GAN со сверхвысоким разрешением (SRGAN)
SRGAN был предложен исследователями Twitter. Мотив этой архитектуры состоит в том, чтобы восстановить более тонкие текстуры из изображения, когда мы масштабируем его, чтобы качество не могло быть снижено. Существуют и другие методы, такие как билинейная интерполяция, которые можно использовать для выполнения этой задачи, но они страдают от потери и сглаживания информации об изображении. В этой статье авторы предложили две архитектуры: одну без GAN (SRResNet) и одну с GAN (SRGAN). Сделан вывод, что SRGAN имеет лучшую точность и более приятное для глаз изображение по сравнению с SRGAN.
Архитектура: Подобно архитектурам GAN, GAN со сверхвысоким разрешением также содержит две части: генератор и дискриминатор, где генератор выдает некоторые данные на основе распределения вероятностей, а дискриминатор пытается угадать данные о погоде, поступающие из входного набора данных или генератора. Генератор пытается оптимизировать сгенерированные данные, чтобы обмануть дискриминатор. Ниже приведены детали архитектуры генератора и дискриминатора:
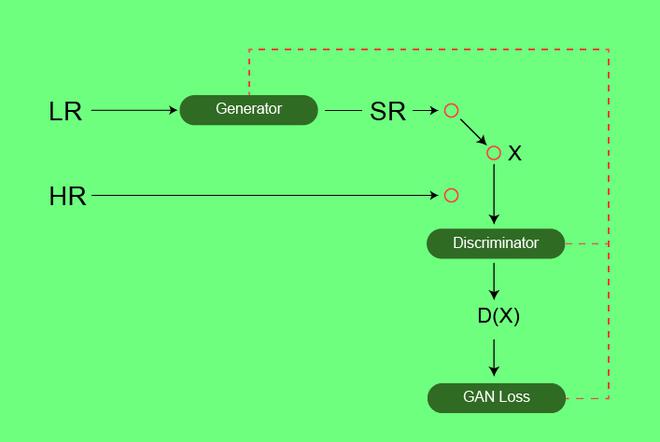
Архитектура SR-GAN
Генераторная архитектура:
Архитектура генератора содержит остаточную сеть вместо сетей с глубокой сверткой, потому что остаточные сети легко обучать и позволяют им быть значительно глубже для получения лучших результатов. Это связано с тем, что остаточная сеть использовала тип соединений, называемый пропускаемыми соединениями.
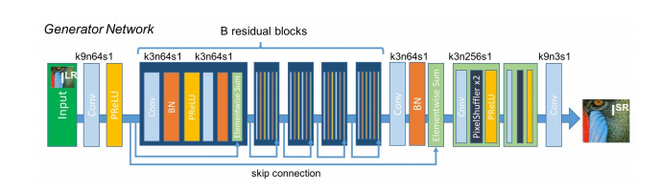
Есть B остаточных блоков (16), созданных ResNet. В остаточном блоке используются два сверточных слоя с небольшими ядрами 3x3 и 64 характеристическими картами, за которыми следуют слои пакетной нормализации и ParametricReLU в качестве функции активации.
Разрешение входного изображения увеличивается за счет двух обученных слоев свертки подпикселей.
Эта архитектура генератора также использует параметрическое ReLU в качестве функции активации, которая вместо использования фиксированного значения для параметра выпрямителя (альфа), такого как LeakyReLU. Он адаптивно изучает параметры выпрямителя и повышает точность при незначительных дополнительных вычислительных затратах.
Во время обучения изображение с высоким разрешением (HR) субдискретизируется до изображения с низким разрешением (LR). Затем архитектура генератора пытается повысить разрешение изображения с низкого до сверхвысокого разрешения. После этого изображение передается в дискриминатор, дискриминатор и пытается различить изображение со сверхвысоким разрешением и изображением с высоким разрешением и генерировать состязательные потери, которые затем передаются в архитектуру генератора.
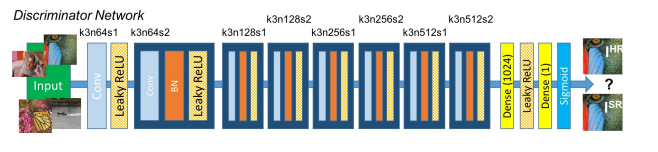
Архитектура дискриминатора:
Задача дискриминатора - различать реальные изображения HR и сгенерированные изображения SR. Архитектура дискриминатора, используемая в этой статье, аналогична архитектуре DC-GAN с LeakyReLU в качестве активации. Сеть содержит восемь сверточных слоев с ядрами фильтров 3 × 3, увеличиваясь в 2 раза с 64 до 512 ядер. Строчные свертки используются для уменьшения разрешения изображения каждый раз, когда количество функций удваивается. Полученные в результате 512 карт признаков сопровождаются двумя плотными слоями, и между ними применяется утечка ReLU, а также последняя функция активации сигмоида для получения вероятности классификации выборки.
