ML | Логистическая регрессия с использованием Tensorflow
Предварительные требования: понимание логистической регрессии и TensorFlow.
Краткое описание логистической регрессии:
Логистическая регрессия - это алгоритм классификации, обычно используемый в машинном обучении. Он позволяет классифицировать данные по дискретным классам, изучая взаимосвязь из заданного набора помеченных данных. Он изучает линейную зависимость из данного набора данных, а затем вводит нелинейность в форме сигмоидной функции.
В случае логистической регрессии гипотеза представляет собой сигмоид прямой линии, т. Е. 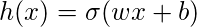 где
где 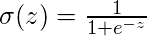
Где вектор w представляет веса, а скаляр b представляет смещение модели.
Давайте визуализируем сигмовидную функцию -
import numpy as npimport matplotlib.pyplot as plt def sigmoid(z): return 1 / ( 1 + np.exp( - z)) plt.plot(np.arange( - 5 , 5 , 0.1 ), sigmoid(np.arange( - 5 , 5 , 0.1 )))plt.title( 'Visualization of the Sigmoid Function' ) plt.show() |
Выход: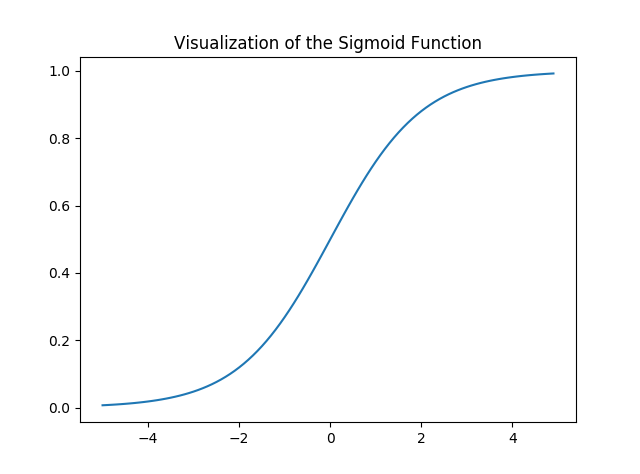
Обратите внимание, что диапазон сигмоидной функции составляет (0, 1), что означает, что результирующие значения находятся в диапазоне от 0 до 1. Это свойство сигмоидной функции делает ее действительно хорошим выбором функции активации для двоичной классификации. Также for z = 0, Sigmoid(z) = 0.5 который является средней точкой диапазона сигмовидной функции.
Как и в случае с линейной регрессией, нам нужно найти оптимальные значения w и b, для которых функция стоимости J минимальна. В этом случае мы будем использовать функцию стоимости сигмовидной перекрестной энтропии, которая определяется как 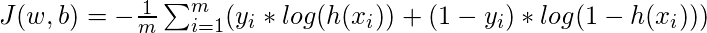
Затем эта функция стоимости будет оптимизирована с помощью градиентного спуска.
Выполнение:
Начнем с импорта необходимых библиотек. Мы будем использовать Numpy вместе с Tensorflow для вычислений, Pandas для базового анализа данных и Matplotlib для построения графиков. Мы также будем использовать модуль предварительной обработки Scikit-Learn для One Hot Encoding данных.
# importing modulesimport numpy as npimport pandas as pdimport tensorflow as tfimport matplotlib.pyplot as pltfrom sklearn.preprocessing import OneHotEncoder |
Далее мы будем импортировать набор данных. Мы будем использовать подмножество известного набора данных Iris.
data = pd.read_csv( 'dataset.csv' , header = None )print ( "Data Shape:" , data.shape) print (data.head()) |
Выход:
Форма данных: (100, 4) 0 1 2 3 0 0 5,1 3,5 1 1 1 4,9 3,0 1 2 2 4,7 3,2 1 3 3 4,6 3,1 1 4 4 5,0 3,6 1
Теперь давайте возьмем матрицу функций и соответствующие метки и визуализируем.
