое.
Обычно наблюдается нормальное распределение данных при случайном сборе данных из независимых источников. График, полученный после нанесения значения переменной на ось x и подсчета значений на оси y, представляет собой колоколообразный график. График означает, что точка пика является средним значением набора данных, а половина значений набора данных лежит слева от среднего, а другая половина находится в правой части среднего, что говорит о распределении значений. График симметричного распределения.
В R есть 4 встроенные функции для генерации нормального распределения:
- dnorm ()
dnorm (x, среднее, стандартное отклонение)
- pnorm ()
pnorm (x, среднее, стандартное отклонение)
- qnorm ()
qnorm (p, среднее, sd)
- rnorm ()
rnorm (n, среднее, стандартное отклонение)
где,
– x represents the data set of values
– mean(x) represents the mean of data set x. It’s default value is 0.– sd(x) represents the standard deviation of data set x. It’s default value is 1.
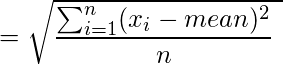
– n is the number of observations.
– p is vector of probabilities
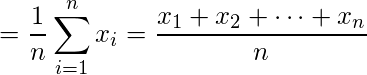
Функции для генерации нормального распределения в R
dnorm ()
dnorm() в программировании на R измеряет функцию плотности распределения. В статистике это измеряется по следующей формуле:
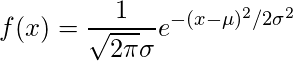
где, 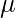 это подло и
это подло и 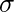 стандартное отклонение.
стандартное отклонение.
Синтаксис:
dnorm (x, среднее, стандартное отклонение)
Пример:
# creating a sequence of values# between -15 to 15 with a difference of 0.1x = seq( - 15 , 15 , by = 0.1 ) y = dnorm(x, mean(x), sd(x)) # output to be present as PNG filepng( file = "dnormExample.png" ) # Plot the graph.plot(x, y) # saving the filedev.off() |
Выход: 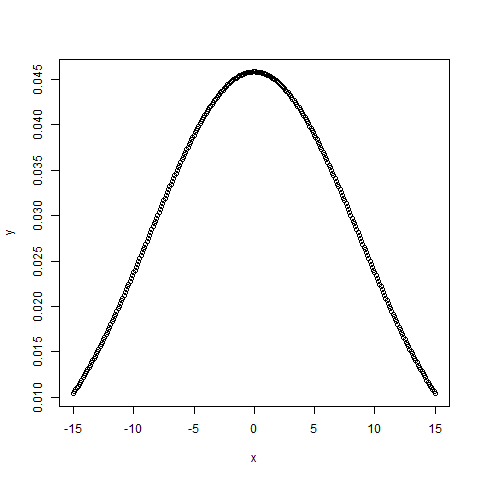
pnorm ()
pnorm() - это кумулятивная функция распределения, которая измеряет вероятность того, что случайное число X примет значение, меньшее или равное x, то есть в статистике оно задается следующим образом:
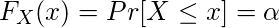
Синтаксис:
pnorm (x, среднее, стандартное отклонение)
Пример:
# creating a sequence of values# between -10 to 10 with a difference of 0.1x < - seq( - 10 , 10 , by = 0.1 ) y < - pnorm(x, mean = 2.5 , sd = 2 ) # output to be present as PNG filepng( file = "pnormExample.png" ) # Plot the graph.plot(x, y) # saving the filedev.off() |
Выход : 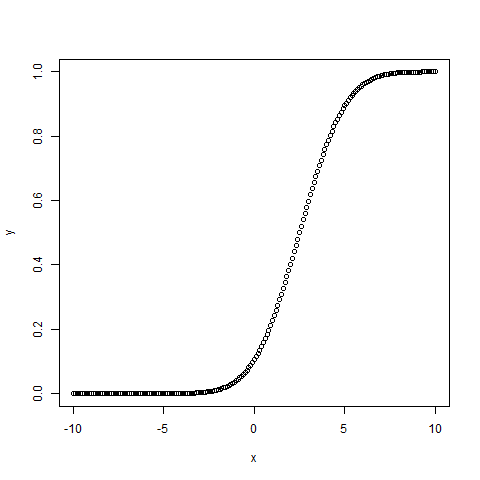
qnorm ()
qnorm() является обратной pnorm() . Он принимает значение вероятности и дает результат, соответствующий значению вероятности. Это полезно для определения процентилей нормального распределения.
Синтаксис:
qnorm (p, среднее, sd)
Пример:
# Create a sequence of probability values# incrementing by 0.02.x < - seq( 0 , 1 , by = 0.02 ) y < - qnorm(x, mean(x), sd(x)) # output to be present as PNG filepng( file = "qnormExample.png" ) # Plot the graph.plot(x, y) # Save the file.dev.off() |
Выход: 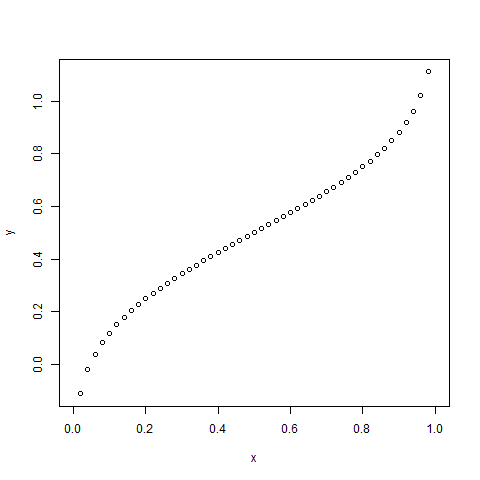
rnorm ()
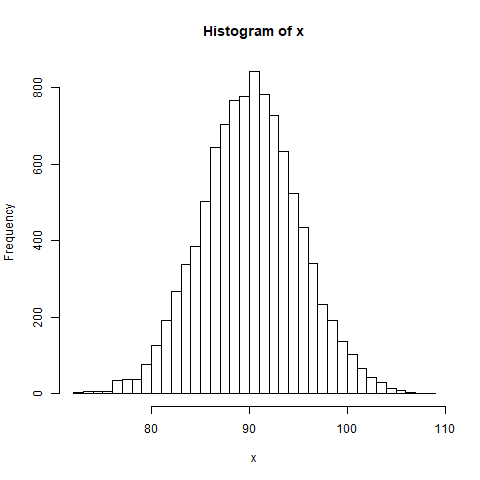
rnorm() в программировании на R используется для генерации вектора случайных чисел с нормальным распределением.
Синтаксис:
rnorm (x, среднее, стандартное отклонение)
Пример:
# Create a vector of 1000 random numbers# with mean=90 and sd=5x < - rnorm( 10000 , mean = 90 , sd = 5 ) # output to be present as PNG filepng( file = "rnormExample.png" ) # Create the histogram with 50 barshist(x, breaks = 50 ) # Save the file.dev.off() |
Выход :