ML | Обработка естественного языка с использованием глубокого обучения
Машинное понимание - очень интересная, но сложная задача в исследованиях как обработки естественного языка (НЛП), так и искусственного интеллекта (ИИ). Есть несколько подходов к задачам обработки естественного языка. Благодаря недавним достижениям в алгоритмах глубокого обучения, аппаратном обеспечении и удобных для пользователя API, таких как TensorFlow, некоторые задачи стали выполняться с определенной точностью. В этой статье содержится информация о реализациях TensorFlow различных моделей глубокого обучения с упором на проблемы обработки естественного языка. Цель этой проектной статьи - помочь машине понять смысл предложений, что повышает эффективность машинного перевода, и взаимодействовать с вычислительными системами для получения из них полезной информации.
Понимание обработки естественного языка:
Наша способность оценивать взаимосвязь между предложениями необходима для решения различных задач естественного языка, таких как обобщение текста, извлечение информации и машинный перевод. Эта задача формализована как задача вывода на естественном языке распознавания текстового следования (RTE), которая включает в себя классификацию отношений между двумя предложениями как следствие, противоречие или нейтральность. Например, посылка «Гарфилд - кот», естественно, влечет за собой утверждение «У Гарфилда есть лапы», противоречит утверждению «Гарфилд - немецкая овчарка» и нейтральна по отношению к утверждению «Гарфилд любит спать».
Обработка естественного языка - это способность компьютерной программы понимать человеческий язык во время разговора. НЛП - это компонент искусственного интеллекта, который занимается взаимодействием между компьютером и человеческими языками в отношении обработки и анализа больших объемов данных на естественном языке. Обработка естественного языка может выполнять несколько различных задач, обрабатывая естественные данные с помощью различных эффективных средств. Эти задачи могут включать:
- Отвечать на вопросы о чем угодно (что могут делать Siri *, Alexa * и Cortana *).
- Анализ настроений (определение положительного, отрицательного или нейтрального отношения).
- Отображение изображения в текст (создание подписей с использованием входного изображения).
- Машинный перевод (перевод текста на разные языки).
- Распознавание речи
- Тегирование части речи (POS).
- Идентификация сущности
Традиционный подход к НЛП требует обширных знаний в области самой лингвистики.
Глубокое обучение на самом базовом уровне - это репрезентативное обучение. В сверточных нейронных сетях (CNN) композиция различных фильтров используется для классификации объектов по категориям. Используя аналогичный подход, эта статья создает представления слов в больших наборах данных.
Разговорный ИИ: особенности обработки естественного языка
- Обработка естественного языка (NLP)
- Текстовый интеллектуальный анализ (TM)
- Компьютерная лингвистика (CL)
- Машинное обучение текстовых данных (ML в тексте)
- Подходы с глубоким изучением текстовых данных (DL по тексту)
- Понимание естественного языка (NLU)
- Генерация естественного языка (NLG)
Разговорный ИИ за последние годы добился нескольких поразительных достижений, включая значительные улучшения в автоматическом распознавании речи (ASR), преобразовании текста в речь (TTS) и распознавании намерений, а также значительный рост числа устройств голосового помощника, таких как Amazon Echo и Google. Дом.
Использование методов глубокого обучения может эффективно работать с проблемами, связанными с НЛП. В этой статье используются алгоритмы обратного распространения и стохастического градиентного спуска (SGD) 4 в моделях NLP.
Потери зависят от каждого элемента обучающего набора, особенно когда он требует больших вычислительных ресурсов, что в случае проблем NLP верно, поскольку набор данных велик. Поскольку градиентный спуск является итеративным, он должен выполняться в несколько этапов, что означает просмотр данных сотни и тысячи раз. Оцените потери, взяв средние потери из случайного небольшого набора данных, выбранного из большего набора данных. Затем вычислите производную для этого образца и предположите, что производная является правильным направлением для использования градиентного спуска. Это может даже увеличить потери, но не уменьшить их. Компенсируйте, делая это много раз, каждый раз делая очень маленькие шаги. Каждый шаг дешевле вычислять, и в целом производительность будет выше. Алгоритм SGD лежит в основе глубокого обучения.
Векторы слов:
Слова должны быть представлены в качестве входных данных для моделей машинного обучения, один из математических способов сделать это - использовать векторы. В английском языке около 13 миллионов слов, но многие из них связаны между собой.