# Feature Matrixx_orig = data.iloc[:, 1 : - 1 ].values # Data labelsy_orig = data.iloc[:, - 1 :].values print ( "Shape of Feature Matrix:" , x_orig.shape)print ( "Shape Label Vector:" , y_orig.shape) |
Выход:
Форма матрицы признаков: (100, 2) Вектор метки формы: (100, 1)
Визуализируйте данные.
# Positive Data Pointsx_pos = np.array([x_orig[i] for i in range ( len (x_orig)) if y_orig[i] = = 1 ]) # Negative Data Pointsx_neg = np.array([x_orig[i] for i in range ( len (x_orig)) if y_orig[i] = = 0 ]) # Plotting the Positive Data Pointsplt.scatter(x_pos[:, 0 ], x_pos[:, 1 ], color = 'blue' , label = 'Positive' ) # Plotting the Negative Data Pointsplt.scatter(x_neg[:, 0 ], x_neg[:, 1 ], color = 'red' , label = 'Negative' ) plt.xlabel( 'Feature 1' )plt.ylabel( 'Feature 2' )plt.title( 'Plot of given data' )plt.legend() plt.show() |
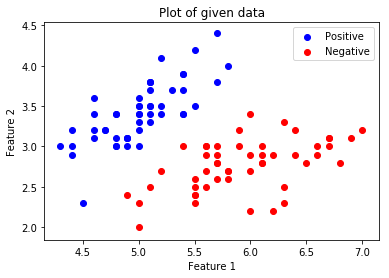 .
.
Теперь мы будем One Hot Encoding для работы с алгоритмом. Одно горячее кодирование преобразует категориальные функции в формат, который лучше работает с алгоритмами классификации и регрессии. Мы также будем устанавливать скорость обучения и количество эпох.
# Creating the One Hot EncoderoneHot = OneHotEncoder() # Encoding x_origoneHot.fit(x_orig)x = oneHot.transform(x_orig).toarray() # Encoding y_origoneHot.fit(y_orig)y = oneHot.transform(y_orig).toarray() alpha, epochs = 0.0035, 500m, n = x.shapeprint("m =", m)print("n =", n)print("Learning Rate =", alpha)print("Number of Epochs =", epochs) |
Выход:
м = 100 п = 7 Скорость обучения = 0,0035 Количество эпох = 500
Теперь мы начнем создание модели с определения заполнителей X и Y , чтобы мы могли передавать наши обучающие примеры x и y в оптимизатор во время процесса обучения. Мы также будем создавать обучаемые переменные W и b которые можно оптимизировать с помощью оптимизатора градиентного спуска.
# There are n columns in the feature matrix# after One Hot Encoding.X = tf.placeholder(tf.float32, [ None , n]) # Since this is a binary classification problem,# Y can take only 2 values.Y = tf.placeholder(tf.float32, [ None , 2 ]) # Trainable Variable WeightsW = tf.Variable(tf.zeros([n, 2 ])) # Trainable Variable Biasb = tf.Variable(tf.zeros([ 2 ])) |
Теперь объявите гипотезу, функцию стоимости, оптимизатор и инициализатор глобальных переменных.
# HypothesisY_hat = tf.nn.sigmoid(tf.add(tf.matmul(X, W), b)) # Sigmoid Cross Entropy Cost Functioncost = tf.nn.sigmoid_cross_entropy_with_logits( logits = Y_hat, labels = Y) # Gradient Descent Optimizeroptimizer = tf.train.GradientDescentOptimizer( learning_rate = alpha).minimize(cost) # Global Variables Initializerinit = tf.global_variables_initializer() |
Начните процесс обучения внутри сеанса Tensorflow.
