Марковский процесс принятия решений
Обучение с подкреплением:
Обучение с подкреплением - это разновидность машинного обучения. Это позволяет машинам и программным агентам автоматически определять идеальное поведение в конкретном контексте, чтобы максимизировать его производительность. Чтобы агент узнал о своем поведении, требуется простая обратная связь с вознаграждением; это называется сигналом подкрепления.
Есть много разных алгоритмов, которые решают эту проблему. Фактически, обучение с подкреплением определяется конкретным типом проблемы, и все его решения классифицируются как алгоритмы обучения с подкреплением. В задаче предполагается, что агент выбирает наилучшее действие, исходя из своего текущего состояния. Когда этот шаг повторяется, проблема известна как процесс принятия решений Маркова .
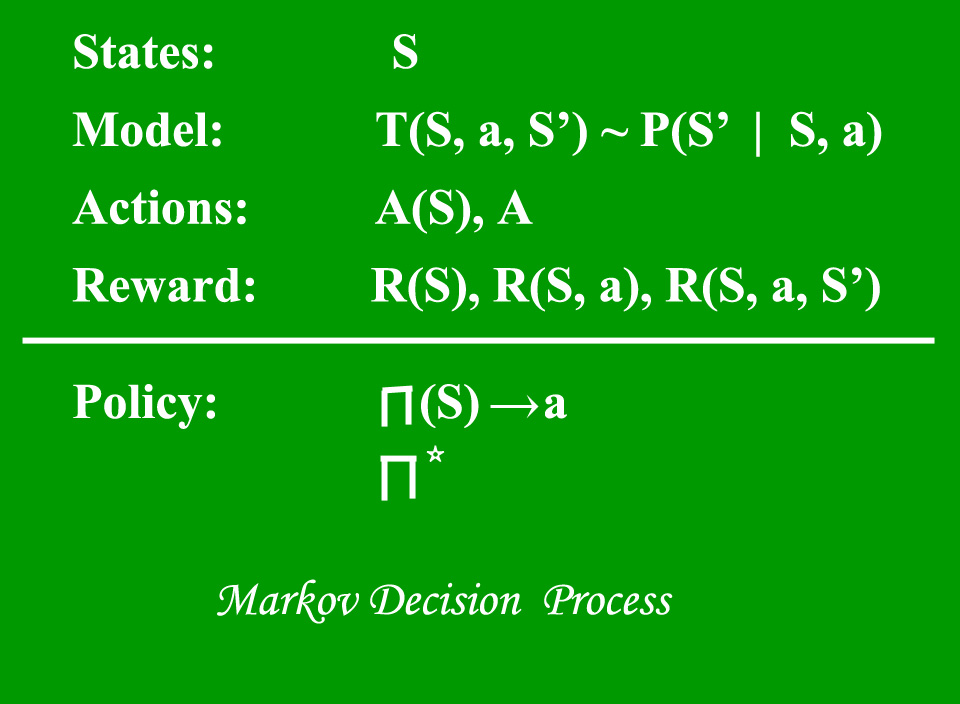
Модель Марковского процесса принятия решений (MDP) содержит:
- Набор возможных состояний мира S.
- Набор моделей.
- Набор возможных действий А.
- Действительная функция вознаграждения R (s, a).
- Политика решение Марковского процесса принятия решений .
Что такое государство?
Состояние - это набор токенов, которые представляют каждое состояние, в котором может находиться агент.
Что такое модель?
Модель (иногда называемая моделью перехода) дает эффект действия в состоянии. В частности, T (S, a, S ') определяет переход T, когда нахождение в состоянии S и выполнение действия «a» переводит нас в состояние S' (S и S 'могут быть одинаковыми). Для стохастических действий (шумных, недетерминированных) мы также определяем вероятность P (S '| S, a), которая представляет вероятность достижения состояния S', если действие 'a' выполняется в состоянии S. Примечание. Марковское свойство гласит, что эффекты действия, предпринятого в состоянии, зависят только от этого состояния, а не от предшествующей истории.
Что такое действия?
Действие A - это набор всех возможных действий. A (s) определяет набор действий, которые можно предпринять в состоянии S.
Что такое награда?
Награда - это функция вознаграждения с действительной стоимостью. R (s) указывает вознаграждение за простое пребывание в состоянии S. R (S, a) указывает вознаграждение за нахождение в состоянии S и выполнение действия «a». R (S, a, S ') указывает вознаграждение за нахождение в состоянии S, выполнение действия «a» и попадание в состояние S ».
Что такое политика?
Политика - это решение Марковского процесса принятия решений. Политика - это отображение от S к a. Он указывает действие 'a', которое нужно предпринять в состоянии S.
