ML | Начальная сеть V1
Inception net достигла вехи в классификаторах CNN, когда предыдущие модели просто углублялись, чтобы улучшить производительность и точность, но ставили под угрозу вычислительные затраты. С другой стороны, сеть Inception тщательно спроектирована. Он использует множество уловок для повышения производительности, как с точки зрения скорости, так и точности. Это победитель конкурса ImageNet Large Scale Visual Recognition Competition в 2014 году, конкурса классификации изображений, который имеет значительное улучшение по сравнению с ZFNet (Победитель в 2013 году), AlexNet (Победитель в 2012 году) и имеет относительно более низкий уровень ошибок по сравнению с VGGNet (1-е место, занявшее второе место в 2014 г.).
Основными проблемами, с которыми сталкиваются более глубокие модели CNN, такие как VGGNet, были:
- Хотя предыдущие сети, такие как VGG, достигли замечательной точности в наборе данных ImageNet, развертывание таких моделей требует больших вычислительных затрат из-за глубокой архитектуры.
- Очень глубокие сети подвержены переобучению. Также сложно передавать обновления градиента по всей сети.
Прежде чем углубляться в модель Inception Net, важно знать важную концепцию, которая используется в сети Inception:
Свертка 1 x 1: свертка 1 x 1 просто отображает входной пиксель со всеми его соответствующими каналами в выходной пиксель. Свертка 1 × 1 используется как модуль уменьшения размерности, чтобы до некоторой степени сократить объем вычислений.
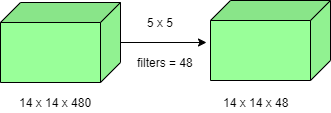
Количество задействованных операций составляет (14 × 14 × 48) × (5 × 5 × 480) = 112,9 млн.
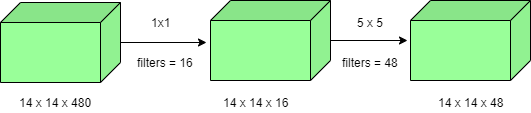
Количество операций для свертки 1 × 1 = (14 × 14 × 16) × (1 × 1 × 480) = 1,5 млн.
Количество операций для свертки 5 × 5 = (14 × 14 × 48) × (5 × 5 × 16) = 3,8 млн.
После сложения получаем 1,5 млн + 3,8 млн = 5,3 млн
Что намного меньше 112,9 млн! Таким образом, свертка 1 × 1 может помочь уменьшить размер модели, что также может каким-то образом помочь уменьшить проблему переобучения.
Начальная модель с уменьшением размеров: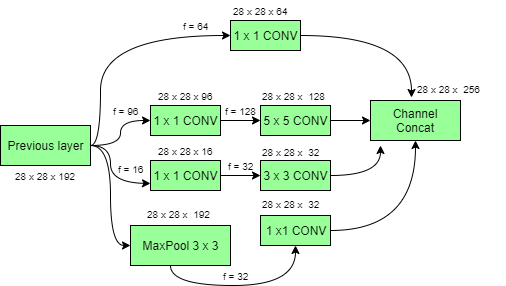
Глубокие сверточные сети требуют больших вычислительных ресурсов. Однако вычислительные затраты можно значительно снизить, введя свертку 1 x 1 . Здесь количество входных каналов ограничено добавлением дополнительной свертки 1 × 1 перед свертками 3 × 3 и 5 × 5 . Хотя добавление дополнительной операции может показаться нелогичным, но свертки 1 × 1 намного дешевле, чем свертки 5 × 5. Обратите внимание, что свертка 1 × 1 вводится после слоя max-pooling, а не до него. Наконец, все каналы в сети объединяются вместе, т.е. (28 x 28 x (64 + 128 + 32 + 32)) = 28 x 28 x 256.
Архитектура начальной сети GoogLeNet:
Всего в этой архитектуре 22 слоя! Используя начальный модуль с уменьшенной размерностью, строится архитектура нейронной сети. Это широко известно как GoogLeNet (Inception v1) . GoogLeNet имеет 9 таких начальных модулей, установленных линейно. Он имеет глубину 22 слоя ( 27 , включая слои объединения). В конце архитектуры полностью связанные слои были заменены глобальным средним пулом, который вычисляет среднее значение каждой карты функций. Это действительно резко снижает общее количество параметров.
Таким образом, Inception Net - это победа над предыдущими версиями моделей CNN. Он достигает пятерки лучших в ImageNet, это значительно снижает вычислительные затраты без ущерба для скорости и точности.