10 лучших алгоритмов, которые должен знать каждый инженер по машинному обучению
« Компьютеры могут видеть, слышать и учиться. Добро пожаловать в будущее. ”
А будущее за машинным обучением. Согласно Forbes, патенты на машинное обучение выросли на 34% в период с 2013 по 2017 год, и в ближайшее время этот показатель будет только увеличиваться. Более того, в обзорной статье Harvard Business Data Scientist назван «Самой сексуальной работой 21 века» (и это уже стимул !!!).
В это очень динамичное время существуют различные алгоритмы машинного обучения, разработанные для решения сложных реальных проблем. Эти алгоритмы в высшей степени автоматизированы и самомодифицируются, поскольку они продолжают совершенствоваться с течением времени за счет добавления большего количества данных и с минимальным вмешательством человека. Итак, эта статья посвящена 10 лучшим алгоритмам машинного обучения .
Но для понимания этих алгоритмов сначала кратко объясняются различные типы, к которым они могут принадлежать.
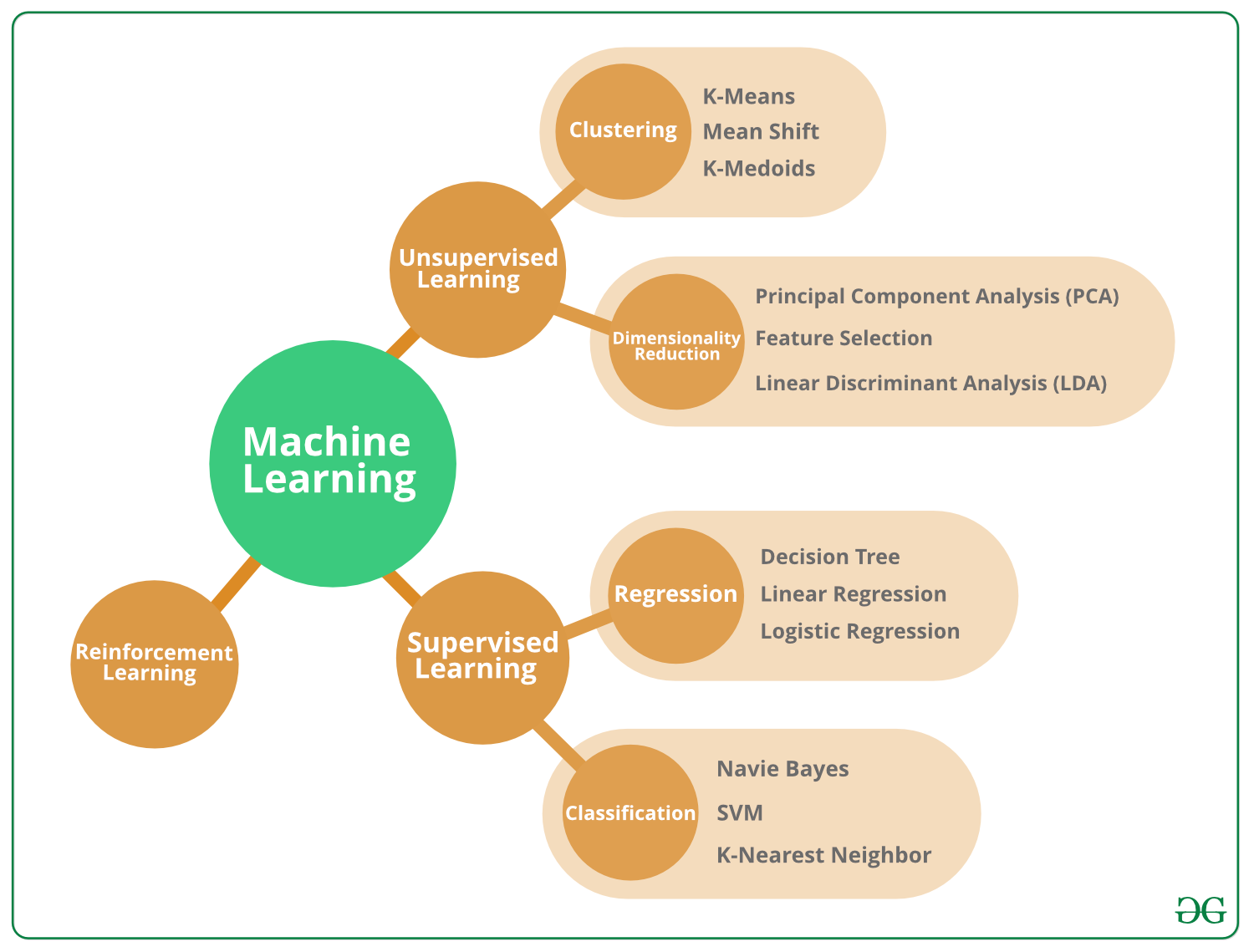
Типы алгоритмов машинного обучения -
Алгоритмы машинного обучения можно разделить на 3 различных типа, а именно:
Алгоритмы контролируемого машинного обучения:
Представьте себе учителя, руководящего классом. Учитель уже знает правильные ответы, но процесс обучения не останавливается, пока ученики тоже не выучат ответы (бедные дети!). В этом суть алгоритмов контролируемого машинного обучения. Здесь алгоритм - это ученик, который учится на тренировочном наборе данных и делает прогнозы, которые корректируются учителем. Этот процесс обучения продолжается до тех пор, пока алгоритм не достигнет требуемого уровня производительности.
