Корреляция рангов Спирмена
Что такое корреляционный тест?
Сила связи между двумя переменными известна как тест корреляции. Например, если нас интересует, существует ли связь между ростом отцов и сыновей, для ответа на этот вопрос можно рассчитать коэффициент корреляции.
Чтобы узнать больше о корреляции, обратитесь сюда.
Методы корреляционного анализа:
В основном есть два типа корреляции:
- Параметрическая корреляция - корреляция Пирсона (r): измеряет линейную зависимость между двумя переменными (x и y), известную как тест параметрической корреляции, поскольку она зависит от распределения данных.
- Непараметрическая корреляция - Кендалл (тау) и Спирмен (ро): это коэффициенты корреляции на основе ранга, известные как непараметрическая корреляция.
Формула корреляции Спирмена:
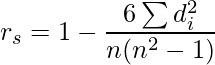
where,
rs = Spearman Correlation coefficient
di = the difference in the ranks given to the two variables values for each item of the data,
n = total number of observation
Пример : в ранговой корреляции Спирмена мы преобразуем данные, даже если это данные реального значения, в то, что мы называем рангами. Давайте рассмотрим 10 разных точек данных в переменных X 1 и Y 1 . И узнайте их соответствующие звания. Затем найдите квадрат разницы в рангах, присвоенных значениям двух переменных для каждого элемента данных.
| Число | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Х 1 | 7 | 6 | 4 | 5 | 8 | 7 | 10 | 3 | 9 | 2 |
| Y 1 | 5 | 4 | 5 | 6 | 10 | 7 | 9 | 2 | 8 | 1 |
| Ранг X 1 | 6.5 | 5 | 3 | 4 | 8 | 6.5 | 10 | 2 | 9 | 1 |
| Ранг Y 1 | 4.5 | 3 | 4.5 | 6 | 10 | 7 | 9 | 2 | 8 | 1 |
| d 2 | 4 | 4 | 2,25 | 4 | 4 | 0,25 | 1 | 0 | 1 | 0 |
Шаг 1. Определение ранга.
- Ранг X 1 : Итак, мы рассмотрели все индивидуальные значения X 1 и присвоили ему ранг. Например, наименьшее значение в этом случае равно 2, и ему присваивается ранг 1, следующее по величине значение - 3, которому присваивается ранг 2 и так далее. Итак, мы ранжировали все эти точки. Обратите внимание, что шестое и первое значения связаны. Таким образом, они получают рейтинг 6.5 (середина - половина), потому что есть ничья. Точно так же, если существует более двух связанных значений, мы берем все эти ранги и усредняем их по количеству точек данных, которые имеют равные значения, и, соответственно, вы должны дать ранг.
- Ранг Y 1 : Точно так же вы можете присвоить ранг точкам данных Y 1 таким же образом.
Шаг 2 : Рассчитайте d 2 -
Как только вы получили ранг, вы вычисляете разницу в рангах. Итак, в этом случае разница в ранге для первой точки данных равна 2, и мы возводим ее в квадрат, аналогично, мы берем разницу во второй точке данных в рангах между X i и Y i, которая равна 2, и возводим ее в квадрат и мы получаем 4. Таким образом, мы делаем разницу в рангах и возводя ее в квадрат, мы получаем окончательное то, что мы называем величиной d в квадрате. Мы суммируем общие значения, а затем вычисляем коэффициент Спирмена, используя это значение в приведенной выше формуле.
Положив значение общей суммы d 2 и значения n
rho / r s = 1 - ((6 х 20,5) / 990)
= 1 - (123/990)
= 1 - 0,1242
= 0,88
Свойства :
- r s принимает значение от -1 (отрицательная ассоциация) до 1 (положительная ассоциация).
- r s = 0 означает отсутствие ассоциации.
- Его можно использовать, когда ассоциация нелинейна.
- Его можно применять для порядковых переменных.
Корреляция Спирмена для данных Анскомба:
Данные Анскомба, также известные как квартет Анскомба, состоят из четырех наборов данных, которые имеют почти идентичные простые статистические свойства, но выглядят очень разными на графике. Каждый набор данных состоит из одиннадцати (x, y) точек. Они были построены в 1973 году статистиком Фрэнсисом Анскомбом, чтобы продемонстрировать как важность построения графиков данных перед их анализом, так и влияние выбросов на статистические свойства.
Эти 4 набора из 11 точек данных приведены здесь. Загрузите файл csv здесь.
Когда мы наносим эти точки на график, это выглядит так. Здесь я рассматриваю 3 набора из 11 точек данных.
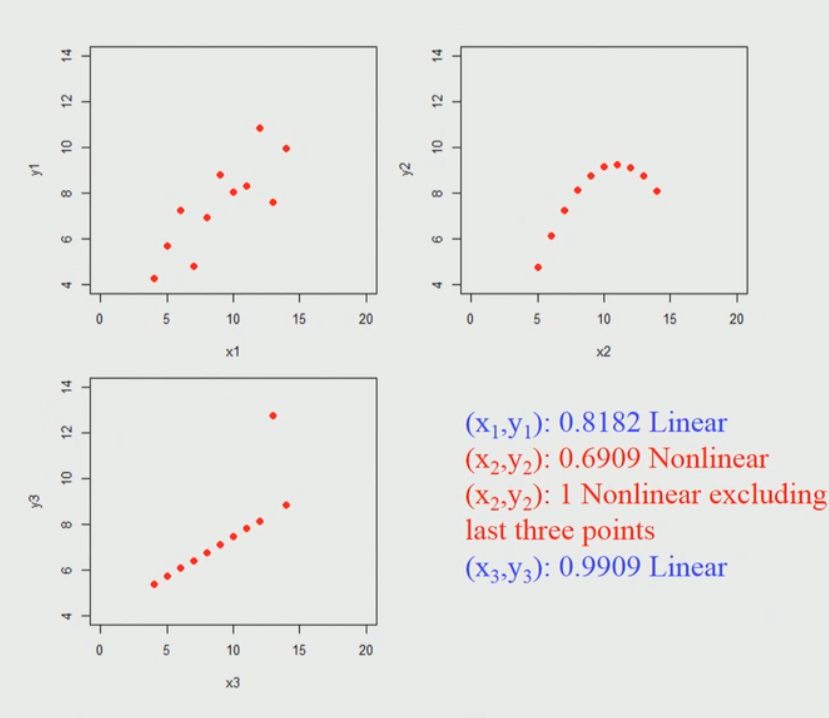
Краткое объяснение приведенной выше диаграммы:
Итак, если мы применим коэффициент корреляции Спирмена для каждого из этих наборов данных, мы обнаружим, что он почти идентичен, не имеет значения, применяете ли вы на самом деле к первому набору данных (вверху слева), второму набору данных (вверху справа) или третьему. набор данных (внизу слева). Итак, похоже, это указывает на то, что если мы применим корреляцию Спирмена и обнаружим достаточно высокий коэффициент корреляции, близкий к единице в этом первом наборе данных (вверху слева). Ключевым моментом здесь является то, что мы не можем сразу сделать вывод, что если коэффициент корреляции Спирмена будет высоким, то между ними существует линейная связь, например, во втором наборе данных (вверху справа) это нелинейная зависимость и по-прежнему дает достаточно высокое значение.