Исследовательский анализ данных в программировании на R
Исследовательский анализ данных или EDA - это статистический подход или метод анализа наборов данных с целью обобщения их важных и основных характеристик, как правило, с использованием некоторых наглядных пособий. Подход EDA можно использовать для сбора информации о следующих аспектах данных:
- Основные характеристики или особенности данных.
- Переменные и их отношения.
- Выявление важных переменных, которые можно использовать в нашей задаче.
EDA - это итеративный подход, который включает:
- Создание вопросов о наших данных
- Поиск ответов с помощью визуализации, преобразования и моделирования наших данных.
- Используя полученные уроки, чтобы уточнить наш набор вопросов или создать новый набор вопросов.
Реализация в R
В языке R мы собираемся выполнить EDA по двум широким классификациям:
- Описательная статистика, которая включает среднее значение, медианное значение, режим, межквартильный диапазон и т. Д.
- Графические методы, которые включают гистограмму, оценку плотности, ящичные диаграммы и т. Д.
Прежде чем мы начнем работать с EDA, мы должны правильно провести проверку данных. Здесь, в нашем анализе, мы будем использовать loafercreek из пакета почвыDB в R. Мы собираемся проверить наши данные, чтобы найти все опечатки и вопиющие ошибки. Дальнейший EDA может быть использован для определения и идентификации выбросов и выполнения необходимого статистического анализа. Для выполнения EDA нам необходимо установить и загрузить следующие пакеты:
- Пакет «aqp»
- Пакет «ggplot2»
- Пакет «почвенная база данных»
Мы можем установить эти пакеты из консоли R с помощью команды install.packages () и загрузить их в наш сценарий R с помощью команды library () . Теперь мы увидим, как проверять наши данные и удалять опечатки и вопиющие ошибки.
Проверка данных для EDA в R
Чтобы гарантировать, что мы имеем дело с правильной информацией, нам необходимо четкое представление ваших данных на каждом этапе процесса преобразования. Проверка данных - это просмотр данных в целях проверки и отладки до, во время или после перевода. Теперь посмотрим, как проверять и удалять ошибки и опечатки в данных.
Пример:
р
# Data Inspection in EDA# loading the required packageslibrary (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and# add to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing of# the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) |
Выход:
> таблица (h $ genhz, h $ hzname)
2BCt 2Bt1 2Bt2 2Bt3 2Bt4 2Bt5 2CB 2CBt 2Cr 2Crt 2R A A1 A2 AB ABt Ad Ap B BA BAt BC BCt Bt Bt1 Bt2 Bt3 Bt4 Bw Bw1 Bw2 Bw3 C
А 0 0 0 0 0 0 0 0 0 0 0 97 7 7 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
BAt 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 31 8 0 0 0 0 0 0 0 0 0 0 0 0
Bt1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 8 94 89 0 0 10 2 2 1 0
Bt2 1 2 7 8 6 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 5 16 0 0 0 47 8 0 0 0 0 6
Cr 0 0 0 0 0 0 0 0 4 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
R 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
не используется 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
CBt Cd Cr Cr / R Crt H1 Oi R Rt
А 0 0 0 0 0 0 0 0 0
БАТ 0 0 0 0 0 0 0 0 0
Bt1 0 0 0 0 0 0 0 0 0
Bt2 6 1 0 0 0 0 0 0 0
Кр 0 0 49 0 20 0 0 0 0
К 0 0 0 1 0 0 0 41 1
не используется 0 0 0 0 0 1 24 0 0
> сводка (h [, vars])
genhz глина total_frags_pct phfield effclass
А: 113 мин. : 10.00 мин. : 0.00 Мин. : 4.90 очень слабая: 0
Бат: 40 1-я четверть: 18.00 1-я четверть: 0,00 1-я четверть: 6.00 легкая: 0
Bt1: 208 Медиана: 22,00 Медиана: 5,00 Медиана: 6,30 сильных: 0
Bt2: 116 Среднее значение: 23,67 Среднее значение: 14,18 Среднее значение: 6,18 Жестокое: 0
Кр: 75 3-я четверть: 28.00 3-я четверть:20.00 3-я четверть: 6,50 нет: 86
R: 48 Макс. : 60.00 Макс. : 95.00 Макс. : 7.00 NA: 540
не используется: 26 NA: 173 NA: 381
> sort (уникальный (h $ hzname))
[1] «2BCt» «2Bt1» «2Bt2» «2Bt3» «2Bt4» «2Bt5» «2CB» «2CBt» «2Cr» «2Crt» «2R» «A» «A1» «A2» «AB» «ABt "" Ad "" Ap "" B "
[20] «BA» «BAt» «BC» «BCt» «Bt» «Bt1» «Bt2» «Bt3» «Bt4» «Bw» «Bw1» «Bw2» «Bw3» «C» «CBt» «Cd "" Cr "" Cr / R "" Crt "
[39] «H1» «Oi» «R» «Rt»
Теперь приступим к EDA.