Функция потери:
SRGAN использует функцию перпективных потерь (L SR ), которая представляет собой взвешенную сумму двух компонентов потерь: потери контента и состязательной потери. Эта потеря очень важна для производительности архитектуры генератора:
- Потеря контента: в этой статье мы используем два типа потери контента: пиксельная потеря MSE для архитектуры SRResnet, которая является наиболее распространенной потерей MSE для изображения со сверхвысоким разрешением. Однако потеря MSE не может справиться с высокочастотным содержимым изображения, которое привело к получению чрезмерно гладких изображений. Поэтому авторы статьи решили использовать потери различных слоев ВГГ. Эта потеря VGG основана на уровнях активации ReLU предварительно обученной 19-уровневой сети VGG. Эта потеря определяется следующим образом:
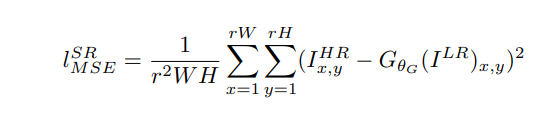
Простая потеря контента
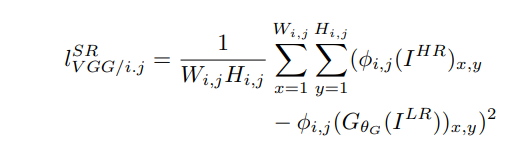
Потеря содержимого VGG
- Состязательная потеря : Состязательная потеря - это функция потерь, которая заставляет генератор создавать изображение, более похожее на изображение с высоким разрешением, с помощью дискриминатора, который обучен различать изображения с высоким и сверхвысоким разрешением.
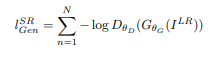
- Следовательно, общая потеря контента этой архитектуры будет:
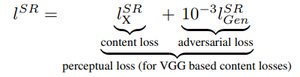
Полученные результаты:
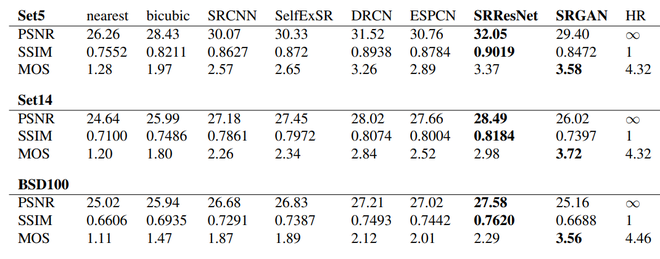
Авторы выполнили эксперименты с тремя широко используемыми наборами данных тестов, известными как Набор 5, Набор 14 и BSD 100. Эти эксперименты выполнялись с 4-кратным увеличением выборки как строк, так и столбцов.
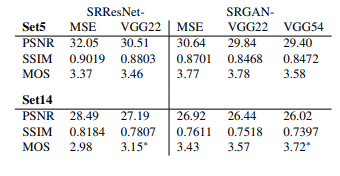
В приведенном выше слое MSE означает, что мы принимаем простую среднеквадратичную ошибку пикселя как потерю контента, VGG22 указывает карту характеристик, полученную посредством 2-й свертки (после активации) перед 2-м уровнем максимального объединения в сети VGG19, и мы вычисляем потерю VGG, используя формулу, описанную выше. . Таким образом, эта потеря является потерей для низкоуровневых функций. Аналогичным образом VGG 54 использует потери, рассчитанные на карте характеристик, полученной в результате 4-й свертки (после активации) перед 5-м слоем maxpooling в сети VGG19. Это представляет собой потерю функций более высокого уровня из более глубоких сетевых слоев с большим потенциалом сосредоточиться на содержании изображений.
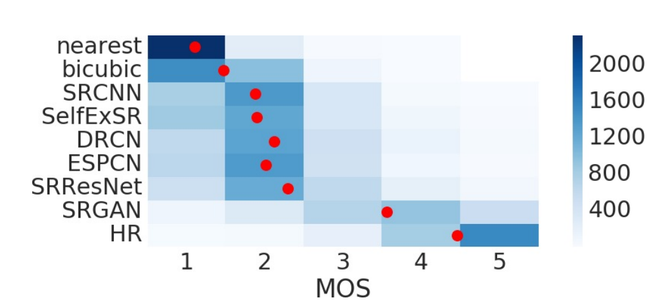
На изображении выше показаны оценки MOS на BSD100 dat.
множество. Для каждого метода было оценено 2600 образцов (100 изображений × 26 оценщиков). Среднее значение показано красным маркером, где ячейки сосредоточены вокруг значения i.
Основные статьи этой статьи:
- В этой статье приводятся современные результаты по передискретизации (4x), измеренные с помощью PNSR (пикового отношения сигнал / шум) и SSIM (структурного сходства) с 16-блочной сетью SRResNet, оптимизированной для MSE.
- Авторы предлагают новый GAN со сверхвысоким разрешением, в котором авторы заменяют потерю контента на основе MSE потерями, рассчитанными на уровне VGG.
- SRGAN смог получить самые современные результаты, которые автор подтвердил с помощью обширного теста Mean Opinion Score (MOS) на трех общедоступных наборах данных.
Ссылки :
- Бумага SRGAN