Архитектура системы: Служба сокращения URL-адресов
Создание службы сокращения URL-адресов - один из часто задаваемых вопросов в ходе собеседований при проектировании системы. Вам нужно будет рассказать о своем подходе к разработке этой услуги в течение ограниченного периода времени ( 45 минут или меньше ). Многие кандидаты боятся этого раунда больше, чем раунда кодирования, потому что они не понимают, какие темы и компромиссы им следует охватить в течение этого ограниченного периода времени. Во-первых, помните, что раунд разработки системы является чрезвычайно открытым и не существует такого понятия, как стандартный ответ. Даже по одному и тому же вопросу у вас будет совершенно другое обсуждение с разными интервьюерами.

В этом блоге мы обсудим, как разработать службу сокращения URL-адресов, но прежде чем мы продолжим, мы хотим, чтобы вы прочитали статью «Как взломать этап проектирования системы в интервью?». Это даст вам представление о том, как выглядит этот раунд, что от вас ожидается в этом раунде и каких ошибок следует избегать перед интервьюером.
Как бы вы разработали службу сокращения URL-адресов, такую как TinyURL?
Сервисы сокращения URL-адресов, такие как bit.ly или TinyURL, очень популярны для создания более коротких псевдонимов для длинных URL-адресов. Вам необходимо разработать такой вид веб-службы, в которой, если пользователь дает длинный URL-адрес, служба возвращает короткий URL-адрес, а если пользователь дает короткий URL-адрес, он возвращает исходный длинный URL-адрес. Например, сокращение указанного URL-адреса через TinyURL:
https://www.geeksforgeeks.org/get-your-dream-job-with-amazon-sde-test-series/?ref=leftbar-rightbar
Получаем результат, приведенный ниже
https://tinyurl.com/y7vg2xjl
Многие кандидаты могут подумать, что разработать эту услугу несложно. Когда пользователь дает длинный URL-адрес, преобразует его в короткий URL-адрес и обновляет базу данных, а когда пользователь нажимает короткий URL-адрес, затем выполняет поиск по короткому URL-адресу в базе данных, получает этот длинный URL-адрес и перенаправляет пользователя на исходный URL-адрес. Это действительно просто? Абсолютно нет, если мы думаем о масштабируемости этой услуги.
Когда вам задают этот вопрос в интервью, не сразу вдавайтесь в технические детали. Большинство кандидатов делают здесь ошибки и сразу же начинают перечислять набор инструментов, баз данных и фреймворков. В вопросе такого рода интервьюер хочет получить высокоуровневую дизайнерскую идею, в которой вы можете предложить решение для масштабируемости и долговечности услуги.
Давайте сначала поговорим о требовании ...
1. Требование
Прежде чем приступить к решению, всегда уточняйте все предположения, которые вы делаете в начале собеседования. Задавайте вопросы, чтобы определить объем системы. Это устранит первоначальные сомнения, и вы узнаете, какие конкретные детали интервьюер хочет учесть в этой услуге.
- Учитывая длинный URL-адрес, служба должна сгенерировать более короткий и уникальный псевдоним.
- Когда пользователь нажимает короткую ссылку, служба должна перенаправить на исходную ссылку.
- Ссылки истекают по истечении стандартного периода времени по умолчанию.
- Система должна быть высокодоступной. Это действительно важно учитывать, потому что, если служба выйдет из строя, все перенаправления URL-адресов начнут давать сбой.
- Перенаправление URL-адресов должно происходить в режиме реального времени с минимальной задержкой.
- Укороченные ссылки не должны быть предсказуемыми.
Начнем с некоторых предположений о трафике (для масштабируемости) и длине URL.
2. Трафик
Предположим, у нашего сервиса 30 миллионов новых сокращений URL в месяц. Предположим, мы храним каждый запрос на сокращение URL (и связанную с ним сокращенную ссылку) в течение 5 лет. За этот период сервис сгенерирует около 1,8 млрд записей.
30 миллионов * 5 лет * 12 месяцев = 1,8 млрд
3. Длина URL
Предположим, мы используем 7 символов для создания короткого URL-адреса. Эти символы представляют собой комбинацию из 62 символов [AZ, az, 0-9], что-то вроде http://ad.com/abXdef2 .
4. Моделирование емкости данных
Обсудите модель емкости данных, чтобы оценить объем хранилища системы. Нам нужно понять, сколько данных нам, возможно, придется вставить в нашу систему. Подумайте о различных столбцах или атрибутах, которые будут храниться в нашей базе данных, и рассчитайте срок хранения данных в течение пяти лет. Давайте сделаем следующее предположение для различных атрибутов…
- Рассмотрим средний размер длинного URL-адреса 2 КБ, то есть для 2048 символов.
- Размер короткого URL: 17 байт для 17 символов.