Найдите N-мерное векторное пространство (где N << 13 миллионов), достаточное для кодирования всей семантики в нашем языке. Для этого необходимо понимание сходства и различия слов. Концепция векторов и расстояний между ними (косинус, евклидов и т. Д.) Может быть использована для поиска сходств и различий между словами. 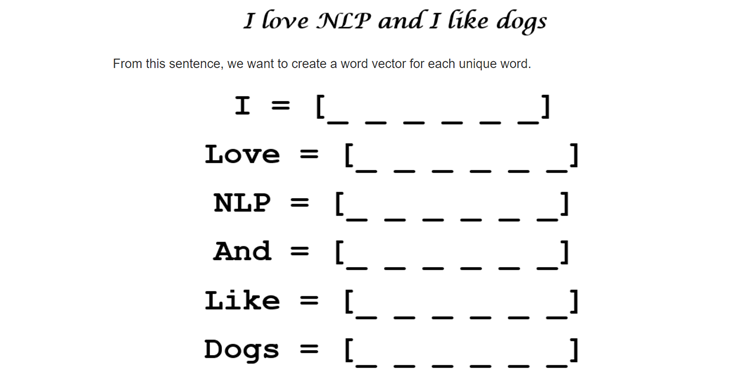
Как мы представляем значение слов?
Если использовать отдельные векторы для всех +13 миллионов слов в английском словаре, может возникнуть несколько проблем. Во-первых, будут большие векторы с множеством «нулей» и одной «единицей» (в разных позициях, представляющих другое слово). Это также известно как одноразовое кодирование. Во-вторых, при поиске таких фраз, как «отели в Нью-Джерси» в Google, ожидаются результаты, относящиеся к «мотель», «жилье», «проживание» в Нью-Джерси. А при использовании однократного кодирования эти слова не имеют естественного понятия сходства. В идеале скалярные произведения (поскольку мы имеем дело с векторами) синонимов / похожих слов были бы близки к одному из ожидаемых результатов.

Word2vec8 - это группа моделей, которая помогает установить отношения между словом и его контекстными словами. Начиная с небольшой случайной инициализации векторов слов, прогнозирующая модель изучает векторы, минимизируя функцию потерь. В Word2vec это происходит с помощью нейронной сети с прямой связью и методов оптимизации, таких как алгоритм SGD. Существуют также модели, основанные на подсчете, которые составляют матрицу подсчета совпадений слов в корпусе; с большой матрицей со строкой для каждого из «слов» и столбцами для «контекста». Число «контекстов», конечно, велико, поскольку оно по существу комбинаторное по размеру. Чтобы решить проблему размера, к матрице можно применить разложение по сингулярным числам, уменьшив размеры матрицы и сохранив максимум информации.
Программное и аппаратное обеспечение:
Используемый язык программирования - Python 3.5.2 с оптимизацией Intel для TensorFlow в качестве фреймворка. Для целей обучения и вычислений использовался Intel AI DevCloud на базе процессоров Intel Xeon Scalable. Intel AI DevCloud может обеспечить значительный прирост производительности центрального процессора для правильного приложения и варианта использования благодаря наличию 50+ ядер и собственной памяти, межсоединения и операционной системы.
Обучающие модели для НЛП: Langmod_nn и Memn2n-master
Модель Langmod_nn -
Модель Langmod_nn6 создает трехуровневую нейронную сеть модели прямой биграммы, состоящую из слоя внедрения, скрытого слоя и последнего слоя softmax, цель которого - использовать данное слово в корпусе, чтобы попытаться предсказать следующее слово.
Передать входные данные в один вектор с горячим кодированием размером 5000.
Input:
A word in a corpus. Because the vocabulary size can get very large, we have limited the vocabulary to the top 5000 words in the corpus, and the rest of the words are replaced with the UNK symbol. Each sentence in the corpus is also double-padded with stop symbols.Output:
The following word in the corpus also encoded one-hot in a vector the size of the vocabulary.
Слои -
Модель состоит из следующих трех слоев:
Слой вложения: каждое слово соответствует уникальному вектору вложения, представлению слова в некотором пространстве вложения. Здесь все вложения имеют размерность 50. Мы находим вложение для данного слова, выполняя матричное умножение (по сути, поиск в таблице) с матрицей вложения, которая обучается во время регулярного обратного распространения.
Скрытый слой: полностью связанный слой прямой связи с размером скрытого слоя 100 и активацией выпрямленного линейного блока (ReLU).