Описательная статистика в EDA
Для описательной статистики , чтобы выполнить EDA в R, мы разделим все функции на следующие категории:
- Меры центральной тенденции
- Меры рассеивания
- Корреляция
Мы попытаемся определить средние значения, используя функции из раздела Меры центральной тенденции . В этом разделе мы будем вычислять среднее значение, медианное значение, моду и частоту .
Пример 1:
Теперь посмотрим на меры центральной тенденции в этом примере.
р
# EDA# Descriptive Statistics# Measures of Central Tendency #loading the required packageslibrary (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and# add to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing# of the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) # first remove missing values# and create a new vectorclay <- na.exclude (h$clay) mean (clay)median (clay)sort ( table ( round (h$clay)), decreasing = TRUE )[1]table (h$genhz)# append the table with# row and column sumsaddmargins ( table (h$genhz, h$texcl)) # calculate the proportions# relative to the rows, margin = 1# calculates for rows, margin = 2 calculates# for columns, margin = NULL calculates# for total observationsround ( prop.table ( table (h$genhz, h$texture_class), margin = 1) * 100)knitr:: kable ( addmargins ( table (h$genhz, h$texcl))) aggregate (clay ~ genhz, data = h, mean)aggregate (clay ~ genhz, data = h, median)aggregate (clay ~ genhz, data = h, summary) |
Выход:
> среднее (глина)
[1] 23,6713
> медиана (глина)
[1] 22
> sort (table (round (h $ Clay)), по убыванию = ИСТИНА) [1]
25
41 год
> таблица (h $ genhz)
A BAt Bt1 Bt2 Cr R не используется
113 40 208 116 75 48 26
> addmargins (таблица (h $ genhz, h $ texcl))
cos s fs vfs lcos ls lfs lvfs cosl sl fsl vfsl l sil si scl cl sicl sc sic c Sum
А 0 0 0 0 0 0 0 0 0 6 0 0 78 27 0 0 0 0 0 0 0 111
BAt 0 0 0 0 0 0 0 0 0 1 0 0 31 4 0 0 2 1 0 0 0 39
Bt1 0 0 0 0 0 0 0 0 0 1 0 0 125 20 0 4 46 5 0 1 2 204
Bt2 0 0 0 0 0 0 0 0 0 0 0 0 28 5 0 5 52 3 0 1 16110
Cr 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1
R 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
не используется 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1
Сумма 0 0 0 0 0 0 0 0 0 8 0 0 262 56 0 9 101 9 0 2 19 466
> round (prop.table (table (h $ genhz, h $ texture_class), margin = 1) * 100)
br c cb cl gr l pg scl sic sicl sil sl spm
А 0 0 0 0 0 70 0 0 0 0 24 5 0
БАТ 0 0 0 5 0 79 0 0 0 3 10 3 0
Bt1 0 1 0 23 0 61 0 2 0 2 10 0 0
Bt2 0 14 1 46 2 25 1 4 1 3 4 0 0
Cr 98 2 0 0 0 0 0 0 0 0 0 0 0
Р 100 0 0 0 0 0 0 0 0 0 0 0 0
не используется 0 0 0 4 0 0 0 0 0 0 0 0 96
> knitr :: kable (addmargins (table (h $ genhz, h $ texcl)))
| | cos | s | fs | vfs | lcos | ls | lfs | lvfs | cosl | sl | fsl | vfsl | л | сил | си | scl | cl | sicl | sc | sic | c | Сумма |
|: -------- | ---: | -: | -: | ---: | ----: | -: | ---: | ----: | ----: | -: | ---: | ----: | ---: | ---: | -: | ---: | ---: | ----: | -: | ---: | -: | ---: |
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 78 | 27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 111 |
| BAt | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 31 | 4 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 39 |
| Bt1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 125 | 20 | 0 | 4 | 46 | 5 | 0 | 1 | 2 | 204 |