- created_at- 7 байт
- expiration_length_in_minutes -7 байт
Приведенный выше расчет даст в общей сложности 2,031 КБ на запись сокращенного URL в базе данных. Если подсчитать общий объем хранилища, то для 30 M активных пользователей общий размер = 30000000 * 2,031 = 60780000 КБ = 60,78 ГБ в месяц. В год 0,7284 ТБ и за 5 лет 3,642 ТБ данных.
Нам нужно подумать о чтениях и записях, которые будут происходить в нашей системе для этого количества данных. Это решит, какую базу данных (СУБД или NoSQL) нам нужно использовать.
5. Логика сокращения URL (кодирование)
Чтобы преобразовать длинный URL-адрес в уникальный короткий URL-адрес, мы можем использовать некоторые методы хеширования, такие как Base62 или MD5. Мы обсудим оба подхода.
Кодировка Base62: кодировщик Base62 позволяет нам использовать комбинацию символов и цифр, которая содержит AZ, az, всего 0–9 (26 + 26 + 10 = 62). Таким образом, для короткого URL-адреса из 7 символов мы можем обслужить 62 ^ 7 ~ = 3500 миллиардов URL-адресов, что вполне достаточно по сравнению с base10 (base10 содержит только числа 0-9, поэтому вы получите только 10M комбинаций). Если мы используем base62, предполагая, что служба генерирует 1000 крошечных URL-адресов в секунду, то на исчерпание этой комбинации из 3500 миллиардов потребуется 110 лет. Мы можем сгенерировать случайное число для данного длинного URL, преобразовать его в base62 и использовать хэш в качестве идентификатора короткого URL.
Python3
def to_base_62(deci): s = '012345689abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' hash_str = '' while deci > 0 : hash_str = s[deci % 62 ] + hash_str deci / = 62 return hash_str print to_base_62( 999 ) |
Кодировка MD5: MD5 также дает вывод base62, но хеш MD5 дает длинный вывод, который превышает 7 символов. Хеш MD5 генерирует 128-битный вывод, поэтому из 128-битных нам потребуется 43 бита, чтобы сгенерировать крошечный URL-адрес из 7 символов. MD5 может создавать множество коллизий. Для двух или нескольких разных входных длинных URL-адресов мы можем получить один и тот же уникальный идентификатор для короткого URL-адреса, что может вызвать повреждение данных. Поэтому нам нужно выполнить некоторые проверки, чтобы убедиться, что этот уникальный идентификатор уже не существует в базе данных.
6. База данных
Мы можем использовать СУБД, которая использует свойства ACID, но вы столкнетесь с проблемой масштабируемости с реляционными базами данных. Теперь, если вы думаете, что можете использовать сегментирование и решить проблему масштабируемости в РСУБД, это увеличит сложность системы. Есть 30 миллионов активных пользователей, поэтому будут конверсии и много разрешений и перенаправлений коротких URL-адресов. Чтение и запись будут тяжелыми для этих 30 миллионов пользователей, поэтому масштабирование СУБД с использованием сегментов увеличит сложность дизайна, когда мы хотим, чтобы наша система была распределенной. Возможно, вам придется использовать согласованное хеширование для балансировки трафика и запросов к БД в случае СУБД, а это сложный процесс. Таким образом, для обработки такого количества огромного трафика в нашей системе реляционные базы данных не подходят, и также не будет хорошим решением масштабировать РСУБД.
Теперь поговорим о NoSQL!
Единственная проблема с использованием базы данных NoSQL - ее конечная согласованность. Мы что-то пишем, и требуется некоторое время для репликации на другой узел, но нашей системе требуется высокая доступность, и NoSQL соответствует этому требованию. NoSQL легко справляется с 30 миллионами активных пользователей и легко масштабируется. Нам просто нужно продолжать добавлять узлы, когда мы хотим расширить хранилище.
Методы создания и хранения TinyURL
Техника 1.
Давайте обсудим отображение длинного URL-адреса в короткий URL-адрес в нашей базе данных. Предположим, мы генерируем Tiny URL с использованием кодировки base62, тогда нам нужно выполнить шаги, указанные ниже ...
- Крошечный URL-адрес должен быть уникальным, поэтому сначала проверьте наличие этого крошечного URL-адреса в базе данных (выполняя get (tiny) в БД). Если он уже присутствует для какого-то другого длинного URL-адреса, создайте новый короткий URL-адрес.
- Если короткий URL-адрес отсутствует в БД, поместите longURL и TinyURL в БД (поместите (TinyURL, longURL)).
