ML | Введение в оптимизатор градиента на основе импульса
Градиентный спуск - это метод оптимизации, используемый в рамках машинного обучения для обучения различных моделей. Процесс обучения состоит из целевой функции (или функции ошибок), которая определяет ошибку, которую модель машинного обучения имеет в данном наборе данных.
Во время обучения параметры этого алгоритма инициализируются случайными значениями. По мере повторения алгоритма параметры обновляются, так что мы приближаемся к оптимальному значению функции.
Однако алгоритмы адаптивной оптимизации набирают популярность из-за их способности быстро сходиться. Все эти алгоритмы, в отличие от обычного градиентного спуска, используют статистику предыдущих итераций для робастизации процесса сходимости.
Оптимизация на основе импульса:
Алгоритм адаптивной оптимизации, который использует экспоненциально взвешенные средние градиентов по предыдущим итерациям для стабилизации сходимости, что приводит к более быстрой оптимизации. Например, в большинстве реальных приложений глубоких нейронных сетей обучение проводится на зашумленных данных. Следовательно, необходимо уменьшить влияние шума, когда данные подаются пакетами во время оптимизации. Эту проблему можно решить с помощью экспоненциально взвешенных средних (или экспоненциально взвешенных скользящих средних).
Внедрение экспоненциально взвешенных средних:
Чтобы аппроксимировать тенденции в зашумленном наборе данных размера N: 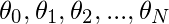 , мы поддерживаем набор параметров
, мы поддерживаем набор параметров 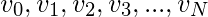 . По мере того, как мы перебираем все значения в наборе данных, мы вычисляем параметры, как показано ниже:
. По мере того, как мы перебираем все значения в наборе данных, мы вычисляем параметры, как показано ниже:
На итерации t:
Получить дальше 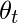
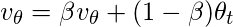
Этот алгоритм усредняет значение 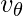 по сравнению с предыдущими
по сравнению с предыдущими 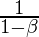 итераций. Это усреднение гарантирует, что сохраняется только тенденция, а шум усредняется. Этот метод используется в качестве стратегии градиентного спуска на основе импульса, чтобы сделать его устойчивым к шуму в выборках данных, что приводит к более быстрому обучению.
итераций. Это усреднение гарантирует, что сохраняется только тенденция, а шум усредняется. Этот метод используется в качестве стратегии градиентного спуска на основе импульса, чтобы сделать его устойчивым к шуму в выборках данных, что приводит к более быстрому обучению.
Например, если вы оптимизируете функцию 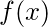 по параметру
по параметру 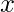 следующий псевдокод иллюстрирует алгоритм:
следующий псевдокод иллюстрирует алгоритм:
На итерации t:
В текущем пакете вычислить 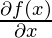
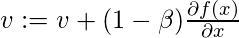
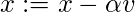
Гиперпараметры для этого алгоритма оптимизации: 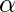 , называется скоростью обучения и,
, называется скоростью обучения и, 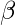 , похоже на ускорение в механике.
, похоже на ускорение в механике.
Ниже приведена реализация градиентного спуска на основе Momentum для функции. 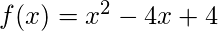 :
:
import math # HyperParameters of the optimization algorithmalpha = 0.01beta = 0.9 # Objective functiondef obj_func(x): return x * x - 4 * x + 4 # Gradient of the objective functiondef grad(x): return 2 * x - 4 # Parameter of the objective functionx = 0 # Number of iterationsiterations = 0 v = 0 while ( 1 ): iterations + = 1 v = beta * v + ( 1 - beta) * grad(x) x_prev = x x = x - alpha * v print ( "Value of objective function on iteration" , iterations, "is" , x) if x_prev = = x: print ( "Done optimizing the objective function. " ) break |