# Starting the Tensorflow Sessionwith tf.Session() as sess: # Initializing the Variables sess.run(init) # Lists for storing the changing Cost and Accuracy in every Epoch cost_history, accuracy_history = [], [] # Iterating through all the epochs for epoch in range (epochs): cost_per_epoch = 0 # Running the Optimizer sess.run(optimizer, feed_dict = {X : x, Y : y}) # Calculating cost on current Epoch c = sess.run(cost, feed_dict = {X : x, Y : y}) # Calculating accuracy on current Epoch correct_prediction = tf.equal(tf.argmax(Y_hat, 1 ), tf.argmax(Y, 1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # Storing Cost and Accuracy to the history cost_history.append( sum ( sum (c))) accuracy_history.append(accuracy. eval ({X : x, Y : y}) * 100 ) # Displaying result on current Epoch if epoch % 100 = = 0 and epoch ! = 0 : print ( "Epoch " + str (epoch) + " Cost: " + str (cost_history[ - 1 ])) Weight = sess.run(W) # Optimized Weight Bias = sess.run(b) # Optimized Bias # Final Accuracy correct_prediction = tf.equal(tf.argmax(Y_hat, 1 ), tf.argmax(Y, 1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print ( "
Accuracy:" , accuracy_history[ - 1 ], "%" ) |
Выход:
Стоимость 100-й эпохи: 125.700202942 Стоимость эпохи 200: 120,647117615 Эпоха 300 Стоимость: 118.151592255 Эпоха 400 Стоимость: 116.549999237 Точность: 91.0000026226%
Построим график изменения стоимости по эпохам.
plt.plot( list ( range (epochs)), cost_history)plt.xlabel( 'Epochs' )plt.ylabel( 'Cost' )plt.title( 'Decrease in Cost with Epochs' ) plt.show() |
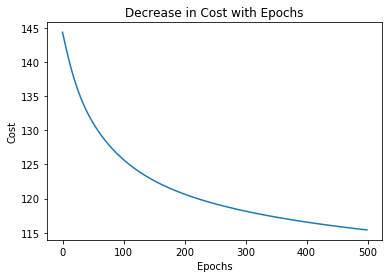
Постройте график изменения точности по эпохам.
plt.plot( list ( range (epochs)), accuracy_history)plt.xlabel( 'Epochs' )plt.ylabel( 'Accuracy' )plt.title( 'Increase in Accuracy with Epochs' ) plt.show() |

Теперь мы построим Границу принятия решения для нашего обученного классификатора. Граница решения - это гиперповерхность, которая разделяет базовое векторное пространство на два набора, по одному для каждого класса.
# Calculating the Decision Boundarydecision_boundary_x = np.array([np. min (x_orig[:, 0 ]), np. max (x_orig[:, 0 ])]) decision_boundary_y = ( - 1.0 / Weight[ 0 ]) * (decision_boundary_x * Weight + Bias) decision_boundary_y = [ sum (decision_boundary_y[:, 0 ]), sum (decision_boundary_y[:, 1 ])] # Positive Data Pointsx_pos = np.array([x_orig[i] for i in range ( len (x_orig)) if y_orig[i] = = 1 ]) # Negative Data Pointsx_neg = np.array([x_orig[i] for i in range ( len (x_orig)) if y_orig[i] = = 0 ]) # Plotting the Positive Data Pointsplt.scatter(x_pos[:, 0 ], x_pos[:, 1 ], color = 'blue' , label = 'Positive' ) # Plotting the Negative Data Pointsplt.scatter(x_neg[:, 0 ], x_neg[:, 1 ], color = 'red' , label = 'Negative' ) # Plotting the Decision Boundaryplt.plot(decision_boundary_x, decision_boundary_y)plt.xlabel( 'Feature 1' )plt.ylabel( 'Feature 2' )plt.title( 'Plot of Decision Boundary' )plt.legend() plt.show() |
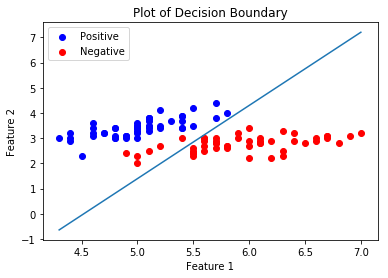
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.