Softmax Layer: полностью связанный слой с прямой связью с размером слоя, равным размеру словаря, где каждый элемент выходного вектора (логиты) соответствует вероятности того, что это слово в словаре будет следующим словом.
Потеря - нормальная потеря кросс-энтропии между логитами и истинными метками как стоимость модели.
Оптимизатор -
Обычный оптимизатор SGD со скоростью обучения 0,05. 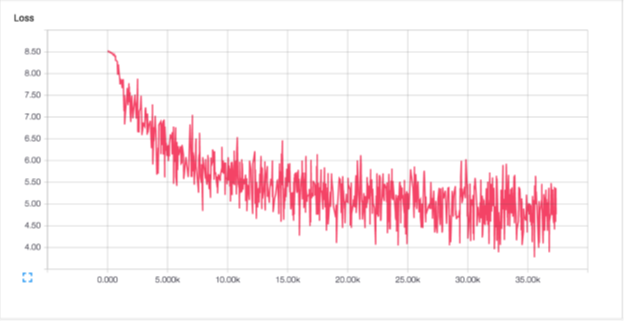
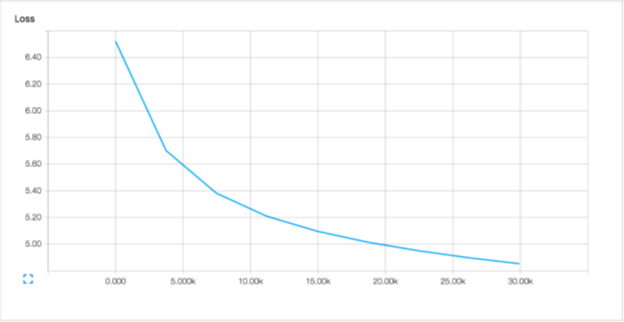
Каждая эпоха (около 480 000 примеров) занимает около 10 минут на обучение ЦП. Вероятность журнала испытаний после пятой эпохи составляет -846493,44.
Memn2n-master:
Memn2n-master7 - это нейронная сеть с моделью повторяющегося внимания через возможно большую внешнюю память. Архитектура представляет собой разновидность сети памяти, но в отличие от модели в этой работе, она обучается от начала до конца и, следовательно, требует значительно меньшего контроля во время обучения, что делает ее более применимой в реальных условиях.
Входные данные -
Этот каталог включает в себя первый набор из 20 задач для проверки понимания текста и рассуждений в проекте bAbI5. Мотив, стоящий за этими 20 задачами, заключается в том, что каждая задача проверяет уникальный аспект текста и рассуждений и, следовательно, проверяет различные способности обученных моделей.
И для тестирования, и для обучения у нас есть по 1000 вопросов. Однако мы не использовали такой объем данных, так как они могут быть бесполезны.
Результатами этой модели были точность тестирования 99,6%, точность обучения 97,6% и точность проверки 88%.
Фреймворк TensorFlow показал хорошие результаты для обучения моделей нейронных сетей с моделями NLP, показав хорошую точность. Результаты обучения, тестирования и проигрышей были отличными. Модель Langmod_nn и сети памяти дали хорошие показатели точности с низким значением потерь и ошибок. Гибкость модели памяти позволяет применять ее к таким разнообразным задачам, как ответы на вопросы и языковое моделирование.
Заключение:
Как показано, НЛП предоставляет широкий набор техник и инструментов, которые можно применять во всех сферах жизни. Изучая модели и используя их в повседневном общении, можно значительно улучшить качество жизни. Методы НЛП помогают улучшить общение, достичь целей и улучшить результаты каждого взаимодействия. НЛП помогает людям использовать инструменты и техники, которые им уже доступны. Правильно изучая техники НЛП, люди могут достигать целей и преодолевать препятствия.
В будущем НЛП выйдет за рамки статистических систем и систем, основанных на правилах, к естественному пониманию языка. Технические гиганты уже сделали некоторые улучшения. Например, Facebook * пытался использовать глубокое обучение для понимания текста без синтаксического анализа, тегов, распознавания именованных сущностей (NER) и т. Д., А Google пытается преобразовать язык в математические выражения. Обнаружение конечных точек с использованием грид-сетей с долговременной краткосрочной памятью и сквозных сетей памяти в задаче bAbI, выполняемой Google и Facebook соответственно, показывает прогресс, который может быть достигнут в моделях NLP.