| Bt2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 | 5 | 0 | 5 | 52 | 3 | 0 | 1 | 16 | 110 |
| Cr | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| R | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| неиспользованный | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| Сумма | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 262 | 56 | 0 | 9 | 101 | 9 | 0 | 2 | 19 | 466 |
> агрегат (глина ~ genhz, данные = h, среднее)
глина
1 А 16.23113
2 бат 19.53889
3 BT1 24.14221
4 BT2 31.35045
5 Кр 15.00000
> агрегат (глина ~ genhz, данные = h, медиана)
глина
1 А 16,0
2 бат 19,5
3 BT1 24,0
4 Бат2 30,0
5 Кр 15.0
> агрегат (глина ~ genhz, данные = h, сводка)
глина глина. глина. 1 кв. глина. средн. глина. средн. глина. 3-й кв. глина. макс.
1 А 10.00000 14.00000 16.00000 16.23113 18.00000 25.00000
2 бат 14.00000 17.00000 19.50000 19.53889 20.00000 28.00000
3 бат1 12.00000 20.00000 24.00000 24.14221 28.00000 51.40000
4 BT2 10.00000 26.00000 30.00000 31.35045 35.00000 60.00000
5 Кр 15.00000 15.00000 15.00000 15.00000 15.00000 15.00000
Теперь мы увидим функции в разделе « Меры дисперсии» . В этой категории мы собираемся определить значения спреда вокруг средней точки. Здесь мы собираемся вычислить дисперсию, стандартное отклонение, диапазон, межквартильный диапазон, коэффициент дисперсии и квартили.
Пример 2:
В этом примере мы увидим меры дисперсии.
р
# EDA# Descriptive Statistics# Measures of Dispersion # loading the packageslibrary (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and add# to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing of# the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) # first remove missing values# and create a new vectorclay <- na.exclude (h$clay)var (h$clay, na.rm= TRUE )sd (h$clay, na.rm = TRUE )cv <- sd (clay) / mean (clay) * 100cvquantile (clay)range (clay)IQR (clay) |
Выход:
> var (h $ Clay, na.rm = ИСТИНА) [1] 64,89187 > sd (h $ Clay, na.rm = ИСТИНА) [1] 8,055549 > резюме [1] 34,03087 > квантиль (глина) 0% 25% 50% 75% 100% 10 18 22 28 60 > ассортимент (глина) [1] 10 60 > IQR (глина) [1] 10
Теперь займемся корреляцией . В этой части все рассчитанные значения коэффициентов корреляции всех переменных в виде таблицы корреляции. Это дает нам количественную меру, чтобы направлять наш процесс принятия решений.
Пример 3:
Теперь мы увидим корреляцию в этом примере.
р
# EDA# Decriptive Statistics# Correlation # loading the required packageslibrary (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and add# to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing# of the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) # first remove missing values# and create a new vectorclay <- na.exclude (h$clay) # Compute the middle horizon depthh$hzdepm <- (h$hzdepb + h$hzdept) / 2vars <- c ( "hzdepm" , "clay" , "sand" , "total_frags_pct" , "phfield" )round ( cor (h[, vars], use = "complete.obs" ), 2) |
Выход:
hzdepm глиняный песок total_frags_pct phfield hzdepm 1,00 0,59 -0,08 0,50 -0,03 глина 0,59 1,00 -0,17 0,28 0,13 песок -0,08 -0,17 1,00 -0,05 0,12 total_frags_pct 0,50 0,28 -0,05 1,00 -0,16 phfield -0,03 0,13 0,12 -0,16 1,00
Следовательно, вышеупомянутые три классификации относятся к части описательной статистики EDA. Теперь перейдем к графическому методу представления EDA.