Этот метод очень хорошо работает с одним сервером, но если будет несколько серверов, этот метод создаст состояние гонки. Когда несколько серверов будут работать вместе, будет вероятность того, что все они могут сгенерировать один и тот же уникальный идентификатор или один и тот же крошечный URL-адрес для разных длинных URL-адресов, и даже после проверки базы данных им будет разрешено вставлять одни и те же крошечные URL-адреса одновременно (что одинаково для разных длинных URL-адресов) в базе данных, и это может привести к повреждению данных.
Мы можем использовать условие putIfAbsent (TinyURL, длинный URL-адрес) или INSERT-IF-NOT-EXIST при вставке крошечного URL-адреса, но для этого требуется поддержка со стороны БД, которая доступна в СУБД, но не в NoSQL. В конечном итоге данные в NoSQL согласованы, поэтому поддержка функции putIfAbsent может быть недоступна в базе данных NoSQL.
Метод 2 (подход MD5)
- Закодируйте длинный URL-адрес, используя подход MD5, и возьмите только первые 7 символов для генерации TinyURL.
- Первые 7 символов могут быть одинаковыми для разных длинных URL-адресов, поэтому проверьте БД (как мы обсуждали в методике 1), чтобы убедиться, что TinyURL еще не используется.
- Преимущества: этот подход позволяет сэкономить место в базе данных, но как? Если два пользователя хотят сгенерировать крошечный URL-адрес для одного и того же длинного URL-адреса, тогда первый метод сгенерирует два случайных числа и потребует две строки в базе данных, но во втором методе оба более длинных URL-адреса будут иметь одинаковый MD5, поэтому он будет иметь те же первые 43 бита, что означает, что мы получим некоторую дедупликацию, и в итоге мы сэкономим немного места, поскольку нам нужно сохранить только одну строку вместо двух в базе данных.
MD5 экономит место в базе данных для тех же URL-адресов, но для двух длинных разных URL-адресов мы снова столкнемся с той же проблемой, что и в методе 1. Мы можем использовать putIfAbsent, но NoSQL не поддерживает эту функцию. Итак, перейдем к третьему способу решения этой проблемы.
Техника 3 (встречный подход)
Использование счетчика - хорошее решение для масштабируемого решения, потому что счетчики всегда увеличиваются, поэтому мы можем получать новое значение для каждого нового запроса.
Единый серверный подход:
- Один хост или сервер (скажем, база данных) будет нести ответственность за поддержание счетчика.
- Когда рабочий хост получает запрос, он разговаривает с хостом счетчика, который возвращает уникальный номер и увеличивает счетчик. Когда приходит следующий запрос, хост счетчика снова возвращает уникальный номер, и это продолжается.
- Каждый рабочий хост получает уникальный номер, который используется для генерации TinyURL.
Проблема: если узел счетчика выходит из строя в течение некоторого времени, это создает проблему, а также, если количество запросов будет большим, узел счетчика может не справиться с нагрузкой. Таким образом, проблемы - это единая точка отказа и единое узкое место.
А что, если серверов несколько?
Вы не можете поддерживать один счетчик и возвращать результат на все серверы. Чтобы решить эту проблему, мы можем использовать несколько внутренних счетчиков для нескольких серверов, которые используют разные диапазоны счетчиков. Например, сервер 1 находится в диапазоне от 1 до 1 Мбайт, сервер 2 - от 1 Мбайт до 10 Мбайт и так далее. Но снова мы столкнемся с проблемой, т.е. если один из счетчиков выйдет из строя, то для другого сервера будет сложно получить диапазон счетчика сбоев и поддерживать его снова. Также, если один счетчик достигает своего максимального предела, сброс счетчика будет затруднен, потому что нет единого хоста, доступного для координации между всеми этими несколькими серверами. Архитектура будет испорчена, поскольку мы не знаем, какой сервер является главным, а какой - подчиненным, и какой из них отвечает за координацию и синхронизацию.
Решение: чтобы решить эту проблему, мы можем использовать распределенный сервис Zookeeper, чтобы управлять всеми этими утомительными задачами и решать различные проблемы распределенной системы, такие как состояние гонки, тупик или частичный сбой данных. Zookeeper - это, по сути, служба распределенной координации, которая управляет большим набором хостов. Он отслеживает все вещи, такие как имена серверов, активные серверы, мертвые серверы, информацию о конфигурации всех хостов. Он обеспечивает координацию и поддерживает синхронизацию между несколькими серверами.
Давайте обсудим, как поддерживать счетчик для распределенных хостов с помощью Zookeeper.