Давайте возьмем пример сеточного мира:
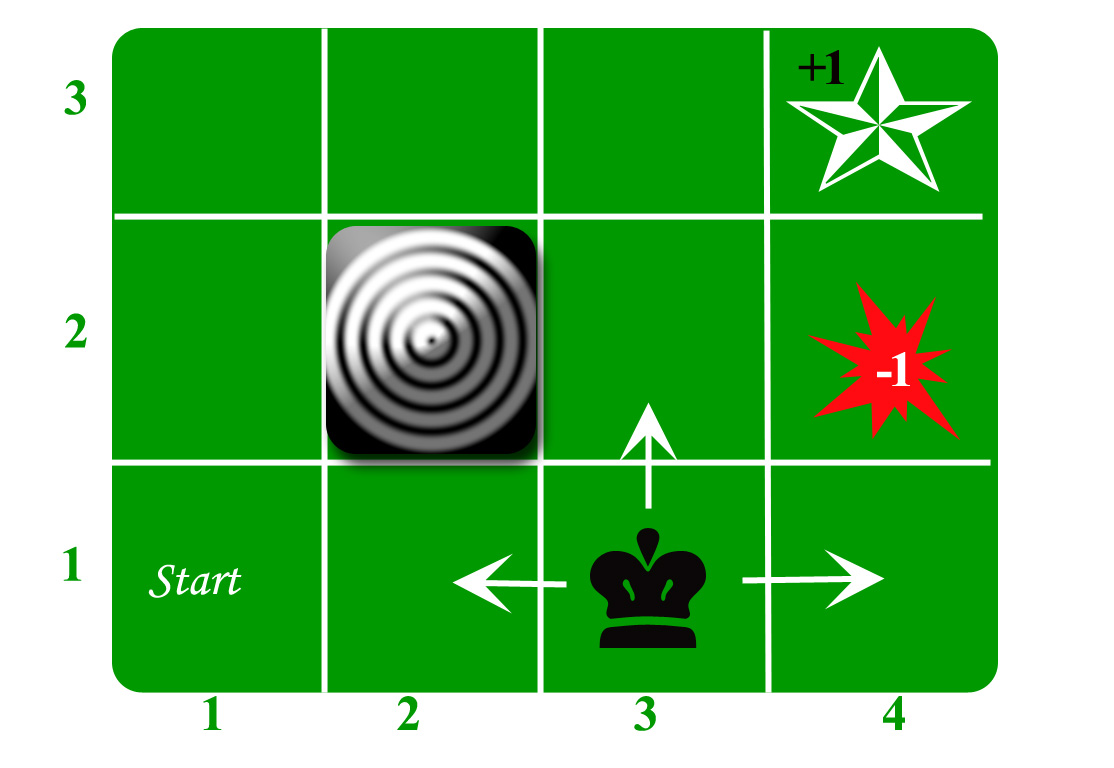
Агент живет в сети. Приведенный выше пример представляет собой сетку 3 * 4. Сетка находится в состоянии СТАРТ (сетка № 1,1). Цель агента - бродить по сетке, чтобы наконец добраться до Голубого алмаза (сетка № 4,3). При любых обстоятельствах агент должен избегать сетки огня (оранжевый цвет, сетка № 4,2). Также сетка № 2,2 является заблокированной сеткой, она действует как стена, поэтому агент не может войти в нее.
Агент может выполнить одно из следующих действий: ВВЕРХ, ВНИЗ, ВЛЕВО, ВПРАВО.
Стены блокируют путь агента, т. Е. Если есть стена в том направлении, в котором агент мог бы двигаться, агент остается на том же месте. Так, например, если агент говорит ВЛЕВО в сетке СТАРТ, он останется в сетке СТАРТ.
Первая цель: найти кратчайший путь от СТАРТА до Бриллианта. Можно найти две такие последовательности:
- ВПРАВО ВПРАВО ВВЕРХ ВПРАВО
- ВВЕРХ ВВЕРХ ВПРАВО ВПРАВО
Давайте возьмем вторую (ВВЕРХ ВВЕРХ ВПРАВО ВПРАВО) для последующего обсуждения.
Движение сейчас шумное. 80% времени намеченное действие работает правильно. 20% времени действия агента заставляет его двигаться под прямым углом. Например, если агент говорит ВВЕРХ, вероятность движения ВВЕРХ составляет 0,8, тогда как вероятность движения ВЛЕВО равна 0,1, а вероятность движения ВПРАВО составляет 0,1 (поскольку ВЛЕВО и ВПРАВО являются прямыми углами к ВВЕРХ).
Агент получает вознаграждение за каждый временной шаг: -
- Небольшое вознаграждение за каждый шаг (может быть отрицательным, когда также может быть обозначено как наказание, в приведенном выше примере вход в Огонь может иметь награду -1).
- В конце приходят большие награды (хорошие или плохие).
- Цель состоит в том, чтобы максимизировать сумму вознаграждений.
Ссылки: http://reinforcementlearning.ai-depot.com/
http://artint.info/html/ArtInt_224.html