Графический метод в EDA
Поскольку мы уже проверили наши данные на наличие пропущенных значений, явных ошибок и опечаток, теперь мы можем проверить наши данные графически, чтобы выполнить EDA. Мы увидим графическое представление в следующих категориях:
- Распределения
- Точечный и линейный график
В разделе « Распределение» мы будем исследовать наши данные, используя гистограмму, гистограмму, кривую плотности, прямоугольные диаграммы и график QQ.
Пример 1:
Мы увидим, как в этом примере можно использовать графы распределения для исследования данных в EDA.
р
# EDA Graphical Method Distributions # loading the required packageslibrary ( "ggplot2" )library (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and add# to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing# of the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) # graphs# bar plotggplot (h, aes (x = texcl)) + geom_bar () # histogramggplot (h, aes (x = clay)) + geom_histogram (bins = nclass.Sturges (h$clay)) # density curveggplot (h, aes (x = clay)) + geom_density () # box plotggplot (h, ( aes (x = genhz, y = clay))) +geom_boxplot () # QQ Plot for Clayggplot (h, aes (sample = clay)) +geom_qq () +geom_qq_line () |
Выход:
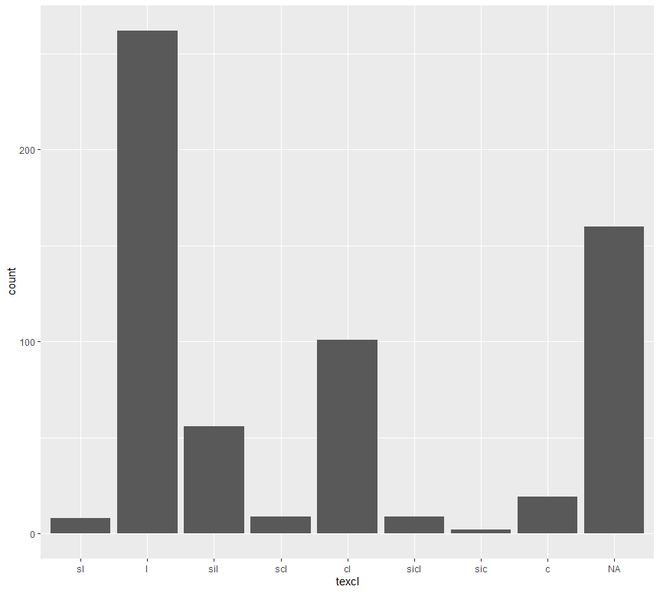
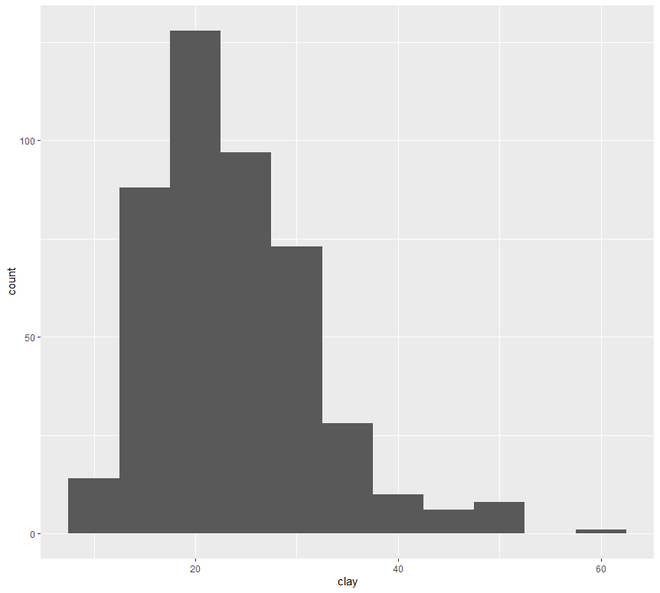
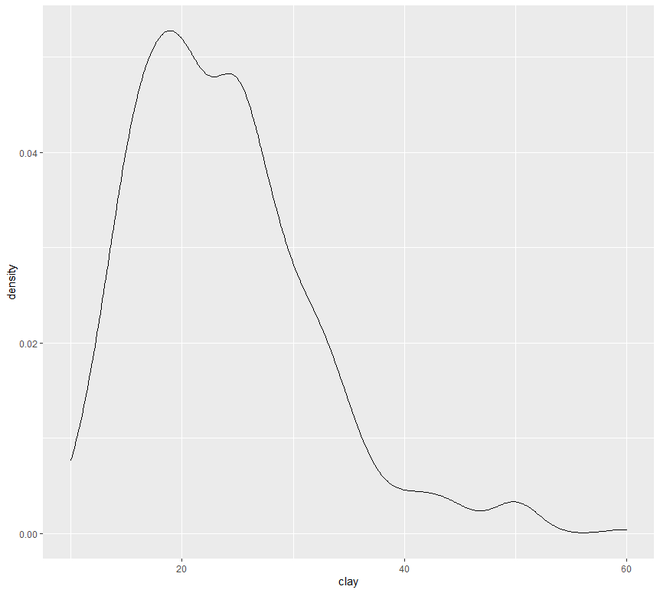
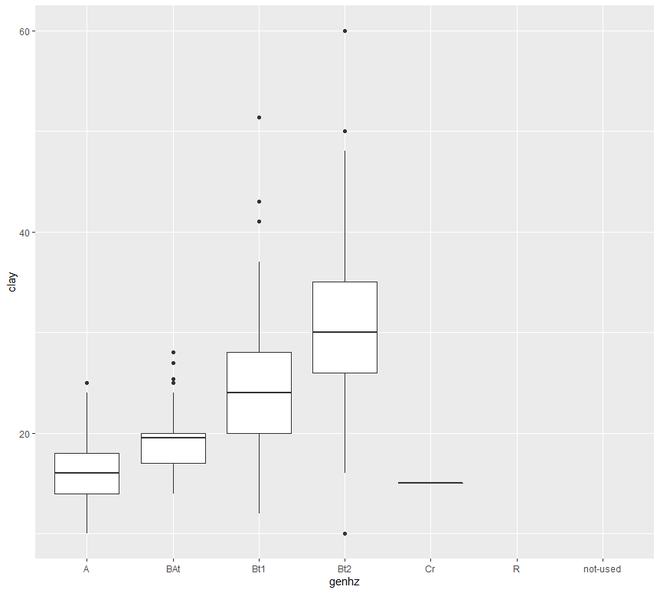
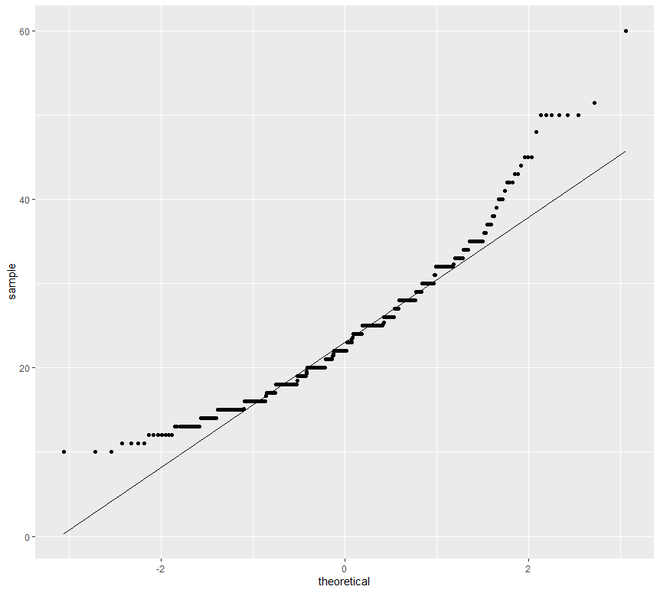
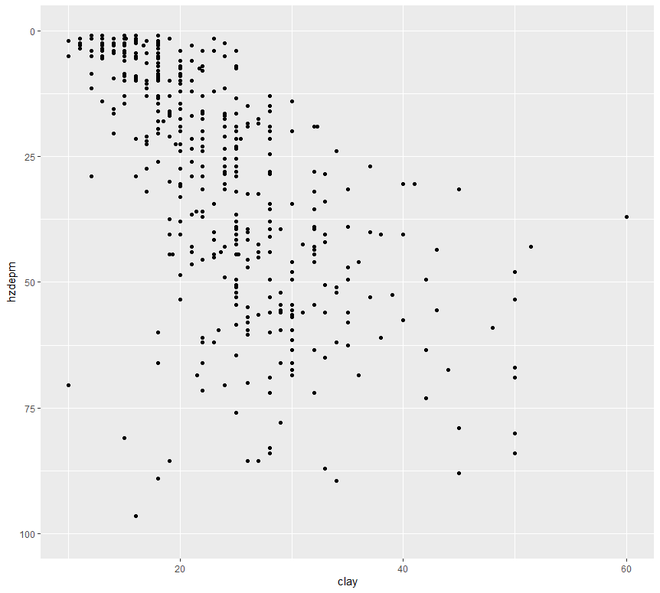
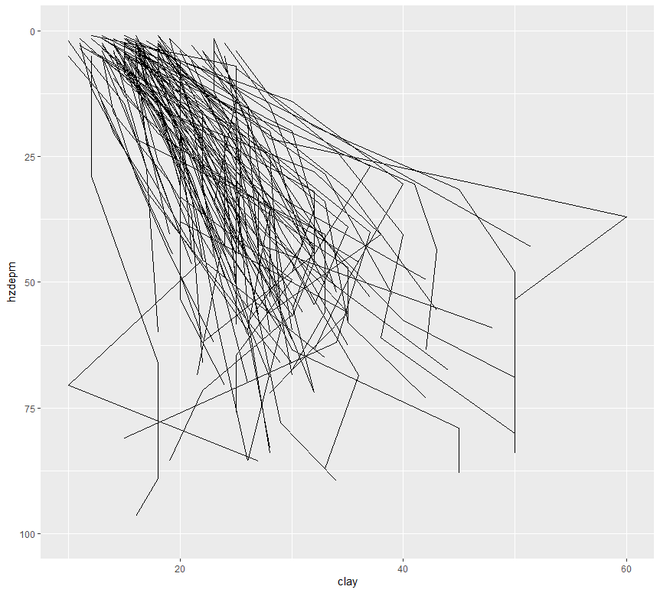
Теперь перейдем к графику разброса и линий . В этой категории мы увидим два типа построения графиков - точечный график и линейный график. Отображение точек одного интервала или переменной отношения по отношению к переменной известно как диаграмма рассеяния.
Пример 2:
Теперь мы увидим, как использовать точечные и линейные графики для проверки наших данных.
р