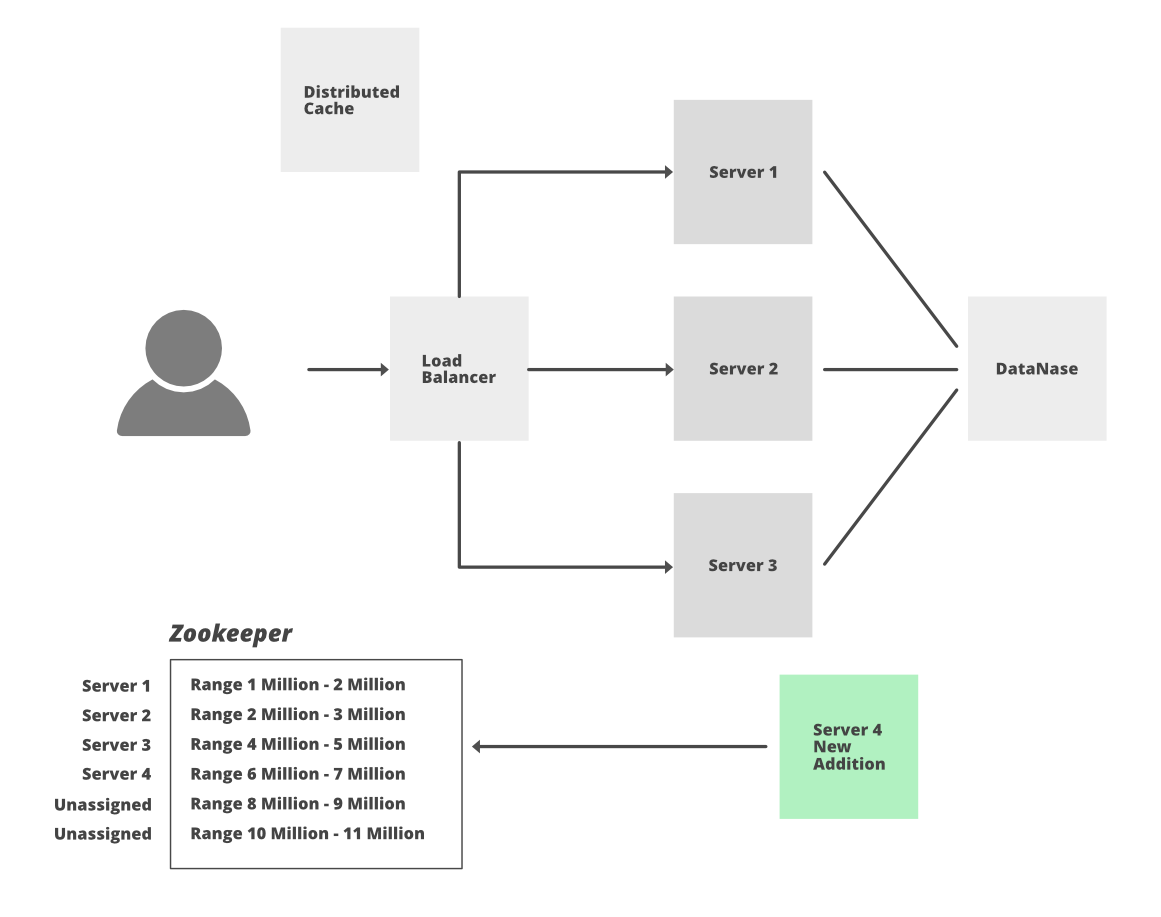
- Из 3,5 триллионов комбинаций возьмите 1 миллиард комбинаций.
- В Zookeeper поддерживайте диапазон и делите 1-й миллиард на 1000 диапазонов по 1 миллиону каждый, то есть диапазон 1 -> (1 - 1,000,000), диапазон 2 -> (1,000,001 - 2,000,000)…. диапазон 1000 -> (999,000,001 - 1,000,000,000)
- Когда серверы будут добавлены, эти серверы будут запрашивать неиспользованный диапазон у Zookeepers. Предположим, серверу W1 назначен диапазон 1, теперь W1 будет генерировать крошечный URL-адрес, увеличивая счетчик и используя технику кодирования. Каждый раз это будет уникальный номер, поэтому нет возможности коллизии, а также нет необходимости постоянно проверять БД, чтобы убедиться, существует ли URL уже или нет. Мы можем напрямую вставить отображение длинного и короткого URL в БД.
- В худшем случае, если один из серверов выйдет из строя, мы потеряем только миллион комбинаций в Zookeeper (которые не будут использоваться, и мы не сможем использовать их повторно), но, поскольку у нас есть 3,5 триллиона комбинаций, мы не должны беспокоиться о потере это сочетание.
- Если один из серверов достигнет своего максимального диапазона или предела, он снова может взять новый новый диапазон от Zookeeper.
- Добавление нового сервера также несложно. Zookeeper назначит этому новому серверу неиспользуемый диапазон счетчиков.
- Мы возьмем 2-й миллиард, когда 1-й будет исчерпан, чтобы продолжить процесс.
Вниманию читателя! Не переставай учиться сейчас. Получите все важные концепции системного дизайна с отраслевыми экспертами. Присоединяйтесь к курсу проектирования систем, чтобы посещать живые занятия.