Алгоритмы неконтролируемого машинного обучения:
В этом случае в классе нет учителя, и бедным ученикам остается учиться самостоятельно! Это означает, что для алгоритмов неконтролируемого машинного обучения нет конкретного ответа, который нужно изучить, и нет учителя. Алгоритм остается без присмотра, чтобы найти основную структуру в данных, чтобы узнавать все больше и больше о самих данных.
Алгоритмы машинного обучения с подкреплением:
Что ж, вот гипотетические ученики со временем учатся на собственных ошибках (это как в жизни!). Таким образом, алгоритмы машинного обучения с подкреплением изучают оптимальные действия методом проб и ошибок. Это означает, что алгоритм определяет следующее действие, изучая поведение, основанное на его текущем состоянии, и которое максимизирует вознаграждение в будущем.
Лучшие алгоритмы машинного обучения
Существуют специальные алгоритмы машинного обучения, которые были разработаны для решения сложных реальных проблем с данными. Итак, теперь, когда мы увидели типы алгоритмов машинного обучения, давайте изучим лучшие алгоритмы машинного обучения, которые существуют и фактически используются специалистами по данным.
1. Алгоритм наивного байесовского классификатора -
Что бы произошло, если бы вам пришлось классифицировать тексты данных, такие как веб-страница, документ или электронное письмо, вручную? Ну вы бы с ума сошли! Но, к счастью, эту задачу выполняет алгоритм наивного байесовского классификатора. Этот алгоритм основан на теореме вероятности Байеса (вы, вероятно, читали это в математике), и он распределяет значение элемента среди популяции из одной из доступных категорий.
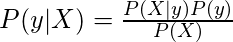
где y - переменная класса, а X - зависимый вектор признаков (размера n ), где:
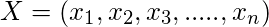
Примером использования алгоритма наивного байесовского классификатора является фильтрация спама в электронной почте. Gmail использует этот алгоритм, чтобы классифицировать электронное письмо как спам или не спам.
2. Алгоритм кластеризации K-средств -
Представим, что вы хотите выполнить поиск по слову «дата» в Википедии. Теперь «свидание» может относиться к фрукту, конкретному дню или даже романтическому вечеру с вашей любовью !!! Таким образом, Википедия группирует веб-страницы, которые говорят об одних и тех же идеях, с использованием алгоритма кластеризации K-средних (поскольку это популярный алгоритм для кластерного анализа).
Алгоритм кластеризации средств K обычно использует K кластеров для работы с заданным набором данных. Таким образом, выходные данные содержат K кластеров, причем входные данные разделены между кластерами (поскольку страницы с разными значениями «даты» были разделены).
3. Алгоритм опорной векторной машины -
Алгоритм машины опорных векторов используется для задач классификации или регрессии. При этом данные разделяются на разные классы путем нахождения определенной линии (гиперплоскости), которая разделяет набор данных на несколько классов. Алгоритм машины опорных векторов пытается найти гиперплоскость, которая максимизирует расстояние между классами (известное как максимизация маржи), поскольку это увеличивает вероятность более точной классификации данных.
Пример использования алгоритма машины опорных векторов предназначен для сравнения показателей акций в одном секторе. Это помогает финансовым учреждениям управлять инвестициями и принимать решения.
4. Алгоритм априори -
Алгоритм Apriori генерирует правила ассоциации, используя формат IF_THEN. Это означает, что ЕСЛИ происходит событие A, то событие B также произойдет с определенной вероятностью. Например: ЕСЛИ человек покупает машину, ТОГДА он также покупает автостраховку. Алгоритм Apriori генерирует это правило ассоциации, наблюдая за количеством людей, которые приобрели автостраховку после покупки автомобиля.
Пример использования алгоритма априори - автозаполнение Google. Когда слово набирается в Google, алгоритм априори ищет связанные слова, которые обычно вводятся после этого слова, и отображает возможные варианты.
5. Алгоритм линейной регрессии -
Алгоритм линейной регрессии показывает взаимосвязь между независимой и зависимой переменной. Он демонстрирует влияние на зависимую переменную, когда независимая переменная изменяется каким-либо образом. Таким образом, независимая переменная называется объясняющей переменной, а зависимая переменная - интересующим фактором.
Пример использования алгоритма линейной регрессии - для оценки рисков в сфере страхования. Анализ линейной регрессии можно использовать для определения количества претензий для клиентов разного возраста, а затем вывести повышенный риск в связи с увеличением возраста клиента.
6. Алгоритм логистической регрессии -
Алгоритм логистической регрессии работает с дискретными значениями, тогда как алгоритм линейной регрессии обрабатывает прогнозы с непрерывными значениями. Таким образом, логистическая регрессия подходит для двоичной классификации, в которой, если событие происходит, оно классифицируется как 1, а если нет, оно классифицируется как 0. Следовательно, вероятность возникновения конкретного события прогнозируется на основе заданных переменных-предикторов.
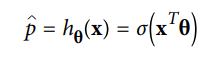
Пример использования алгоритма логистической регрессии - в политике прогнозирование того, выиграет или проиграет конкретный кандидат на политических выборах.
7. Алгоритм деревьев решений -
Предположим, вы хотите выбрать место для своего дня рождения. Итак, есть много вопросов, которые влияют на ваше решение, например: «Ресторан итальянский?», «Есть ли в ресторане живая музыка?», «Ресторан находится недалеко от вашего дома?» и т. д. На каждый из этих вопросов есть ответ ДА или НЕТ, который влияет на ваше решение.
Это то, что в основном и происходит в алгоритме деревьев решений. Здесь все возможные результаты решения показаны с использованием методологии ветвления дерева. Внутренние узлы - это тесты для различных атрибутов, ветви дерева - это результаты тестов, а конечные узлы - это решение, принятое после вычисления всех атрибутов.
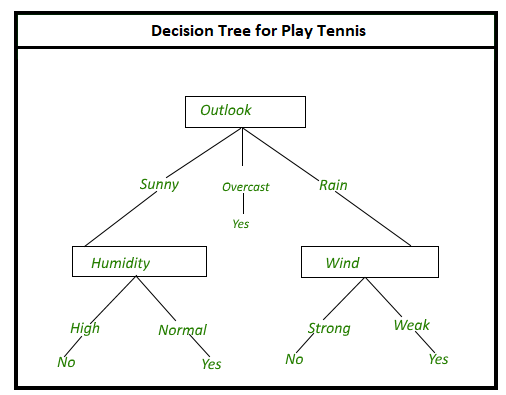
Пример использования алгоритма деревьев решений в банковской сфере для классификации соискателей ссуды по их вероятности невыполнения указанных платежей по ссуде.
8. Алгоритм случайных лесов -
Алгоритм случайных лесов обрабатывает некоторые ограничения алгоритма деревьев решений, а именно то, что точность результата уменьшается, когда количество решений в дереве увеличивается.
Итак, в алгоритме случайных лесов есть несколько деревьев решений, которые представляют различные статистические вероятности. Все эти деревья отображаются в одно дерево, известное как модель CART. (Деревья классификации и регрессии). В конце концов, окончательный прогноз для алгоритма случайных лесов получается путем опроса результатов всех деревьев решений.
Пример использования алгоритма случайных лесов в автомобильной промышленности для прогнозирования будущей поломки какой-либо конкретной детали автомобиля.
9. Алгоритм K ближайших соседей -
Алгоритм K ближайших соседей делит точки данных на разные классы на основе аналогичной меры, такой как функция расстояния. Затем делается прогноз для новой точки данных путем поиска во всем наборе данных K наиболее похожих экземпляров (соседей) и суммирования выходной переменной для этих K экземпляров. Для задач регрессии это может быть среднее значение результатов, а для задач классификации это может быть режим (наиболее частый класс).
Алгоритм K ближайших соседей может потребовать много памяти или места для хранения всех данных, но выполняет вычисления (или учится) только тогда, когда требуется прогноз, как раз вовремя.
10. Алгоритм искусственных нейронных сетей -
Человеческий мозг содержит нейроны, которые являются основой нашей удерживающей способности и острого ума (по крайней мере, для некоторых из нас!). Таким образом, искусственные нейронные сети пытаются воспроизвести нейроны в человеческом мозгу, создавая узлы, которые связаны друг с другом. Эти нейроны принимают информацию через другой нейрон, выполняют различные действия по мере необходимости, а затем передают информацию другому нейрону в качестве выходных данных.
Примером искусственных нейронных сетей является распознавание лиц человека. Изображения с человеческими лицами можно идентифицировать и отличить от изображений, не относящихся к лицу. Однако это может занять несколько часов в зависимости от количества изображений в базе данных, тогда как человеческий разум может сделать это мгновенно.