# EDA# Graphical Method# Scatter and Line plot # loading the required packageslibrary ( "ggplot2" )library (aqp)library (soilDB) # Load from the the loakercreek datasetdata ( "loafercreek" ) # Construct generalized horizon designationsn <- c ( "A" , "BAt" , "Bt1" , "Bt2" , "Cr" , "R" ) # REGEX rulesp <- c ( "A" , "BA|AB" , "Bt|Bw" , "Bt3|Bt4|2B|C" , "Cr" , "R" ) # Compute genhz labels and add# to loafercreek datasetloafercreek$genhz <- generalize.hz ( loafercreek$hzname, n, p) # Extract the horizon tableh <- horizons (loafercreek) # Examine the matching of pairing# of the genhz label to the hznamestable (h$genhz, h$hzname) vars <- c ( "genhz" , "clay" , "total_frags_pct" , "phfield" , "effclass" )summary (h[, vars]) sort ( unique (h$hzname))h$hzname <- ifelse (h$hzname == "BT" , "Bt" , h$hzname) # graph# scatter plotggplot (h, aes (x = clay, y = hzdepm)) + geom_point () + ylim (100, 0) # line plotggplot (h, aes (y = clay, x = hzdepm, group = peiid)) +geom_line () + coord_flip () + xlim (100, 0) |
Выход: