Экосистема Hadoop
Обзор: Apache Hadoop - это среда с открытым исходным кодом, предназначенная для упрощения взаимодействия с большими данными. Однако у тех, кто не знаком с этой технологией, возникает один вопрос: что такое большие данные? Большие данные - это термин для наборов данных, которые не могут быть эффективно обработаны с помощью традиционной методологии, такой как СУБД. Hadoop нашел свое место в отраслях и компаниях, которым необходимо работать с большими наборами данных, которые являются конфиденциальными и требуют эффективной обработки. Hadoop - это платформа, которая позволяет обрабатывать большие наборы данных, которые находятся в форме кластеров. Как фреймворк, Hadoop состоит из нескольких модулей, которые поддерживаются большой экосистемой технологий.
Введение: Hadoop Ecosystem - это платформа или пакет, который предоставляет различные услуги для решения проблем с большими данными. Он включает в себя проекты Apache и различные коммерческие инструменты и решения. Hadoop состоит из четырех основных элементов: HDFS , MapReduce , YARN и Hadoop Common . Большинство инструментов или решений используются для дополнения или поддержки этих основных элементов. Все эти инструменты работают вместе, чтобы предоставлять такие услуги, как поглощение, анализ, хранение и обслуживание данных и т. Д.
Ниже приведены компоненты, которые вместе образуют экосистему Hadoop:
- HDFS: Распределенная файловая система Hadoop
- ПРЯЖКА: еще один посредник в переговорах о ресурсах
- MapReduce: обработка данных на основе программирования
- Spark: обработка данных в памяти
- PIG, HIVE: обработка данных на основе запросов.
- HBase: база данных NoSQL
- Mahout, Spark MLLib: библиотеки алгоритмов машинного обучения
- Solar, Lucene: поиск и индексирование
- Zookeeper: Управление кластером
- Oozie: Расписание работы
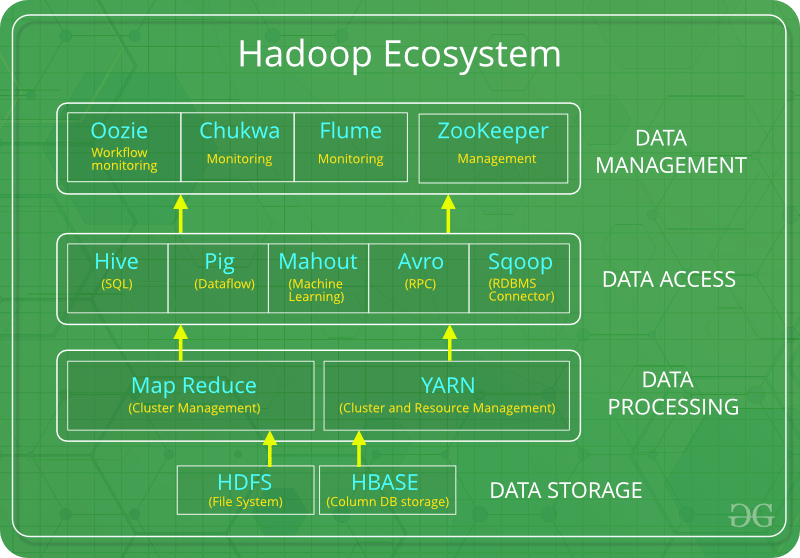
Примечание. Помимо вышеупомянутых компонентов, есть также много других компонентов, которые являются частью экосистемы Hadoop.
Все эти инструменты или компоненты вращаются вокруг одного термина, то есть данных . Преимущество Hadoop в том, что он вращается вокруг данных и, следовательно, упрощает их синтез.
HDFS:
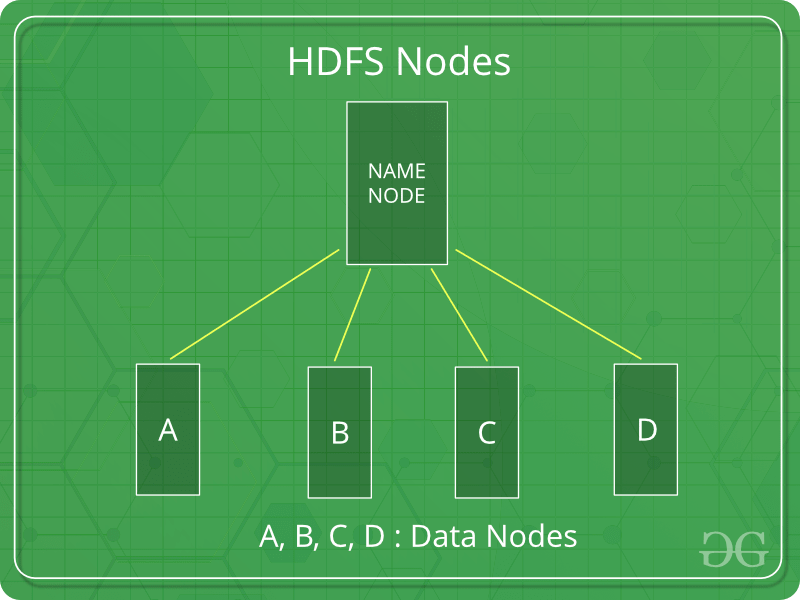
- HDFS является основным или основным компонентом экосистемы Hadoop и отвечает за хранение больших наборов структурированных или неструктурированных данных на различных узлах и, таким образом, поддерживает метаданные в форме файлов журналов.
- HDFS состоит из двух основных компонентов, т. Е.
- Имя узла
- Узел данных
- Узел имени - это основной узел, который содержит метаданные (данные о данных), требующий сравнительно меньше ресурсов, чем узлы данных, в которых хранятся фактические данные. Эти узлы данных представляют собой обычное оборудование в распределенной среде. Несомненно, это делает Hadoop рентабельным.
- HDFS поддерживает всю координацию между кластерами и оборудованием, таким образом работая в центре системы.
ПРЯЖА:
- Еще один посредник по согласованию ресурсов, как следует из названия, YARN - это тот, кто помогает управлять ресурсами в кластерах. Короче говоря, он выполняет планирование и распределение ресурсов для системы Hadoop.
- Состоит из трех основных компонентов, т. Е.
- Менеджер ресурсов
- Диспетчер узлов
- Менеджер приложений
- Диспетчер ресурсов имеет право выделять ресурсы для приложений в системе, тогда как диспетчеры узлов работают над распределением ресурсов, таких как ЦП, память, пропускная способность на машину, а затем подтверждает диспетчер ресурсов. Диспетчер приложений работает как интерфейс между диспетчером ресурсов и диспетчером узлов и выполняет согласование в соответствии с требованиями обоих.
Уменьшение карты:
- Используя распределенные и параллельные алгоритмы, MapReduce позволяет переносить логику обработки и помогает писать приложения, которые преобразуют большие наборы данных в управляемые.
- MapReduce использует две функции, то есть
Map()иReduce(), задача которых:- Map () выполняет сортировку и фильтрацию данных и тем самым организует их в виде группы. Карта генерирует результат на основе пары ключ-значение, который позже обрабатывается методом Reduce ().
- Reduce () , как следует из названия, выполняет суммирование путем агрегирования сопоставленных данных. Проще говоря, Reduce () принимает выходные данные, сгенерированные Map (), в качестве входных данных и объединяет эти кортежи в меньший набор кортежей.
СВИНЬЯ:
- Pig был в основном разработан Yahoo, который работает на латинском языке свиньи, который является языком на основе запросов, похожим на SQL.
- Это платформа для структурирования потока данных, обработки и анализа огромных наборов данных.
- Pig выполняет работу по выполнению команд, а в фоновом режиме заботятся обо всех действиях MapReduce. После обработки pig сохраняет результат в HDFS.
- Язык Pig Latin специально разработан для этого фреймворка, работающего в среде Pig Runtime. Так же, как Java работает на JVM.
- Pig помогает добиться простоты программирования и оптимизации и, следовательно, является основным сегментом экосистемы Hadoop.
УЛЕЙ:
- С помощью методологии и интерфейса SQL HIVE выполняет чтение и запись больших наборов данных. Однако его язык запросов называется HQL (Hive Query Language).
- Он обладает высокой масштабируемостью, поскольку позволяет обрабатывать как в реальном времени, так и пакетную обработку. Кроме того, Hive поддерживает все типы данных SQL, что упрощает обработку запросов.
- Подобно средам обработки запросов, HIVE также имеет два компонента: драйверы JDBC и командную строку HIVE .
- JDBC вместе с драйверами ODBC работают над установкой разрешений на хранение данных и подключением, тогда как командная строка HIVE помогает в обработке запросов.
Mahout:
- Mahout, обеспечивает машинное обучение системе или приложению. Машинное обучение, как следует из названия, помогает системе развиваться на основе некоторых шаблонов, взаимодействия пользователя с окружающей средой или на основе алгоритмов.
- Он предоставляет различные библиотеки или функции, такие как совместная фильтрация, кластеризация и классификация, которые являются не чем иным, как концепциями машинного обучения. Он позволяет вызывать алгоритмы в соответствии с нашими потребностями с помощью собственных библиотек.
Apache Spark:
- Это платформа, которая обрабатывает все ресурсоемкие задачи, такие как пакетная обработка, интерактивная или итеративная обработка в реальном времени, преобразование графиков, визуализация и т. Д.
- Следовательно, он потребляет ресурсы памяти и, следовательно, быстрее, чем предыдущий с точки зрения оптимизации.
- Spark лучше всего подходит для данных в реальном времени, тогда как Hadoop лучше всего подходит для структурированных данных или пакетной обработки, поэтому оба используются в большинстве компаний взаимозаменяемо.
Apache HBase:
- Это база данных NoSQL, которая поддерживает все виды данных и, таким образом, способна обрабатывать все, что есть в базе данных Hadoop. Он предоставляет возможности Google BigTable, что позволяет эффективно работать с наборами больших данных.
- Иногда, когда нам нужно найти или получить вхождения чего-то небольшого в огромной базе данных, запрос должен быть обработан в течение короткого промежутка времени. В таких случаях HBase может пригодиться, поскольку дает нам терпимый способ хранения ограниченного объема данных.
Другие компоненты: помимо всего этого, есть еще несколько компонентов, которые выполняют огромную задачу, чтобы сделать Hadoop способным обрабатывать большие наборы данных. Вот они:
- Solr, Lucene: это две службы, которые выполняют задачу поиска и индексации с помощью некоторых java-библиотек, особенно Lucene основана на Java, которая также поддерживает механизм проверки орфографии. Однако Lucene управляется Solr.
- Zookeeper: возникла огромная проблема управления координацией и синхронизацией между ресурсами или компонентами Hadoop, которая часто приводила к несогласованности. Zookeeper преодолел все проблемы, выполнив синхронизацию, межкомпонентную связь, группировку и обслуживание.
- Oozie: Oozie просто выполняет задачу планировщика, таким образом составляя расписание заданий и связывая их вместе как единое целое. Существует два типа рабочих мест:
Oozie workflowOozie иOozie coordinator jobs. Рабочий процесс Oozie - это задания, которые необходимо выполнять в последовательно упорядоченном порядке, тогда как задания Oozie Coordinator - это те, которые запускаются, когда ему передаются некоторые данные или внешний стимул.