Классификаторы дерева решений в программировании на языке R
Классификация - это задача, в которой объекты нескольких категорий распределяются по соответствующим классам с использованием свойств классов. Классификационная модель обычно используется для:
- Предсказать метку класса для нового немаркированного объекта данных
- Предоставьте описательную модель, объясняющую, какие функции характеризуют объекты в каждом классе.
Существуют различные методы классификации, такие как,
- Логистическая регрессия
- Древо решений
- K-Ближайшие соседи
- Наивный байесовский классификатор
- Машины опорных векторов (SVM)
- Классификация случайных лесов
Классификаторы дерева решений
Дерево решений - это древовидная структура, подобная блок-схеме, в которой внутренний узел представляет функцию (или атрибут), ветвь представляет правило принятия решения, а каждый конечный узел представляет результат. Дерево решений состоит из:
- Узлы: проверка значения определенного атрибута.
- Ребра / ветвь: представляет правило принятия решения и подключение к следующему узлу.
- Концевые узлы: конечные узлы, которые представляют метки классов или распределение классов.
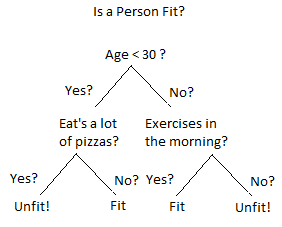
И этот алгоритм легко реализовать на языке R. Некоторые важные моменты о классификаторах дерева решений:
- Это более интерпретируемое
- Автоматически обрабатывает принятие решений
- Делит пространство пополам на более мелкие
- Склонен к переобучению
- Можно обучить на небольшом тренировочном наборе
- Сильно подвержен шуму
Реализация в R
Набор данных:
Выборочная группа из 400 человек поделилась своим возрастом, полом и зарплатой с продуктовой компанией, а также о том, купили они продукт или нет (0 означает нет, 1 означает да). Загрузите набор данных Advertising.csv.
р
# Importing the datasetdataset = read.csv ( 'Advertisement.csv' )head (dataset, 10) |
Выход: ID пользователя Пол Возраст Расчетная зарплата Куплено 0 15624510 Мужчина 19 19000 0 1 15810944 Мужчина 35 год 20000 0 2 15668575 женский 26 год 43000 0 3 15603246 женский 27 57000 0 4 15804002 Мужчина 19 76000 0 5 15728773 Мужчина 27 58000 0 6 15598044 женский 27 84000 0 7 15694829 женский 32 150000 1 8 15600575 Мужчина 25 33000 0 9 15727311 женский 35 год 65000 0
р
# Encoding the target feature as factordataset$Purchased = factor (dataset$Purchased, levels = c (0, 1)) # Splitting the dataset into# the Training set and Test set# install.packages('caTools')library (caTools)set.seed (123)split = sample.split (dataset$Purchased, SplitRatio = 0.75)training_set = subset (dataset, split == TRUE )test_set = subset (dataset, split == FALSE ) # Feature Scalingtraining_set[-3] = scale (training_set[-3])test_set[-3] = scale (test_set[-3]) # Fitting Decision Tree Classification# to the Training set# install.packages('rpart')library (rpart)classifier = rpart (formula = Purchased ~ ., data = training_set) # Predicting the Test set resultsy_pred = predict (classifier, newdata = test_set[-3], type = 'class' ) # Making the Confusion Matrixcm = table (test_set[, 3], y_pred) |
- Обучающий набор содержит 300 записей.
- Набор тестов содержит 100 записей.
Матрица неточностей: [[62, 6], [3, 29]]
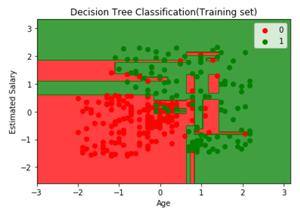
Визуализация данных поезда:
р
# Visualising the Training set results# Install ElemStatLearn if not present# in the packages using(without hashtag)# install.packages('ElemStatLearn')library (ElemStatLearn)set = training_set # Building a grid of Age Column(X1)# and Estimated Salary(X2) ColumnX1 = seq ( min (set[, 1]) - 1, max (set[, 1]) + 1, by = 0.01)X2 = seq ( min (set[, 2]) - 1, max (set[, 2]) + 1, by = 0.01)grid_set = expand.grid (X1, X2) # Give name to the columns of matrixcolnames (grid_set) = c ( 'Age' , 'EstimatedSalary' ) # Predicting the values and plotting them# to grid and labelling the axesy_grid = predict (classifier, newdata = grid_set, type = 'class' )plot (set[, -3], main = 'Decision Tree Classification (Training set)', xlab = 'Age' , ylab = 'Estimated Salary' , xlim = range (X1), ylim = range (X2))contour (X1, X2, matrix ( as.numeric (y_grid), length (X1), length (X2)), add = TRUE )points (grid_set, pch = '.' , col = ifelse (y_grid == 1, 'springgreen3' , 'tomato' ))points (set, pch = 21, bg = ifelse (set[, 3] == 1, 'green4' , 'red3' )) |
Выход:
Визуализация тестовых данных:
р
# Visualising the Test set resultslibrary (ElemStatLearn)set = test_set # Building a grid of Age Column(X1)# and Estimated Salary(X2) ColumnX1 = seq ( min (set[, 1]) - 1, max (set[, 1]) + 1, by = 0.01)X2 = seq ( min (set[, 2]) - 1, max (set[, 2]) + 1, by = 0.01)grid_set = expand.grid (X1, X2) # Give name to the columns of matrixcolnames (grid_set) = c ( 'Age' , 'EstimatedSalary' ) # Predicting the values and plotting them# to grid and labelling the axesy_grid = predict (classifier, newdata = grid_set, type = 'class' )plot (set[, -3], main = 'Decision Tree Classification (Test set)', xlab = 'Age' , ylab = 'Estimated Salary' , xlim = range (X1), ylim = range (X2))contour (X1, X2, matrix ( as.numeric (y_grid), length (X1), length (X2)), add = TRUE )points (grid_set, pch = '.' , col = ifelse (y_grid == 1, 'springgreen3' , 'tomato' ))points (set, pch = 21, bg = ifelse (set[, 3] == 1, 'green4' , 'red3' )) |
Выход:
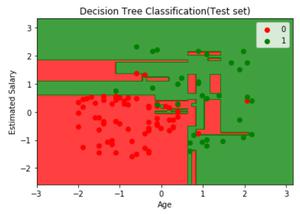
Диаграмма дерева решений:
р
# Plotting the treeplot (classifier)text (classifier) |
Выход: